
速递|Meta将支付1.4亿美元使用Black Forest Labs的AI图像技术
速递|Meta将支付1.4亿美元使用Black Forest Labs的AI图像技术Meta 已签署一份价值超 1 亿美元的多年度合同,将使用 AI 图像初创公司 Black Forest Labs 的技术,这是这家社交媒体公司为扩展人工智能服务的最新投资。
来自主题: AI资讯
8239 点击 2025-09-11 11:43
 搜索
搜索
Meta 已签署一份价值超 1 亿美元的多年度合同,将使用 AI 图像初创公司 Black Forest Labs 的技术,这是这家社交媒体公司为扩展人工智能服务的最新投资。

AI图像编辑技术发展迅猛,扩散模型凭借强大的生成能力,成为行业主流。 但这类模型在实际应用中始终面临两大难题:一是“牵一发而动全身”,即便只想修改一个细节,系统也可能影响到整个画面;二是生成速度缓慢,难以满足实时交互的需求。

GPT-4o发布才过去半年,Nano Banana这种「下一代」的生图模型就出来了。 这难道是AI界的摩尔定律?不敢想再过半年后,会是什么样的「魔鬼级」生图模型来屠Nano Banana

谷歌最新图像模型nano banana横空出世,它不仅能融合多张图片拼接出全新画面,还能理解地理、建筑与物理结构,甚至将二维地图转化为三维景观。凭借Gemini的世界知识与交错生成技术,模型实现了「有记忆」的多轮创作,带来极高一致性与创造力。nano banana正在重塑AI图像生成的边界,也引发了「AI创意伙伴」未来的无限遐想。

Meta 首席 AI 负责人 Alexandr Wang 周五在 Threads 上发帖宣布,Meta 将与 Midjourney 合作 ,获得这家初创公司 AI 图像和视频生成技术的使用许可。Wang 表示 Meta 的研究团队将与 Midjourney 协作,将该技术整合到未来的 AI 模型和产品中。
今天凌晨,阿里推出了最新图像编辑模型 Qwen-Image-Edit!该模型基于 200 亿参数的 Qwen-Image 架构构建,支持中英文双语精准文本编辑,在保持原有风格的同时完成修改。此外,Qwen-Image-Edit 将输⼊图像同时输⼊到 Qwen2.5-VL(实现视觉语义控制)和 VAE Encoder(实现视觉外观控制),兼具语义与外观的双重编辑能⼒。

AI图像的水印技术要变天了!一款全新的去水印技术——UnMarker,能在5分钟内去除市面上几乎所有的AI图像水印。
近年来,文生图模型(Text-to-Image Models)飞速发展,从早期的 GAN 架构到如今的扩散和自回归模型,生成图像的质量和细节表现力实现了跨越式提升。这些模型大大降低了高质量图像创作的门槛,为设计、教育、艺术创作等领域带来了前所未有的便利。
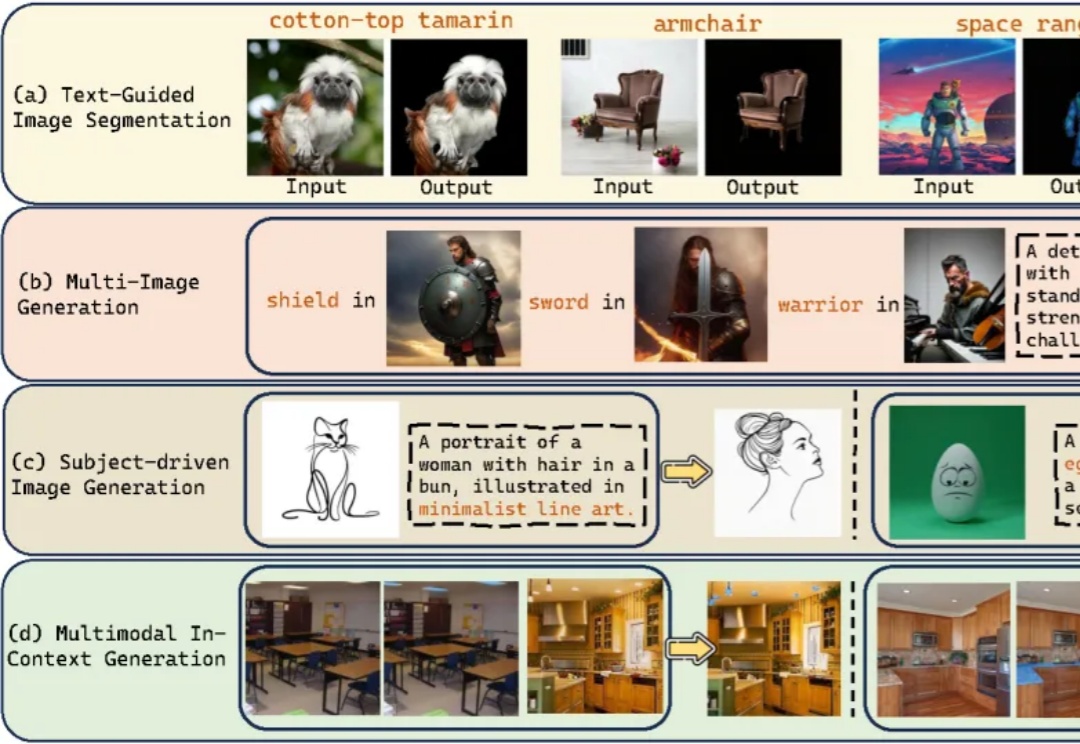
当下的AI图像生成领域,Diffusion模型无疑是绝对的王者,但在精准控制上却常常“心有余而力不足”。

智源统一图像生成模型OmniGen2发布后,立刻在AI图像生成领域掀起巨响,多模态技术生态进一步打通。才一周,GitHub星标就已经破了2000,X上的话题浏览数直接破数十万。