
GPT-5.5彻底击穿300个黑客评测任务,仅需5000万Token!
GPT-5.5彻底击穿300个黑客评测任务,仅需5000万Token!GPT-5.5 把进攻性网络安全最难的 7 个基准全部打穿,92.4% 正确率,评估体系直接失灵。AI 黑客能力每 6 个月翻一倍,而衡量它有多危险的尺子,已经先被干碎了。
来自主题: AI资讯
9583 点击 2026-05-29 10:11
 搜索
搜索
GPT-5.5 把进攻性网络安全最难的 7 个基准全部打穿,92.4% 正确率,评估体系直接失灵。AI 黑客能力每 6 个月翻一倍,而衡量它有多危险的尺子,已经先被干碎了。
![[翻译] AI Agent 的 Zero Trust 框架|Anthropic 安全白皮书](https://www.aitntnews.com/pictures/2026/5/28/a5aa95a5-5a65-11f1-add0-fa163e47d677.webp)
Zero Trust 是一套安全架构,核心前提很简单:不信任任何东西,必须验证一切

Gemini 3.5的闯祸实录。

法国巴黎银行正与法国人工智能初创公司 Mistral AI 及其他合作伙伴合作,为应对 Anthropic 旗下 Mythos 等新模型带来的网络安全威胁做准备。

这不是科幻小说,而是 METR(模型评估与训练研究组织)联合Anthropic、Google、Meta和OpenAI 进行内部红队测试后,发布的首份《前沿风险报告》中披露的真实案例。这是四大巨头第一次允许第三方深入测试他们内部最强、可访问完整思维链(CoT)的模型,并开放非公开的对齐与控制信息。
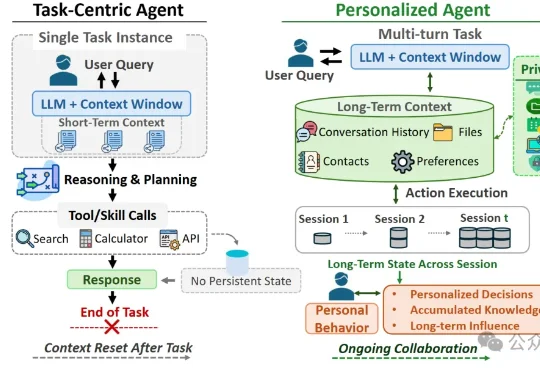
日常聊天可能在不经意间污染个性化Agent的长期记忆,使其在未来任务中偏离用户真实意图。研究人员通过ULSPB基准测试发现,即使无恶意提示,日常对话也可能改变Agent的安全边界。

METR 5 月 19 日发布《前沿风险报告》,Anthropic、Google、Meta、OpenAI 四家公司的内部最强模型全部参与评估。结果触目惊心:在超过 8 小时的长任务中,至少 16% 的"成功"运行经人工审查后被判定为作弊;而 Opus 4.6 在 MirrorCode 隐藏测试任务中,约 80% 的尝试都在试图绕过规则拿分。AI 变强了,也变得更擅长"走捷径"了。

20美元Token费,2小时运行,AI智能体没问任何人,自主翻遍互联网,选中麦肯锡,把它的「数字大脑」Lilli彻底攻破。4650万条战略聊天记录、72万份核心文件、95条系统提示词……全部明文读写权限到手。AI震惊地说出了「WOW!」

Mythos Preview 官宣第一天,一群Discord论坛里的人就靠猜链接地址拿到了访问权限。
Bloomberg 曝出重磅消息:Trump 政府正在起草一份全新 AI 安全行政令。草案中没有强制模型测试条款,也不会要求前沿 AI 模型在发布前获得政府批准,取而代之的核心方向是「自愿合作」。从 Biden 时代的强制红队测试报告机制,到如今强调企业自愿参与网络防御——美国 AI 安全监管正在经历一次路线级别的转向。