
微软AI新天团曝光!只有1位华人,「谷歌系」超1/3
微软AI新天团曝光!只有1位华人,「谷歌系」超1/3微软AI CEO苏莱曼领导的17名核心高管阵容曝光:新增9名核心成员中有5位来自谷歌(包含DeepMind)系;8名老将中有2名来自苏莱曼共同创办的Inflection AI;17人中有7位是原微软的资深高管。新核心团队将聚焦AI产品落地、安全与隐私、增长与商业化。
来自主题: AI资讯
9592 点击 2025-11-01 09:46
 搜索
搜索
微软AI CEO苏莱曼领导的17名核心高管阵容曝光:新增9名核心成员中有5位来自谷歌(包含DeepMind)系;8名老将中有2名来自苏莱曼共同创办的Inflection AI;17人中有7位是原微软的资深高管。新核心团队将聚焦AI产品落地、安全与隐私、增长与商业化。
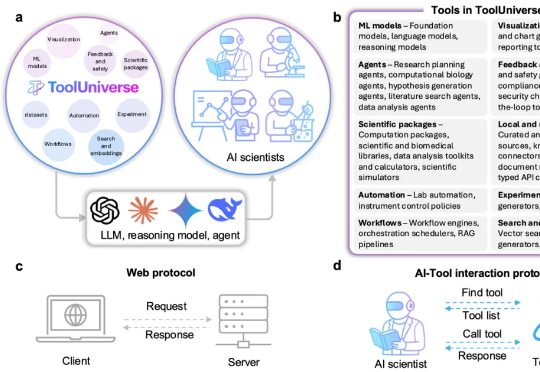
近日,OpenAI 宣称要在 2028 年实现让 AI 完全自主做研究,一下子又把焦点聚在了AI 科学家。 过去,AI 只是作为“助理”辅助研究者们进行科学研究。现在,美国哈佛大学与美国麻省理工学院联
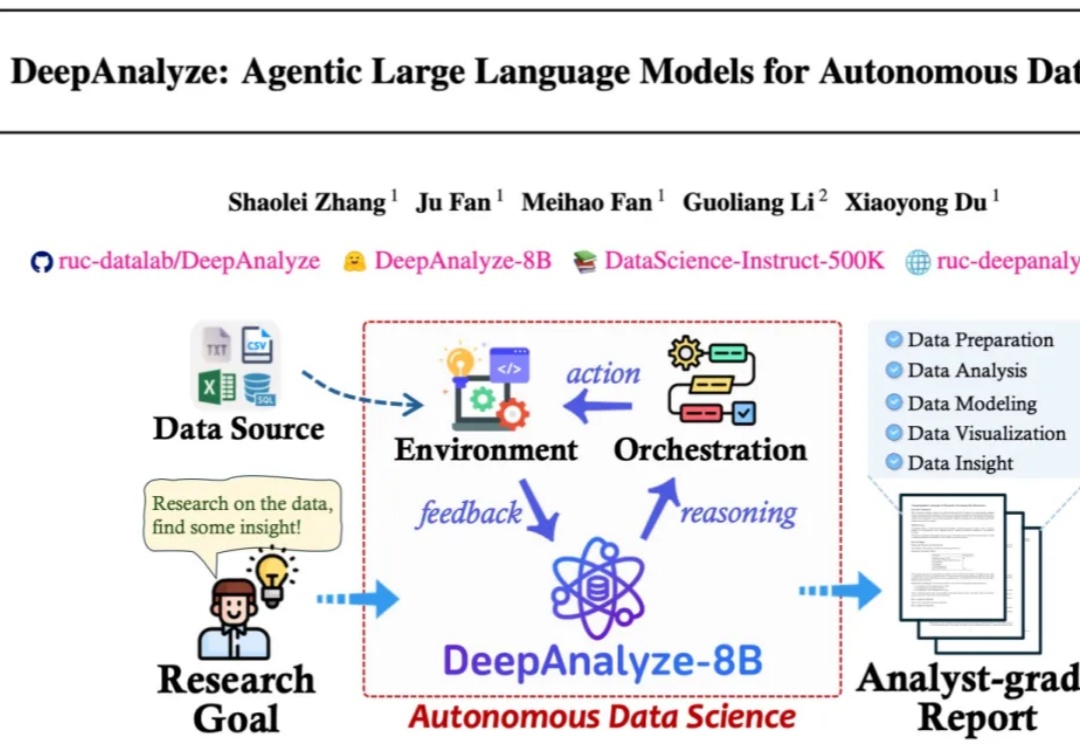
来自人大和清华的研究团队发布了 DeepAnalyze,首个面向自主数据科学的 agentic LLM。DeepAnalyze引起了社区内广泛讨论,一周内收获1000多个GitHub星标、20w余次社交媒体浏览量。

这次不仅发布自研编码模型Composer,还重构了IDE交互逻辑,可以最多8个智能体同时跑,早期测试和开发者都说Cursor 2.0真的太快了。Composer的速度是同等模型的4倍。Cursor说这是一款专门为低延迟智能编码打造的模型,大部分任务都可以在30秒以内完成。

生数科技前产品副总裁廖谦创业了。在此之前,他还先后担任过字节剪映与火山引擎前AIGC产品负责人。8月底从老东家离职后,公司成立仅半个月,就已经拿下了硅谷美元基金HT Investment与BV百度风投的数百万美元投资。
OpenAI完成史上最重要的一次组织架构调整后,紧接着开了一场直播。首次公开了内部研究目标的具体时间表,其中最引人注目的是“在2028年3月实现完全自主的AI研究员”,具体到月份。

蚂蚁集团这波操作大圈粉!智东西10月28日报道,10月25日,蚂蚁集团在arXiv上传了一篇技术报告,一股脑将自家2.0系列大模型训练的独家秘籍全盘公开。今年9月至今,蚂蚁集团百灵大模型Ling 2.0系列模型陆续亮相,其万亿参数通用语言模型Ling-1T多项指标位居开源模型的榜首

今日(10 月 28 日),高通正式宣布推出两款全新芯片——高通 AI200 和高通 AI250,以及相应的机架级解决方案。此举直接挑战了由英伟达和超威半导体长期主导的 AI 芯片领域。消息宣布后,高通股价依然应声飙升,涨幅超 11%,创 2024 年 7 月以来新高。
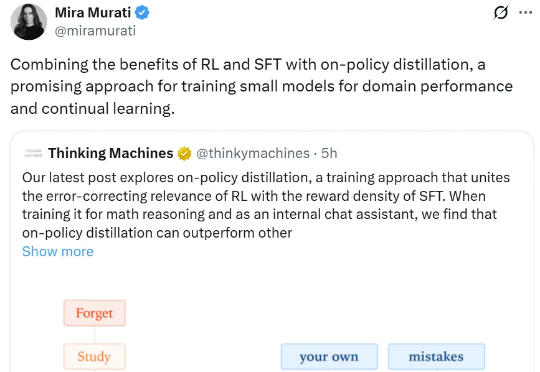
刚刚,不发论文、爱发博客的 Thinking Machines Lab (以下简称 TML)再次更新,发布了一篇题为《在策略蒸馏》的博客。在策略蒸馏(on-policy distillation)是一种将强化学习 (RL) 的纠错相关性与 SFT 的奖励密度相结合的训练方法。在将其用于数学推理和内部聊天助手时,TML 发现在策略蒸馏可以极低的成本超越其他方法。

OpenAI凭ChatGPT坐拥8亿周活与预计约130亿美元年收入,订阅难覆盖成本、探索广告并豪赌算力扩张;Anthropic低调专攻企业,Claude在代码等场景见长,企业占营收八成、30万客户、年收入约70~90亿美元。OpenAI主攻C端,Anthropic深耕B端,前者求声量与规模,后者重价值与稳健,胜负未定。