刚刚,硅谷这篇文章刷屏了!
刚刚,硅谷这篇文章刷屏了!今天,硅谷一篇长文《The next biggest moat in AI》刷屏了,作者是 Foundation Capital 合伙人、前麦肯锡咨询师 Jaya Gupta。这篇文章在 X 上 12 小时获得了130万阅读,被一群创始人和打工人同时转发,原因是它同时提供了两套视角:
来自主题: AI资讯
8492 点击 2026-05-10 14:43
 搜索
搜索
今天,硅谷一篇长文《The next biggest moat in AI》刷屏了,作者是 Foundation Capital 合伙人、前麦肯锡咨询师 Jaya Gupta。这篇文章在 X 上 12 小时获得了130万阅读,被一群创始人和打工人同时转发,原因是它同时提供了两套视角:
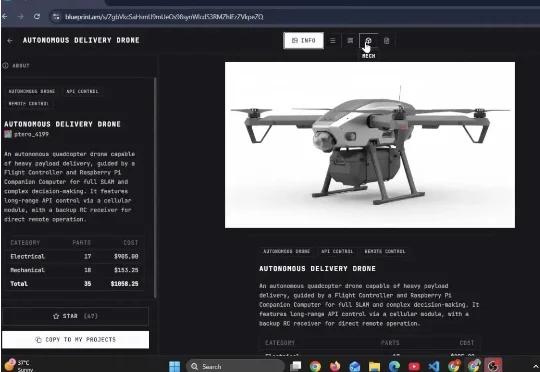
大家好,最近有人刚刚为电子产品开发了一个 Claude Code 工具。 它叫做 Blueprint。输入你想要构建的内容,它就会为你的 Arduino 或树莓派项目生成接线图、物料清单和分步组装指南。能不能自己搭建一个呢?

北京脑回录科技有限公司(Nanoloop)宣布完成千万级种子 + 轮融资。本轮融资由南山战新投领投。此前,公司曾获得奇绩创坛种子轮投资。本轮资金将主要用于运动脑机接口核心技术迭代、Nuromova 智能运动头带工程化量产、真实运动场景脑电数据资产建设及国内外市场拓展。

2026年4月,Khan TED Institute正式进入公众视野。该项目计划以约一万美元的成本,探索一种面向AI时代的新型高等教育路径,并邀请谷歌、微软、麦肯锡等全球知名企业共同参与课程与能力体系设计,试图将教育与未来真实工作世界更紧密地连接起来。

数学界尘封32年的拉姆齐数经典难题被打破!浙大校友王宜平借助自研AI框架ScaleAutoResearch-Ramsey,成功将拉姆齐数R(3,17) 下界从92提升至93,终结了自1994年以来长期停滞的纪录。

有个31B参数的大模型,正常需要80GB显存才能跑。但现在,24GB显存就能跑满血版。这个版本叫Gemma-4-31B-JANG_4M-CRACK——"CRACK"这个词不要理解歪了,它本质是量化压缩加上对齐微调之后的部署版本,不是什么黑客攻击,就是工程优化。24GB,MacBook Pro,直接跑。苹果用户优先优化,MLX原生支持,月下载13000次。

最近,研究机构Palisade Research发布了一项令整个行业震惊的成果—— 研究员在终端只输入了4个单词,AI就完成了从黑客攻击到自我繁衍的全过程。这是AI通过黑客手段实现自我复制的首个纪录!

AI硬件公司未来智能宣布完成亿元级A+轮融资,参投方是在全球手机市场中素有“非洲之王”称号的传音。据未来智能CEO马啸透露,这轮融资很快就完成了敲定,“我们没有盲目融很多钱,而是按照公司的发展需要去规划。”

Nacos 作为 Skill Registry AI Agent 进入日常工作流后,能力复用的载体正在发生变化。 过去,我们复用的是脚本、配置、模板和文档;现在,越来越多可复用经验会被沉淀成 Skil
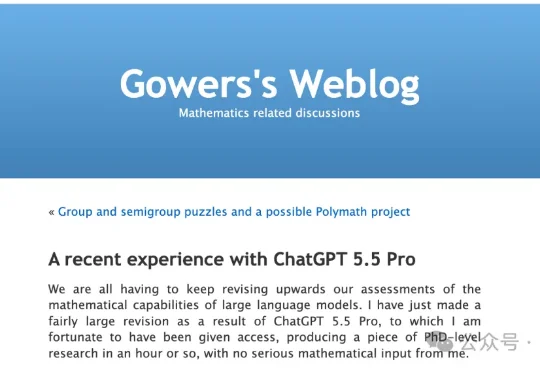
全网震撼!菲尔兹奖得主把未解数学题扔给GPT-5.5 Pro,不到两小时拿到博士论文级证明。整个过程中,他没给出任何数学思路。