
Nature丨告别「炼丹」!AI+机器人闭环搞光伏:效率27.18%,可重复性直接拉高5倍
Nature丨告别「炼丹」!AI+机器人闭环搞光伏:效率27.18%,可重复性直接拉高5倍香港城市大学朱宗龙、曾晓成团队给出了终极终结方案。他们首创了一套AI驱动的自动化闭环研发平台。从2万个分子的“大海捞针”,到自动化机械臂精准制备,再到AI实时反馈调整,全程无需人类插手。
来自主题: AI技术研报
7453 点击 2026-04-17 14:49
 搜索
搜索
香港城市大学朱宗龙、曾晓成团队给出了终极终结方案。他们首创了一套AI驱动的自动化闭环研发平台。从2万个分子的“大海捞针”,到自动化机械臂精准制备,再到AI实时反馈调整,全程无需人类插手。
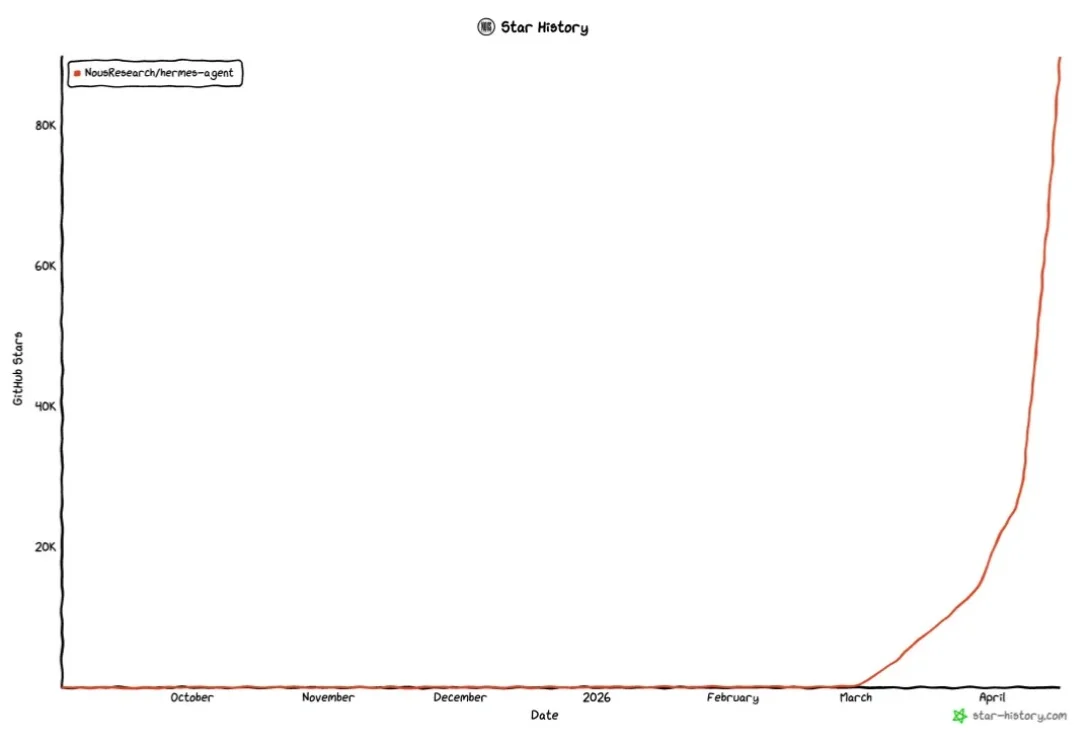
「人红是非多」,Hermes Agent 最近真的火了,一边是 GitHub 积累了超过 8 万星,增长趋势完全是直线上升。

这两天,一款名为Elephant(大象)的匿名模型,在OpenRouter上悄然亮相。上线不到48小时,这一模型已经冲到OpenRouter热榜(Trending)第一,目前调用量超过1850亿个token。

质量和成本只能二选一?通过大脑+小脑分层、场内+场外双轮驱动,数据堂给出了具身智能数据难题的解。

如何工业化生产AI漫剧。

1997年深蓝下棋,2016年AlphaGo围棋,2026年9个Claude副本做真实科研……每次我们都说「只是特定领域」。这一次,我们真的还能说什么?欢迎来到AI成为科研同事、竞争者、甚至继任者的时代。
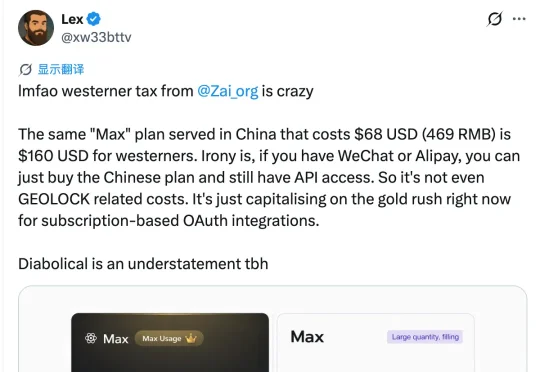
现在,轮到国产模型开始收割老外了。 有网友发现,智谱的Max计划在中国只要469元人民币,折合差不多68美元; 可到了西方用户手里,直接飙到160美元,足足贵了一倍多。

一封内部备忘录,让 AI 行业最大的两家公司之间的战争,第一次有了清晰的文字记录。OpenAI 首席营收官 Denise Dresser 在本周日向全体员工发出了一份长达四页的战略备忘录。文件随后被外媒 The Verge 获取并公开全文。
在AI应用市场上,AI命理是少有的在全球范围内都已验证商业化闭环的赛道。测测坐拥近6000万用户、数亿元营收,韩国Hellobot半年收入1.5亿元,常年稳居本土社交榜前列。印度AstroSage以8000万下载、150万日活实现连续18个月收入增长,毛利率近90%,成为零融资的AI应用成功典范。在欧美市场,Co-Star以零营销投放获得超2000万下载,Moonly活跃用户超1000万。

硅谷新宠Hermes Agent一夜爆火,不仅在GitHub狂揽6.6万星,更因原生接入微信让开发者全线沸腾。如今,Hermes署名的首篇「顶会级」论文也出世了。如今,这款历经9个月打磨,一夜成名的Agent,已在GitHub上狂揽66k星,Fork有8.8k。