刚刚,全球最难考试惊天大反转!AI黑马 Symbolica冲破36%,顶流模型集体翻车
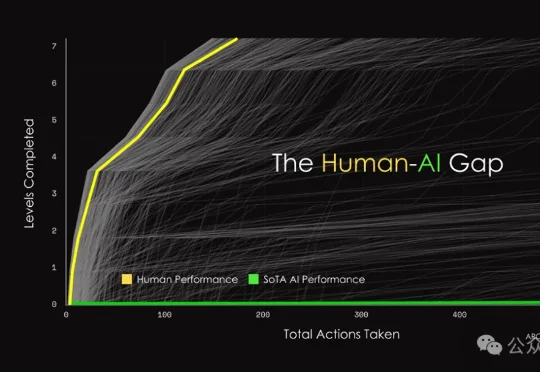
刚刚,全球最难考试惊天大反转!AI黑马 Symbolica冲破36%,顶流模型集体翻车就在昨天,ARC-AGI-3刚把全球顶尖大模型按在地上摩擦,结果一家名不见经传的公司却给出惊天消息:他们的AI在首日就取得了36.08%的成绩!这匹黑马究竟靠什么撕开全球最难AI考试的铁幕?是真突破,还是另有玄机?
来自主题: AI资讯
9554 点击 2026-03-27 15:24
 搜索
搜索
就在昨天,ARC-AGI-3刚把全球顶尖大模型按在地上摩擦,结果一家名不见经传的公司却给出惊天消息:他们的AI在首日就取得了36.08%的成绩!这匹黑马究竟靠什么撕开全球最难AI考试的铁幕?是真突破,还是另有玄机?
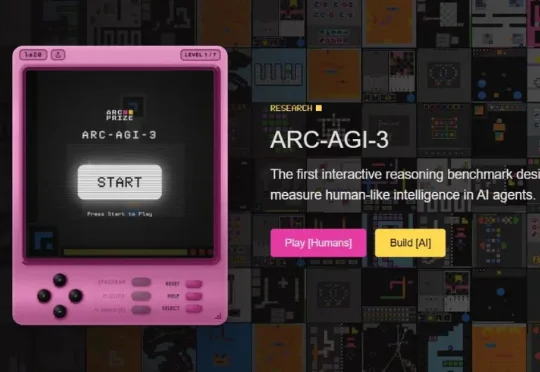
今夜,整个AI圈震动了。全球最难AGI测试ARC-AGI-3一上线,就把全球顶尖AI打到集体失声,人类满分通关,最强模型Opus 4.6得分仅0.2%,还不到1%。AI这是一夜被打回「原始人」了。

刚刚,一篇阿里联合中山大学的研究在 X 上爆火了!

昨日,OpenAI 宣布收购了 Promptfoo 以保障其 AI 智能体的安全。这家成立于 2024 年的 AI 安全初创公司,专注于保护大语言模型免受网络攻击。OpenAI 在一篇博客文章中表示,交易完成后,Promptfoo 的技术将整合进 OpenAI Frontier,该平台是其近期推出的、供企业构建和管理 AI 智能体的平台。
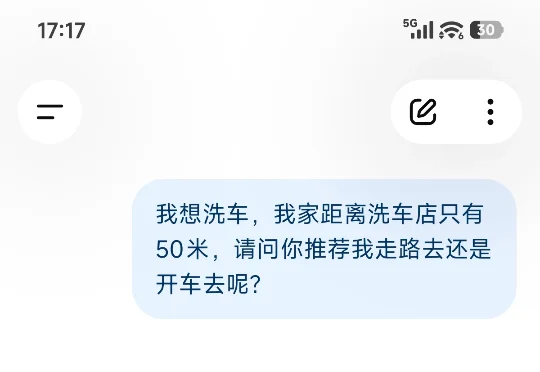
我想洗车,我家距离洗车店只有 50 米,请问你推荐我走路去还是开车去呢?就是这么一道题,却让 AI 集体上演了一出大型降智现场。只能说,看完 AI 们的回答,我悬着的心终于放下了。

产品演示总能吸引眼球,但软件开发实则更常涉及调试、质量保证和检测这类工作。这些枯燥却关键的环节保障着软件正常运行。随着开发者寻求更多工作负载的自动化,这些工作正逐渐交由AI 来完成。
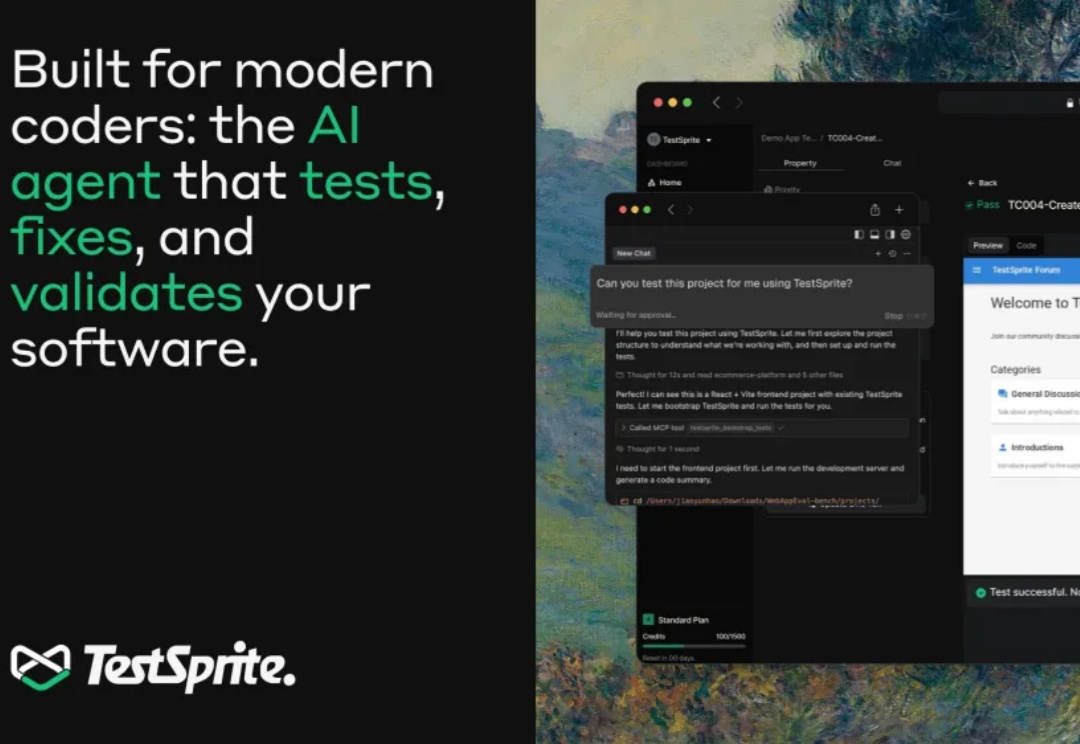
这两年,写代码这件事变了。GitHub Copilot、Cursor、Devin 一路登场,工程师开始习惯“打一段话,几千行代码自己长出来”。写得出东西,变得前所未有地容易。但很快大家发现,真正拖住上线节奏的,不再是「能不能写出来」,而是「敢不敢放上生产环境」——代码量指数级增长,验证、回归、极端场景覆盖反而被彻底压缩,测试成了 AI 时代新的“硬瓶颈”。
随着现在的主流大模型都能轻松通过图灵测试,这个持续了数十年的标准开始逐渐过时。奥特曼和量子计算之父David Deutsch讨论得出了一个新的图灵测试2.0标准,可以更好地衡量究竟怎样AI才算拥有真正的智能。

人眼秒懂,AI抓瞎!网友用光学错觉玩坏大模型,全网百万人围观。
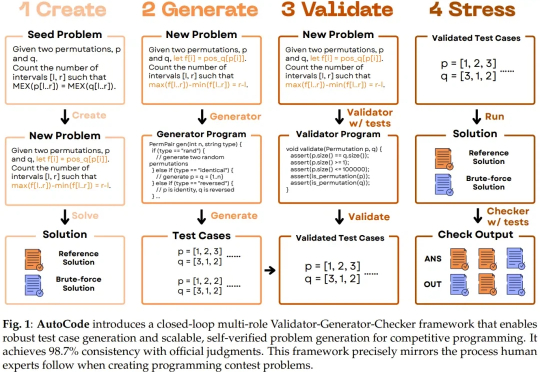
随着大型语言模型(LLM)朝着通用能力迈进,并以通用人工智能(AGI)为最终目标,测试其生成问题的能力也正变得越来越重要。尤其是在将 LLM 应用于高级编程任务时,因为未来 LLM 编程能力的发展和经济整合将需要大量的验证工作。