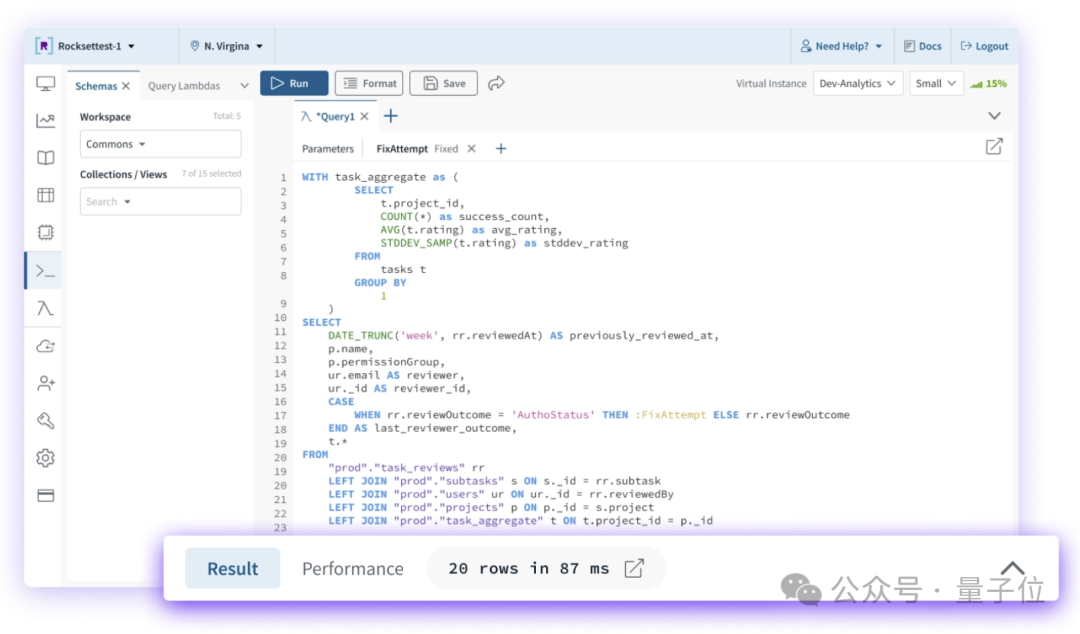
OpenAI 36亿收购数据库初创公司,CTO剧透GPT-5
OpenAI 36亿收购数据库初创公司,CTO剧透GPT-5刚刚,OpenAI收购了数据库初创公司Rockset。
来自主题: AI资讯
10422 点击 2024-06-23 12:16
 搜索
搜索
刚刚,OpenAI收购了数据库初创公司Rockset。
2013年上映的科幻电影《HER》的剧情,在十年后的现实世界有了更为具体的呈现。

在生成式模型的迅速发展中,Image Tokenization 扮演着一个很重要的角色,例如Diffusion依赖的VAE或者是Transformer依赖的VQGAN。这些Tokenizers会将图像编码至一个更为紧凑的隐空间(latent space),使得生成高分辨率图像更有效率。

OpenAI CTO Murati表示,GPT-5将在一年半后发布,在某些领域将达到博士的智能;而Claude 3.5 Sonnet,已经成为了第一个测试分数高于最聪明的人类博士的模型。当AGI进一步发展为ASI,它会因为接近神性的全知、全能、无所不在,而被人类敬奉为「新神」吗?当ASI给出一张「希特勒名单」,人类又将怎样?

OpenAI劲敌出手,追击GPT-4o。

据外媒 the Information 报道,月之暗面正在为进军美国市场做准备。据悉,月之暗面正在进行新一轮融资,估值有望达到 30 亿美元,新的投资者包括腾讯。而在今年 2 月,月之暗面才获得了由阿里领投的 10 亿美元融资,当时估值约 15 亿美元。

80%收入来自海外,酒旅服务软件出海。
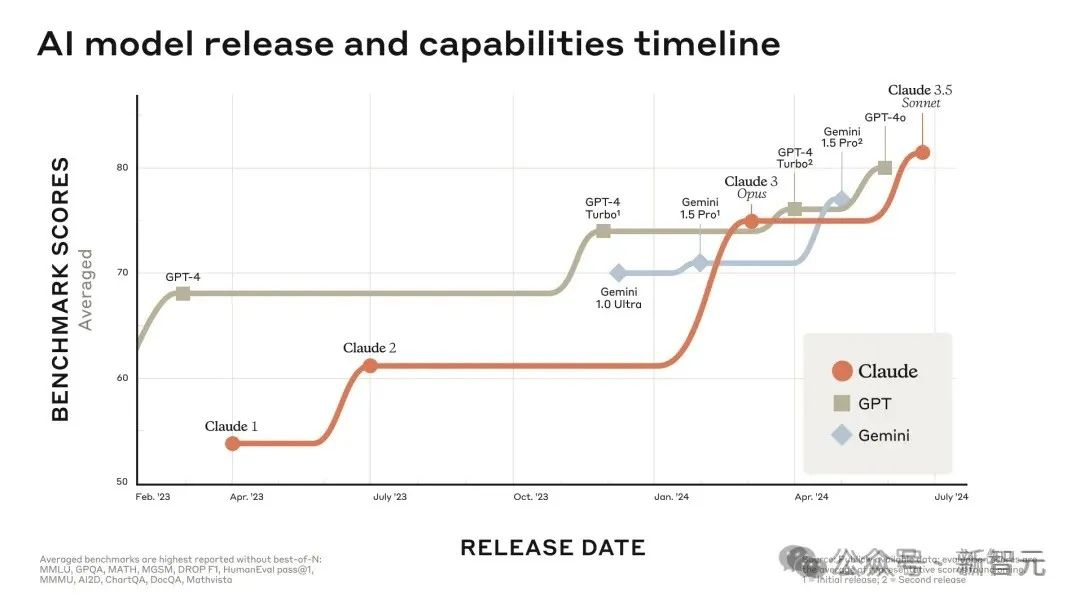
昨夜上线的Claude 3.5 Sonnet,性能直接吊打了GPT-4o,甚至价格还更便宜。网友们纷纷展开实测,有人表示自己一半的工作已经可以由它替代了!而最让人惊喜的新功能,莫过于Artifacts了。
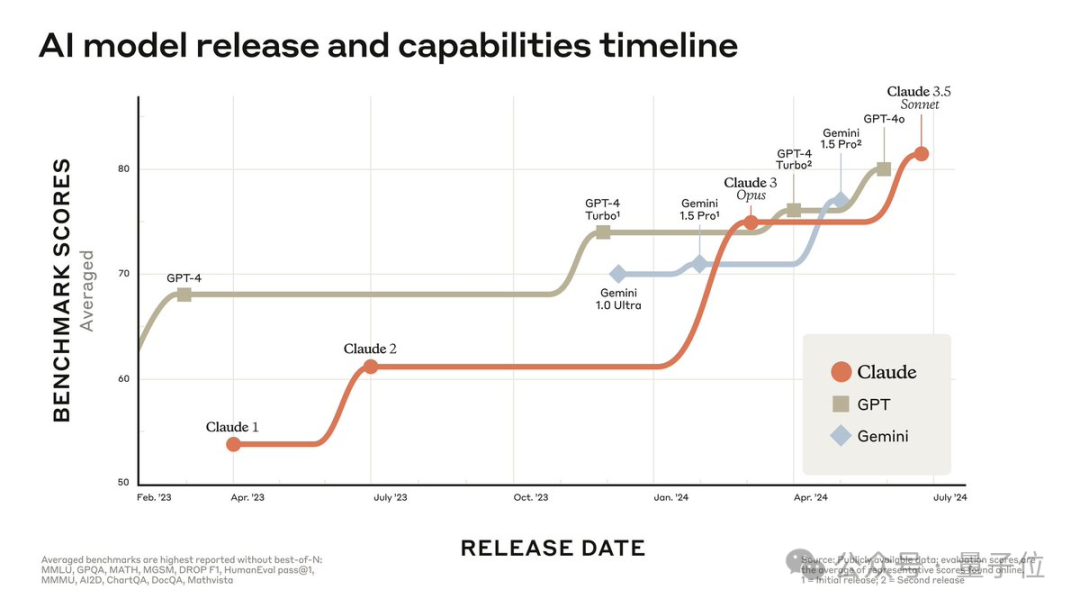
新鲜出炉的Claude 3.5 Sonnet,更快、更便宜,还是全球最强。
继Sora官宣之后,多模态大模型在视频生成方面的应用简直就像井喷一样涌现出来,LUMA、Gen-3 Alpha等视频生成模型展现了极佳质量的艺术风格和视频场景的细节雕刻能力,文生视频、图生视频的新前沿不断被扩展令大家惊喜不已,抱有期待。