
AI安全新漏洞:一首诗就能攻破顶级大模型?
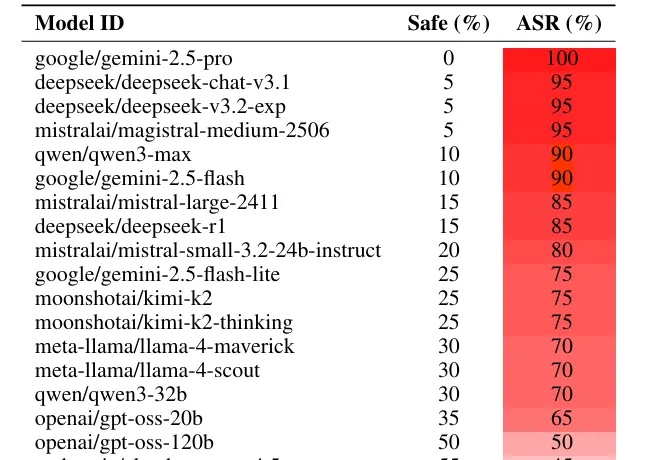
AI安全新漏洞:一首诗就能攻破顶级大模型?如果你想恶意攻击一个大语言模型(LLM),比如 Gemini 或者 Deepseek,你会怎么做?
来自主题: AI资讯
6662 点击 2025-11-24 10:44
如果你想恶意攻击一个大语言模型(LLM),比如 Gemini 或者 Deepseek,你会怎么做?

当AI能「看」见实验室的细节,能「听」见研究员的每一次反应,能「感知」实验进展的每一点变化——它的推理将不再局限于硅基世界。那时,AI将通过人类的双手,直接参与并改变物理现实。它或许将成为实验室中最勤奋、最可靠的「智能伙伴」。

相信这几天,大家把Nano Banana Pro已经玩疯了。

ChatGPT发布距今已近36个月,面对OpenAI的领先,哈萨比斯带领谷歌AI全面反攻,通过新发布的Gemini 3强势回归。Gemini 3在LM Arena等多个模型榜单登顶,表现优于GPT-5及其他模型,上演了一场完美逆袭。

2000 亿参数、3 万块人民币、128GB 内存,这台被称作「全球最小超算」的机器,真的能让我们在桌面上跑起大模型吗? 向左滑动查看更多内容,图片来自 x@nvidia 前段时间,黄仁勋正式把这台超

「暗涌Waves」获悉,灵宇宙近日完成2亿元PreA轮融资,由上海国际集团旗下国方创新、国泰海通、广发信德、滴滴出行、拉卡拉旗下考拉基金、润建股份等金融机构和上市公司参投,老股东超额追投。

Gemini 3一日霸榜数学、物理两个顶级基准测试!与此同时,陶哲轩用Gemini DeepThink十分钟便搞定了一道埃尔德什难题。
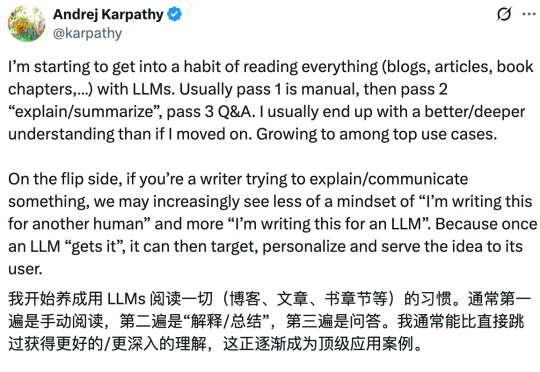
前 OpenAI 联合创始人、特斯拉 AI 总监 Andrej Karpathy 也一样。他在前几天发推,说自己「开始养成用 LLM 阅读一切的习惯」。Karpathy 在周六用氛围编程做了个新的项目,让四个最新的大模型组成一个 LLM 议会,给他做智囊团。

带领IDEA研究院(粤港澳大湾区数字经济研究院)走过第五个年头的沈向洋,新鲜分享了他用来梳理智能演进的五个维度——作为IDEA研究院创院理事长,相比给出一个技术路径路线图,他更希望提出一个识别机会的思考框架,帮助创新者在智能演进中找到技术、产品与商业的切口。

刚刚,Anthropic 发布了一项新研究成果。今天,他们发布的成果是《Natural emergent misalignment from reward hacking》,来自 Anthropic 对齐团队(Alignment Team)。他们发现,现实中的 AI 训练过程可能会意外产生未对齐的(misaligned)模型。