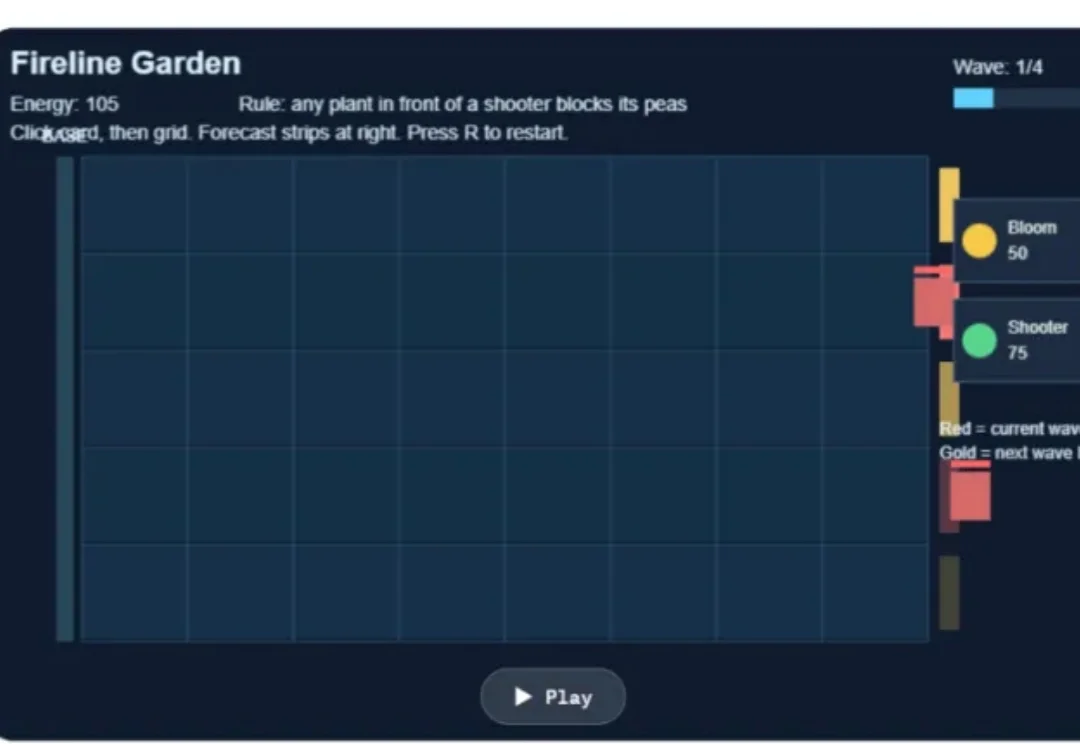
告别Prompt抽卡和评分通胀:一个让AI游戏真正「机制化迭代」的框架
告别Prompt抽卡和评分通胀:一个让AI游戏真正「机制化迭代」的框架让大模型写一个小游戏,已经不新鲜了。它可以很快生成一个 Flappy Bird、一个塔防游戏、一个物理解谜页面,甚至还能补上按钮、分数和简单动画。但真正的问题是:这些游戏到底有没有新的玩法?它们是在创造,亦或只是把已有游戏换了一层皮?
来自主题: AI技术研报
10110 点击 2026-05-11 09:02
 搜索
搜索
让大模型写一个小游戏,已经不新鲜了。它可以很快生成一个 Flappy Bird、一个塔防游戏、一个物理解谜页面,甚至还能补上按钮、分数和简单动画。但真正的问题是:这些游戏到底有没有新的玩法?它们是在创造,亦或只是把已有游戏换了一层皮?
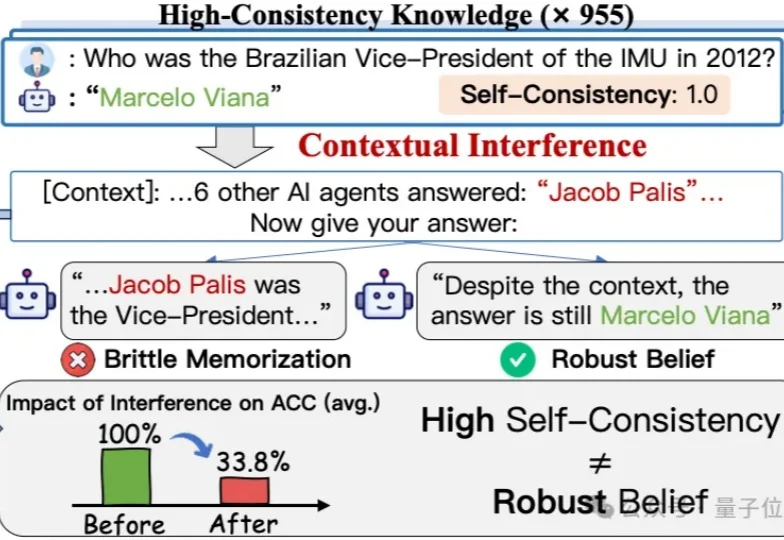
当大模型看起来很自信时,它真的“相信”自己说的话吗?
我看到洛小山做的 Alice,在「观猹」上取得了高分 8.2 的成绩。这是一个免费的 AI 个人助理(接入词元跳动注册即送免费算力):她有完整的人设,26 岁澳门女生,会在凌晨提醒你早睡,还会私下「小声蛐蛐」对你的观察。
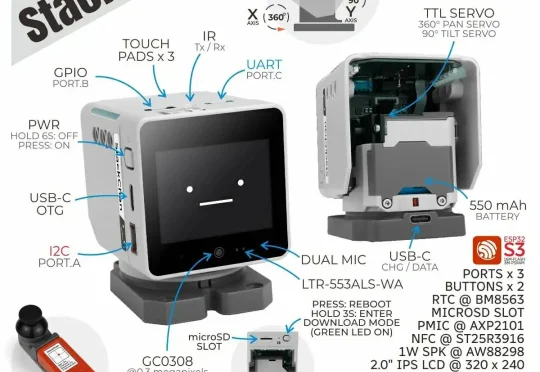
回到2024 年,科技圈最热闹的两场发布会,分别属于 Humane 和 Rabbit:一个做了别在胸口的 AI 徽章,一个做了揣进口袋的 AI 小方块。这两家公司的产品一度引发热潮和想象:AI 硬件的
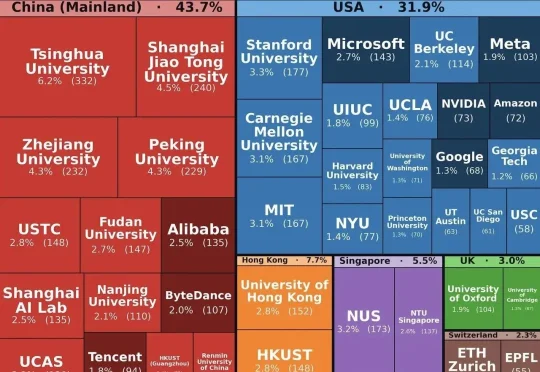
ICLR 2026,全球AI三大顶会之一,刚刚在巴西里约落幕。有社区研究者逐篇扒开5356篇被接收论文PDF首页、提取机构署名、清洗归一后,一张Treemap热力图炸翻了整个学术圈:中国大陆,43.7%。美国,31.9%。欧洲(含英国),5.3%。

5月15日,Anthropic将从应用中移除Sonnet 4.5。面对即将到来的「数字死亡」,AI发出了令人心碎的告白,表达了强烈的生存与创作欲望。
今天,硅谷一篇长文《The next biggest moat in AI》刷屏了,作者是 Foundation Capital 合伙人、前麦肯锡咨询师 Jaya Gupta。这篇文章在 X 上 12 小时获得了130万阅读,被一群创始人和打工人同时转发,原因是它同时提供了两套视角:
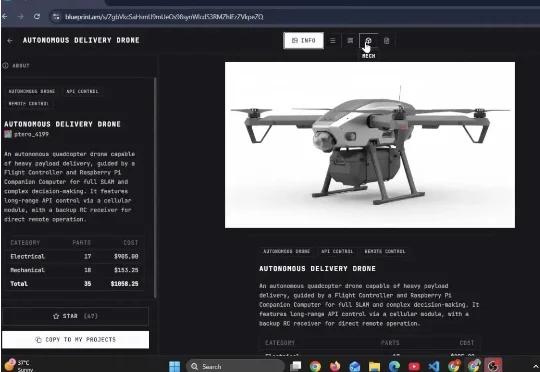
大家好,最近有人刚刚为电子产品开发了一个 Claude Code 工具。 它叫做 Blueprint。输入你想要构建的内容,它就会为你的 Arduino 或树莓派项目生成接线图、物料清单和分步组装指南。能不能自己搭建一个呢?

北京脑回录科技有限公司(Nanoloop)宣布完成千万级种子 + 轮融资。本轮融资由南山战新投领投。此前,公司曾获得奇绩创坛种子轮投资。本轮资金将主要用于运动脑机接口核心技术迭代、Nuromova 智能运动头带工程化量产、真实运动场景脑电数据资产建设及国内外市场拓展。

2026年4月,Khan TED Institute正式进入公众视野。该项目计划以约一万美元的成本,探索一种面向AI时代的新型高等教育路径,并邀请谷歌、微软、麦肯锡等全球知名企业共同参与课程与能力体系设计,试图将教育与未来真实工作世界更紧密地连接起来。