
18个月326项能力,这家大厂猛猛上新生成式AI,如今纯靠Prompt就搞定企业级应用了
18个月326项能力,这家大厂猛猛上新生成式AI,如今纯靠Prompt就搞定企业级应用了构建生成式 AI 应用,现在只需要几分钟。
来自主题: AI资讯
9702 点击 2024-07-11 20:10
 搜索
搜索
构建生成式 AI 应用,现在只需要几分钟。

近日,硅基流动完成总金额近亿元人民币的天使+轮融资,投资方包括智谱AI、360 和水木清华校友基金;创始人兼CEO袁进辉是清华计算机系博士,此前曾创立一流科技。

股神的AI投资版图

大幅节省算力资源,又又又有新解了!!
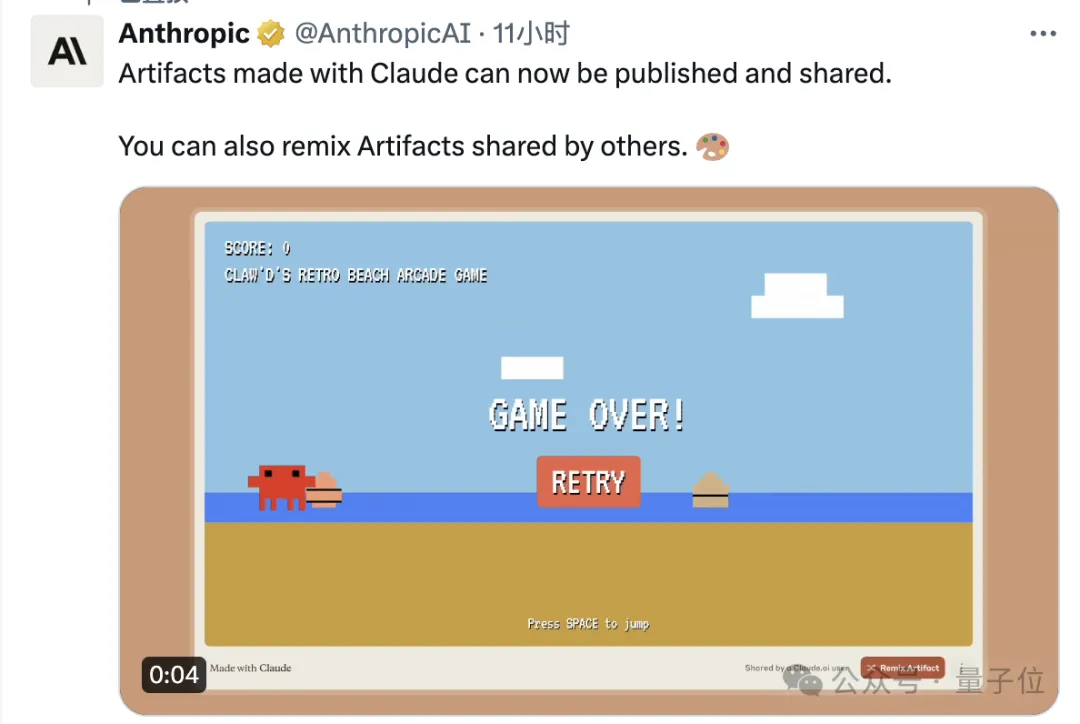
Claude 3.5上新的“工坊模式”(Artifacts)再次更新,写完的网页应用支持一键分享了!

全球首个芯片设计开源大模型SemiKong正式发布,基于Llama 3微调而来,性能超越通用大模型。未来5年,SemiKong或将重塑价值5000亿美元的半导体行业。

近期,商汤科技 - 南洋理工大学联合 AI 研究中心 S-Lab ,上海人工智能实验室,北京大学与密歇根大学联合提出 DreamGaussian4D(DG4D),通过结合空间变换的显式建模与静态 3D Gaussian Splatting(GS)技术实现高效四维内容生成。

来自佐治亚理工学院和英伟达的两名华人学者带队提出了名为RankRAG的微调框架,简化了原本需要多个模型的复杂的RAG流水线,用微调的方法交给同一个LLM完成,结果同时实现了模型在RAG任务上的性能提升。

人类采访了机器人,足足一个多小时,还是对答如流的那种!

WHO 表示,1/3 的癌症可以通过早发现、早治疗得以治愈。