数据不够致Scaling Law撞墙?CMU和DeepMind新方法可让VLM自己生成记忆
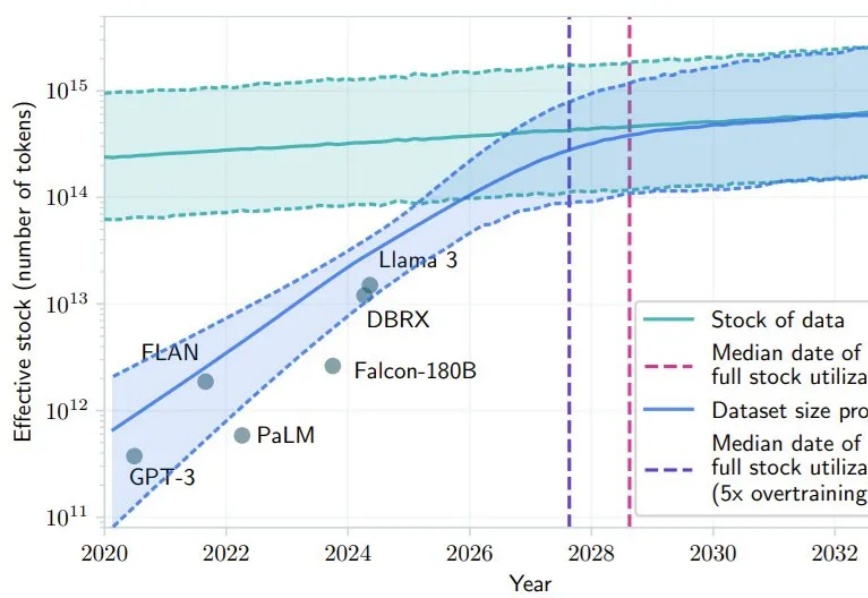
数据不够致Scaling Law撞墙?CMU和DeepMind新方法可让VLM自己生成记忆最近 AI 社区很多人都在讨论 Scaling Law 是否撞墙的问题。其中,一个支持 Scaling Law 撞墙论的理由是 AI 几乎已经快要耗尽已有的高质量数据,比如有一项研究就预计,如果 LLM 保持现在的发展势头,到 2028 年左右,已有的数据储量将被全部利用完。
来自主题: AI技术研报
9790 点击 2025-01-03 15:46