

全球AI芯片被一家味精厂卡脖子?份额超95%,英伟达也得排队抢产能
全球AI芯片被一家味精厂卡脖子?份额超95%,英伟达也得排队抢产能卡住英伟达Rubin产能的,既不是GPU也不是HBM,竟是一张绝缘薄膜?全球95%以上的供应,握在一家你只听过它味精的日本公司手里。
来自主题: AI资讯
10033 点击 2026-04-14 15:48
卡住英伟达Rubin产能的,既不是GPU也不是HBM,竟是一张绝缘薄膜?全球95%以上的供应,握在一家你只听过它味精的日本公司手里。
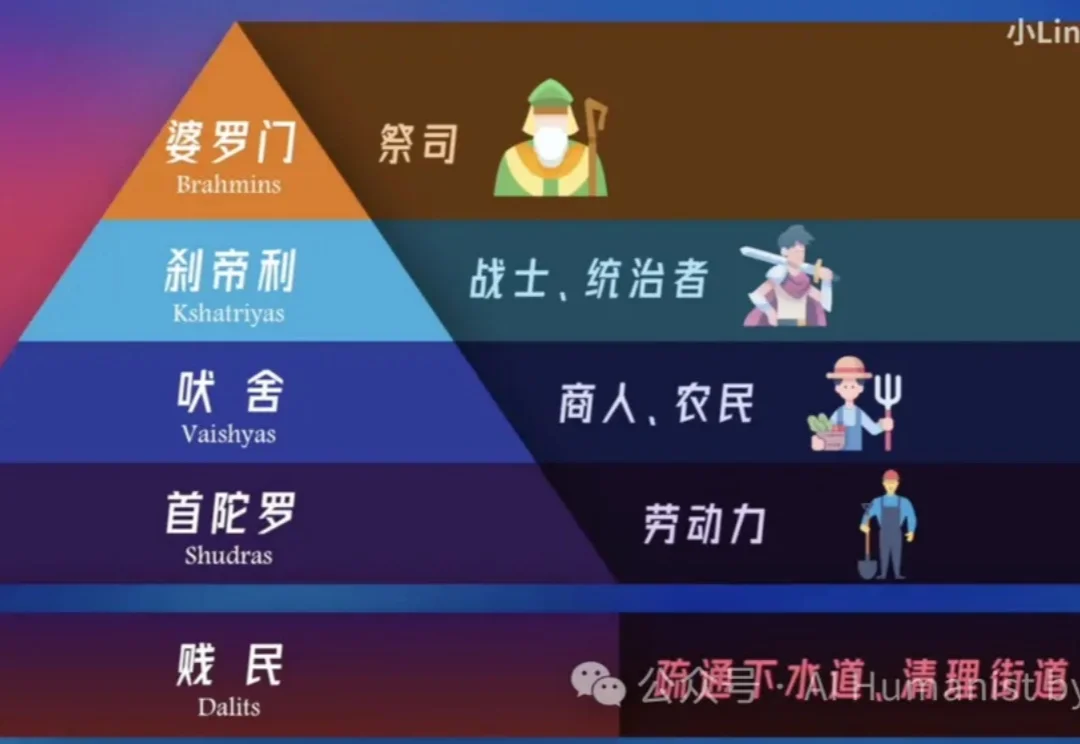
前两天晚上,我又刷到了小 Lin 说的视频。
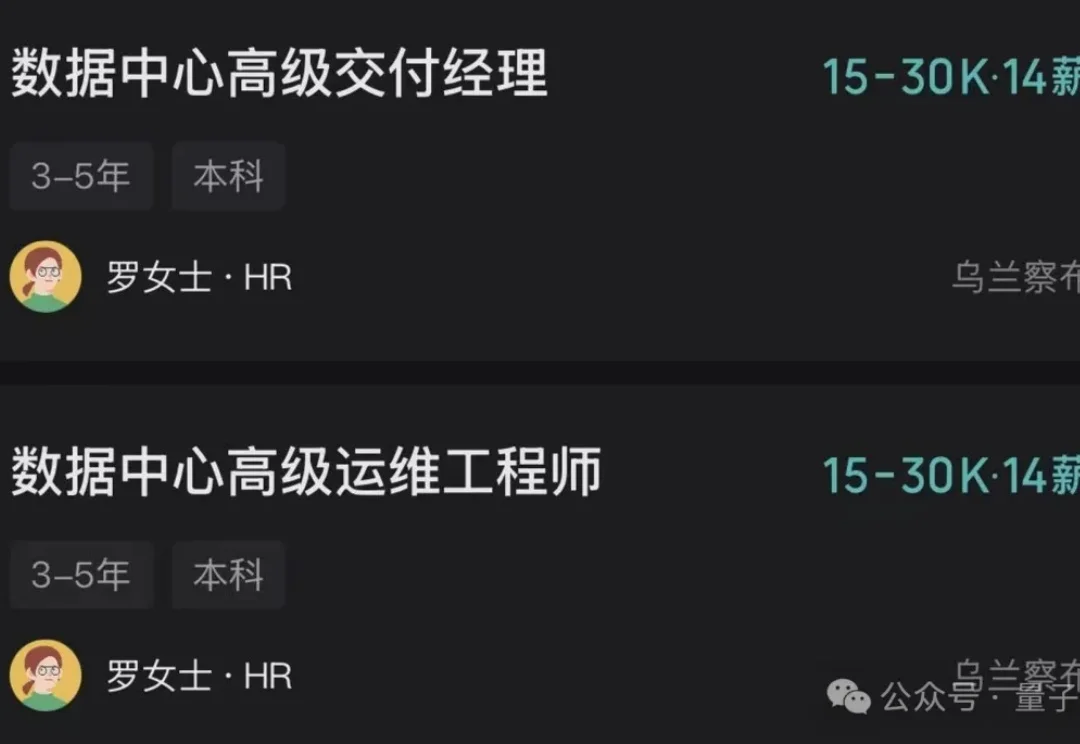
月薪30K,去草原给DeepSeek运维机房。

未来我们到底需要什么样的家庭服务机器人,这家公司给了些许答案

他还在开发一个CEO智能体。

试想一下,如果把当下大火的大模型技术带回 1970 年,会发生什么?

Vidu Q3带着「全家桶」重磅回归,视觉、听觉、场景能力全面进化。AI视频的生产级交付时代,真的来了。

南洋理工大学MMLab团队推出Hand2World,让AI世界模型真正「伸手」互动。只需在空中比划手势,模型就能生成逼真第一人称交互视频,实时响应调整。它摒弃旧有遮挡误导,用3D手部结构与射线编码解耦手与头运动,首次实现闭环持续交互。
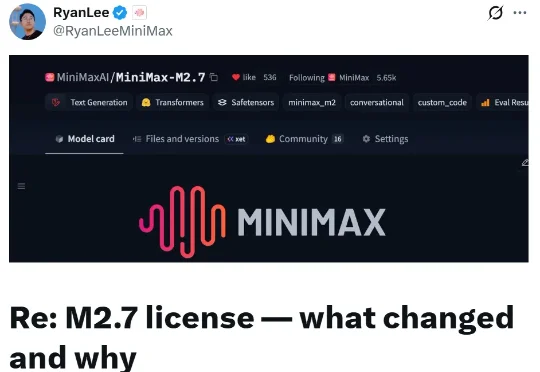
近日,刚带着对标顶级闭源模型的强悍性能登场不久的 MiniMax M2.7 模型,悄悄变更了开源使用条款。尽管先前将权重公开在 Hugging Face,但当下已然收紧授权:商业用途需获得 MiniMax 书面授权。非商业用途依旧免费且不受限制,科研、个人项目、自用微调等场景均不受影响;但若是搭建托管服务或开发商业产品,则必须申请授权。
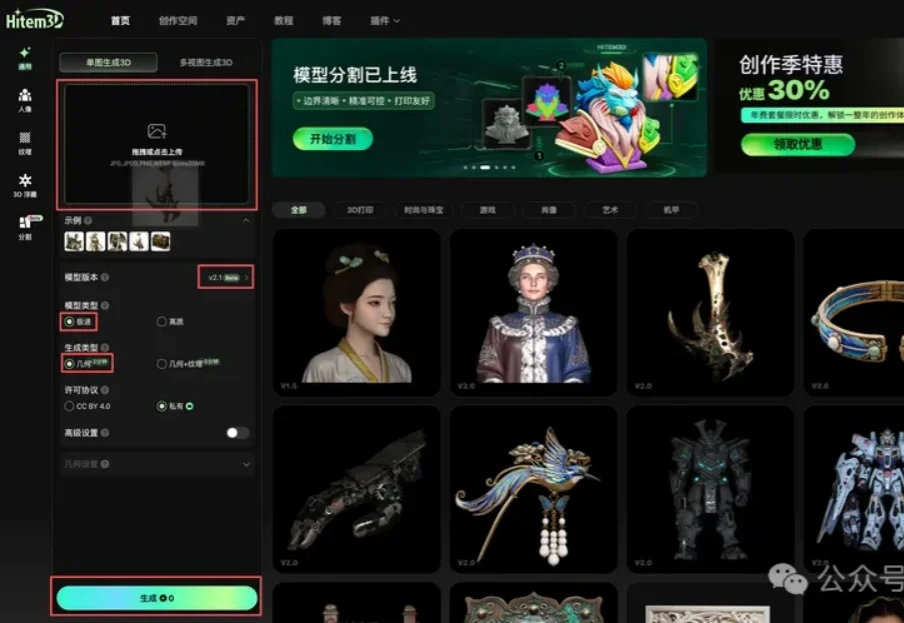
前两天我刷到一个工具的时候,第一反应其实不是拿真人照片试,也不是拿潮玩图试。