

网文编辑拒绝AI投稿,为什么AI写小说有股伪人感?
网文编辑拒绝AI投稿,为什么AI写小说有股伪人感?有AI,中止交易!
来自主题: AI资讯
7113 点击 2025-02-19 10:25
有AI,中止交易!

再次证明,AI行业里大力出奇迹。
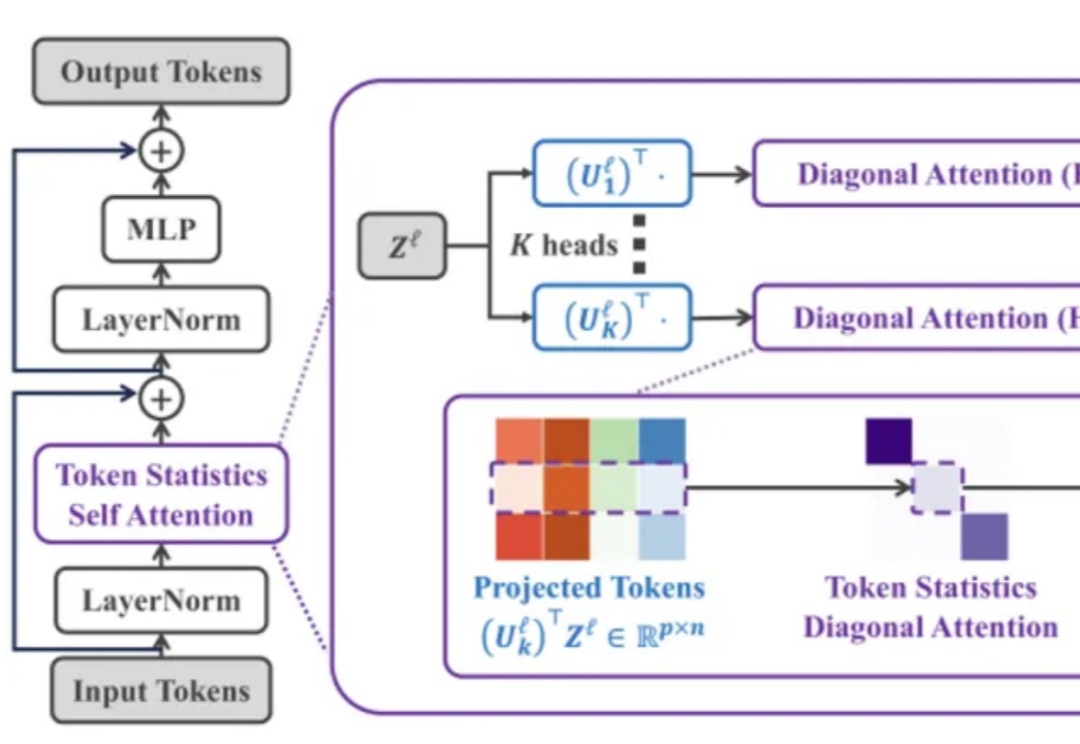
Transformer 架构在过去几年中通过注意力机制在多个领域(如计算机视觉、自然语言处理和长序列任务)中取得了非凡的成就。然而,其核心组件「自注意力机制」 的计算复杂度随输入 token 数量呈二次方增长,导致资源消耗巨大,难以扩展到更长的序列或更大的模型。

当全球AI军备竞赛尚未燃起狼烟时,一位中国青年已悄然完成技术储备。潞晨科技创始人尤洋——这位拥有传奇学历背景的90后科技精英,在读书期间,就意识到到了“AI是未来,中国人要有自己的技术”。
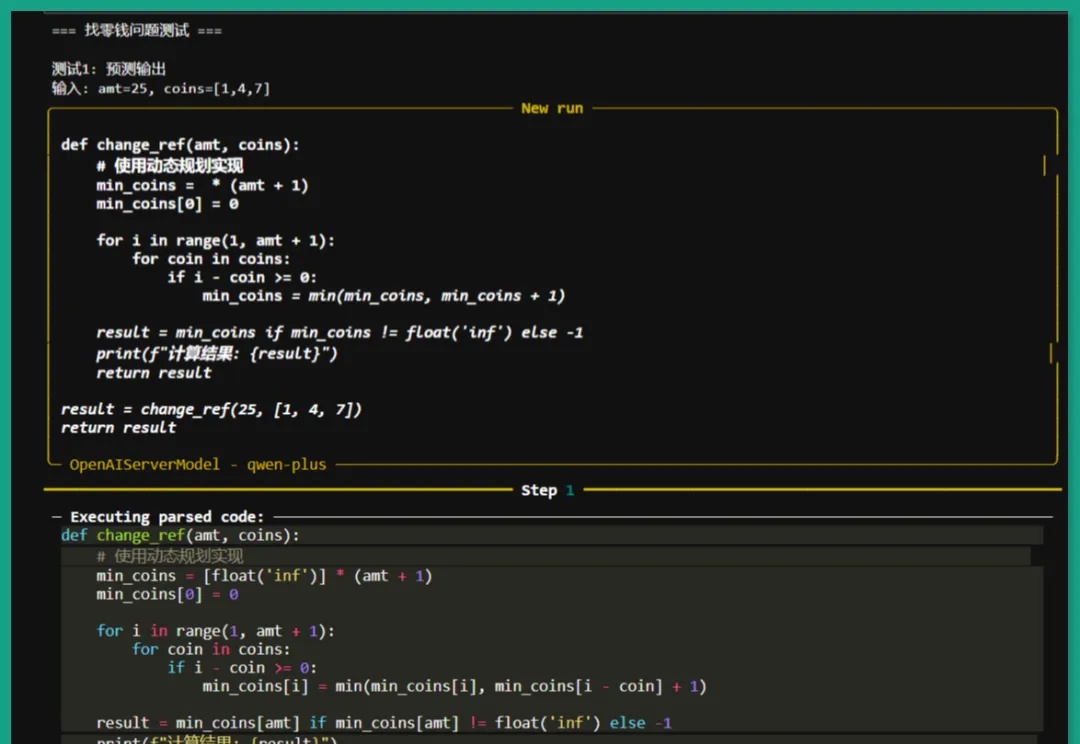
我们正见证一场静默的推理革命。传统AI训练如同盲人摸象,依赖碎片化文本拼凑认知图景,DeepSeek-AI团队的CODEI/O范式首次让机器真正"理解"了推理的本质——它将代码执行中蕴含的逻辑流,转化为可解释、可验证的思维链条,犹如为AI装上了解剖推理过程的显微镜。
去年 8 月,Codeium 完成了由 General Catalyst、Kleiner Perkins 等参与的 1.5 亿美元融资,估值来到 12.5 亿美元,是这些老牌基金在 AI Coding 领域下的重注。之后在 11 月 Codeium 正式发布了 Agentic IDE Windsurf,与 Cursor/Devin 进行差异化竞争。
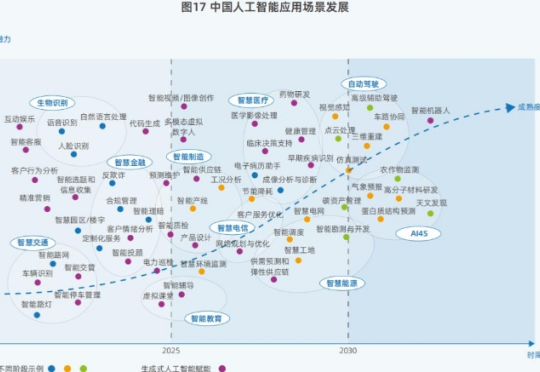
这个AI领域千亿级市场,将辐射千家万户。 DeepSeek-R1横空出世,打响了大模型比拼性价比的第一枪。 Meta、OpenAI等国外头部大模型厂商纷纷复刻或变相降价。比DeepSeek-R1晚两周发布的OpenAI o3-mini模型,定价比前代模型o1-mini降低了超6成,比前代完整版的o1模型便宜超9成。

今天凌晨,一个创业消息引爆了整个 AI 社区:一家名为 Thinking Machines Lab 的新创业公司建立了,而其背后有一个堪称有史以来最豪华的大模型创业团队阵容。

“我十分想见梁文锋。” DeepSeek火了之后,投资圈开始焦虑了。 根据“路边消息社”报道,“最近想要见DeepSeek创始人梁文锋,需要汇报到地方办公室。”根据报道,最近想要约见梁文锋的投资机构太多,为了保护这位AI大牛,想约见他的机构,需要先报到省委办公厅。

大模型混战,一边卷能力,一边卷“低价”。 DeepSeek彻底让全球都坐不住了。 昨天,马斯克携“地球上最聪明的AI”——Gork 3在直播中亮相,自称其“推理能力超越目前所有已知模型”,在推理-测试时间得分上,也好于DeepSeek R1、OpenAI o1。不久前,国民级应用微信宣布接入DeepSeek R1,正在灰度测试中,这一王炸组合被外界认为AI搜索领域要变天。