
AI颠覆3000亿外包市场,从AI客服到AI催收,180万菲律宾小哥真扛不住了
AI颠覆3000亿外包市场,从AI客服到AI催收,180万菲律宾小哥真扛不住了外包服务成为收入增长的驱动因素
来自主题: AI资讯
10887 点击 2025-05-16 10:12
 搜索
搜索
外包服务成为收入增长的驱动因素

英伟达与沙特主权基金旗下AI公司HUMAIN达成合作,将提供1.8万枚最新AI芯片,助力沙特建设大型数据中心以推动经济转型。此合作推动英伟达股价大涨,黄仁勋身家单日增59亿美元。沙特通过巨额投资及与多家科技巨头合作加速布局AI,但专家指出实际应用落地才是转型关键。
AI 初创公司 Stability AI 发布了名为 Stable Audio Open Small 的“立体声”音频生成 AI 模型,该公司宣称这是市场上速度最快的模型,且效率高到足以在智能手机上运行。

医疗大模型快速渗透医院,2025年百强医院部署率达98%,专科垂直模型达55个,面临数据安全挑战。

此次开源的 Wan2.1-VACE-1.3B 支持 480P 分辨率,Wan2.1-VACE-14B 支持 480P 和 720P 分辨率。通过 VACE,用户可一站式完成文生视频、图像参考生成、局部编辑与视频扩展等多种任务,无需频繁切换模型或工具,真正实现高效、灵活的视频创作体验。

进入2025年,AI的打法逻辑变了。

字节拿出了国际顶尖水平的视觉–语言多模态大模型。
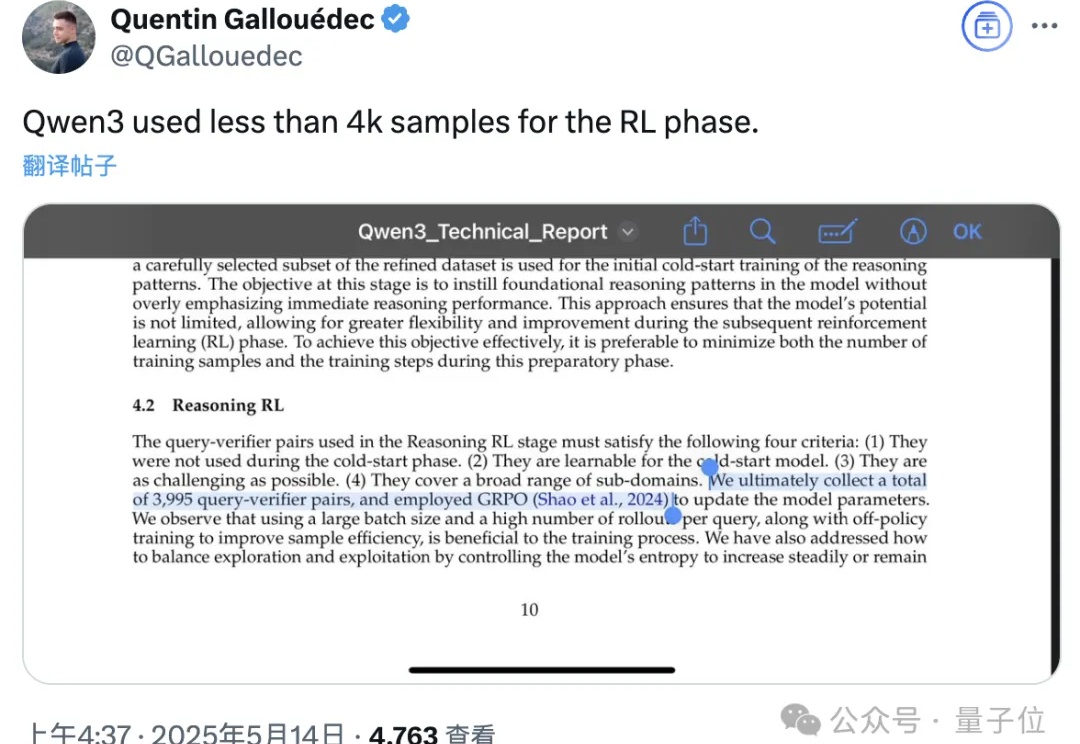
Qwen3技术报告新鲜出炉,8款模型背后的关键技术被揭晓!

80年代,当强化学习被冷落,这对师徒没有放弃;如今,重看来时路,他们给出的建议仍然是,「坚持」住自己的科研思想。

帕兰泰尔(Palantir Technologies)向美国陆军交付首批AI驱动的战场情报车,标志着软件主导的军事技术进入新阶段。战术情报目标访问节点(TITAN)系统是价值1.78亿美元合同的成果,该移动式指挥单元旨在优化目标锁定与决策流程。