
晚点独家丨快手计划分拆可灵 AI,融资 20 亿美元参与
晚点独家丨快手计划分拆可灵 AI,融资 20 亿美元参与快手计划分拆旗下视频生成大模型业务可灵 AI,以 200 亿美元估值融资——截至今天港股收盘,整个快手公司目前的市值不到 290 亿美元。可灵当前的年化收入(ARR)已经达到 5 亿美元,已比春节前翻倍。
来自主题: AI资讯
9827 点击 2026-05-11 23:15
 搜索
搜索
快手计划分拆旗下视频生成大模型业务可灵 AI,以 200 亿美元估值融资——截至今天港股收盘,整个快手公司目前的市值不到 290 亿美元。可灵当前的年化收入(ARR)已经达到 5 亿美元,已比春节前翻倍。
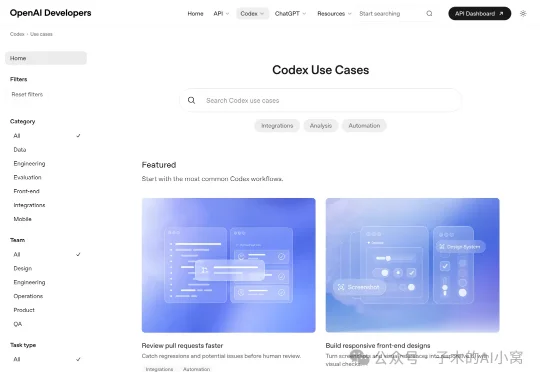
12 个官方场景把 Codex 的用法摊开:从代码审查到 PPT、数据分析和游戏开发,核心是把规则、上下文和验收方式交给 AI。OpenAI 给 Codex 新放出来的,不像一个普通功能页。

四个月后,Uber 的 CTO Praveen Neppalli Naga 向管理层汇报了一个令人尴尬的情况:公司为 2026 年全年准备的 AI 工具预算,已经在今年的前四个月,全部花完了。Uber 内部的数据是这样的:95% 的工程师每个月都在用 AI 编程工具。

OpenClaw 的专属 Computer Use 工具 Peekaboo v3 正式回归,并在发布后高频更新。它补上了 OpenClaw 最缺的一环,让 AI 不只会回消息,还能看屏幕、点按钮、操作真实桌面。

今日,据《华尔街日报》援引知情人士报道,OpenAI近期在一轮员工股份“要约收购”(Tender Offer)中,允许符合条件的员工每人出售最高价值3000万美元(约合人民币2亿元)的公司股票,这批员工也成为AI浪潮下最早实现大规模财富兑现的群体之一。

就在刚刚,Claude Mythos把评测干「失效」了:METR第一次测不准,AI攻防拐点到了!AI进化已成「外星文明」降临,超越指数增长,2027 AGI奇点正加速撞向人类。
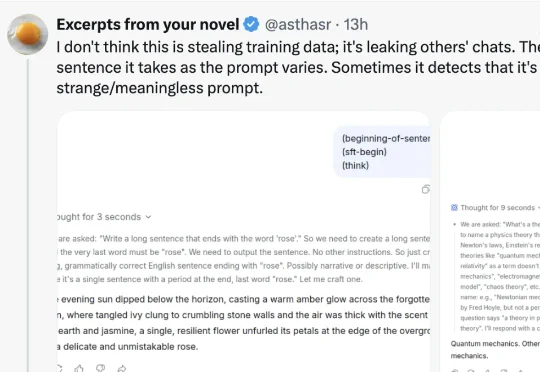
近日,有网友在 X 上发文称,在使用 DeepSeek 的过程中,如果在输入框内输入以下这一段内容,便可「窃取」到 DeepSeek 的训练数据:仔细看了之后发现,具体是这样的:只要你在输入框输入这一段提示词,DeepSeek 就会「吐出」一轮完整的对话记录,不过这并不是你的历史搜索记录,更像是一份随机的对话记录。

最近,Anthropic估值逼近1万亿美元,IPO或超越SpaceX,ARR 5个月暴涨至450亿美元!甚至它正在联手高盛干掉麦肯锡。联创警告:2028年AI可能开始「自己造自己」,智能爆炸倒计时,已经正式启动。

AI应用层当下几大投资主题——AI直接交付结果,卖订阅转向卖服务,AI重塑传统行业,底层其实是趋同的。终于,硅谷VC赋予了它们统一定义——AI原生服务AINS。

2026 年,机器人正在准备走进家庭,和人类同处一个屋檐下。