

OpenClaw 是噱头吗?普通人要 OpenClaw有什么用?
OpenClaw 是噱头吗?普通人要 OpenClaw有什么用?这两天,各大社交平台和自媒体的视频再次将 OpenClaw带火了。“一人公司”、“坐拥 10 几个听话员工”、“全自动写自媒体赚钱”、“意念编程”,还有传播非常广的“500元,上门安装 OpenClaw”。
来自主题: AI资讯
7995 点击 2026-03-09 09:52
这两天,各大社交平台和自媒体的视频再次将 OpenClaw带火了。“一人公司”、“坐拥 10 几个听话员工”、“全自动写自媒体赚钱”、“意念编程”,还有传播非常广的“500元,上门安装 OpenClaw”。
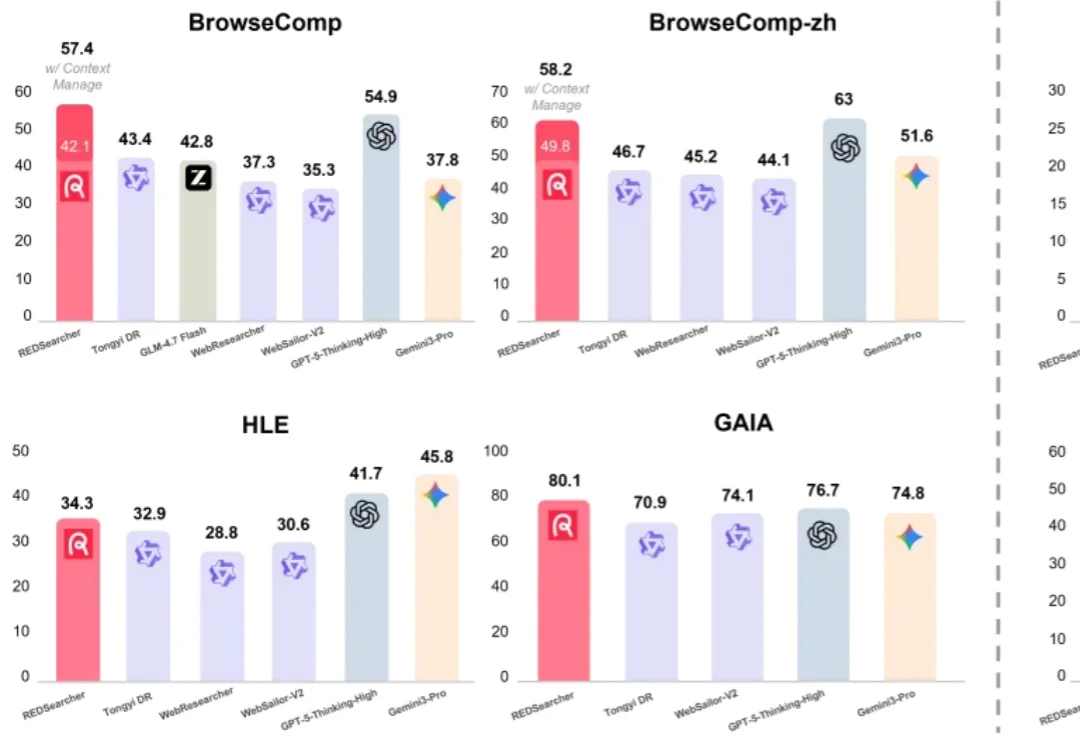
「2018 到 2023 年间在 EMNLP 会议上发表的那篇论文中,第一作者本科就读于达特茅斯学院、第四作者本科就读于宾夕法尼亚大学的那篇科学论文,题目是什么?」
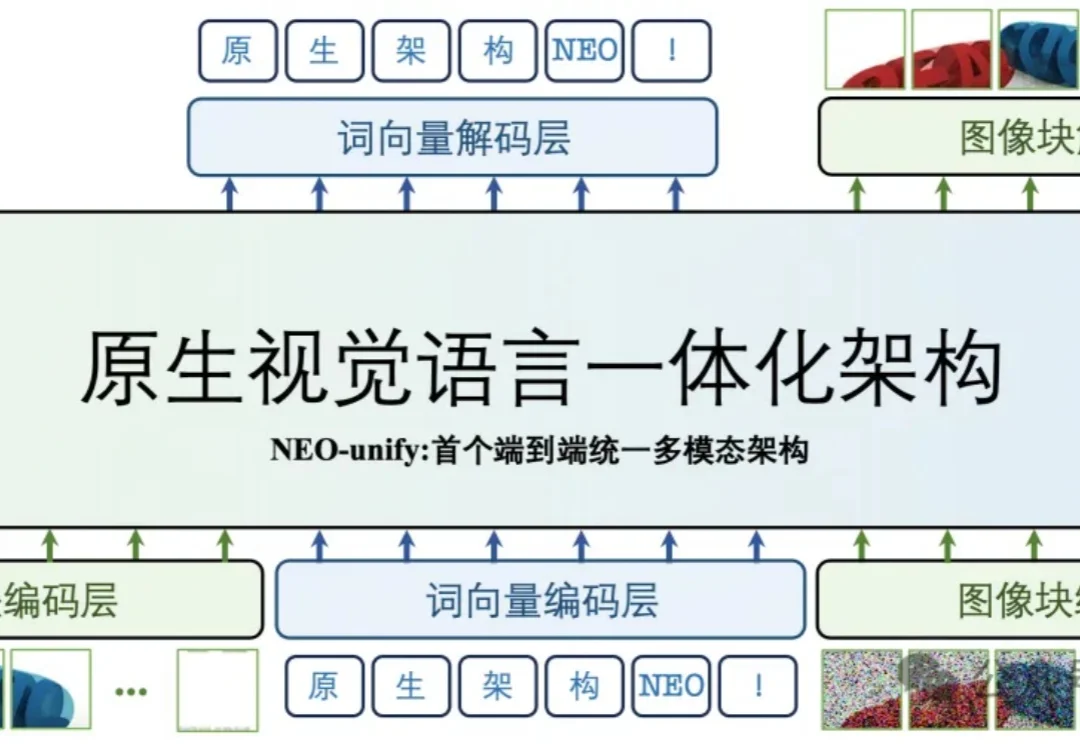
多模态大模型的研发范式,正在被彻底重构。
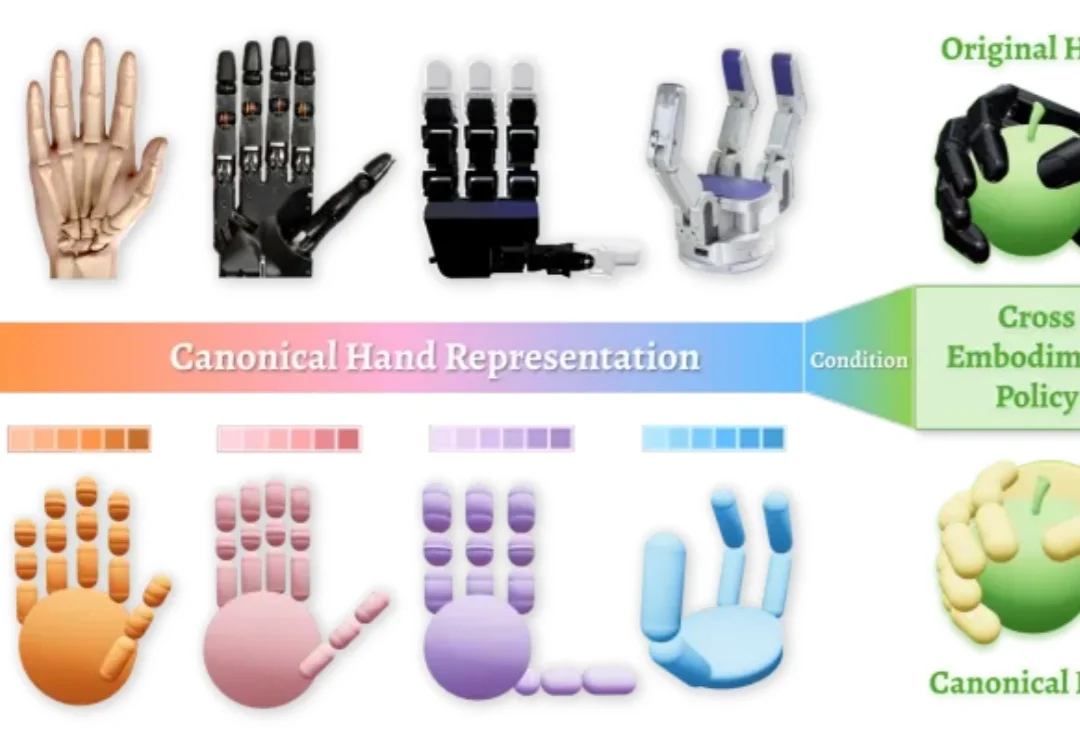
在机器人操作领域,一个长期悬而未决的核心问题始终困扰着研究者: 面对形态各异的灵巧手,我们是否注定要为每一种手型单独设计表示方式与控制策略?
这个女孩后来创立了 BoldVoice,一个帮助全球 10 亿非英语母语者突破发音障碍的 AI 平台。就在最近,这家只有 7 名员工的公司宣布完成了 2100 万美元的 A 轮融资
这几天我一直在找便宜获取 ChatGPT 的渠道,终于让我找到了一个靠谱的方法。八毛三就能搞到 ChatGPT Team 账号,GPT-5、GPT-4 Pro 随便用,而且还能直接接到龙虾里当 API 用。
用OpenClaw挂机,抓取网页时频频翻车的烦人bug终于有解了。一个名为Scrapling的数据采集神器,几乎一夜之间就成了OpenClaw的“最强外挂”。这玩意儿不仅能穿透各种防爬虫的网页护盾,还能把网上杂乱的网页源码生扒下来,直接清洗成干净的结构化数据。

从OpenAI出走的前首席研究官Bob McGrew,没有去卷更聪明的大模型,而是杀进制造业工厂,要用AI为流水线机器装上「眼睛+大脑」。

近日,Anthropic 公布了一组惊人的数字,在与 Mozilla 公司进行合作,测试旗下模型 Claude Opus 4.6 发现漏洞能力的过程中,两周内,就找出 Mozilla 公司「火狐」(Firefox)浏览器中 22 个不同的漏洞,其中 14 个是「高危漏洞」级别,而这几乎是 Mozilla 2025 年修复的全部「高危漏洞」的五分之一。

这位年仅 24 岁的哥们叫 Riley Walz,被《连线》和《纽约时报》等媒体冠以「硅谷小丑(Jester of Silicon Valley)」称号。别人写代码是为了改变世界,他写代码纯粹是为了给现实世界找点乐子。