
万卡集群的AI数据中心,到底是如何运作的?
万卡集群的AI数据中心,到底是如何运作的?2024年7月22日凌晨,xAI创始人Elon Musk在推特上正式宣布,在凌晨4:20分正式启动了世界上最强的AI训练集群。 这个训练集群建设在美国田纳西州孟菲斯市,集合了10 万个液冷H100芯片。
来自主题: AI资讯
5991 点击 2024-11-08 09:56
 搜索
搜索
2024年7月22日凌晨,xAI创始人Elon Musk在推特上正式宣布,在凌晨4:20分正式启动了世界上最强的AI训练集群。 这个训练集群建设在美国田纳西州孟菲斯市,集合了10 万个液冷H100芯片。

LLM训练速度还可以再飙升20倍!英伟达团队祭出全新架构归一化Transformer(nGPT),上下文越长,训练速度越快,还能维持原有精度。

谁更懂AI训练,是人类还是AI自己?

所有模型都是通过在来自互联网的海量数据上进行训练来工作的,然而,随着人工智能越来越多地被用来生成充满垃圾信息的网页,这一过程可能会受到威胁。
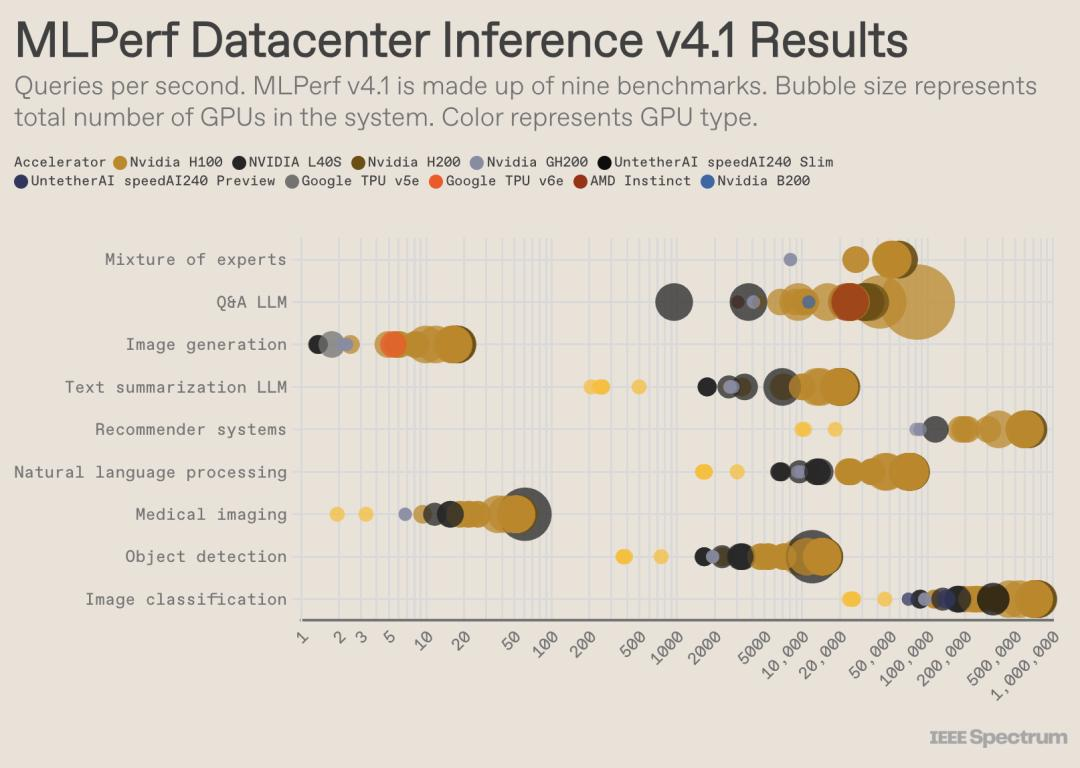
虽然英伟达的GPU在AI训练领域的主导地位仍然难以撼动,但似乎有迹象表明,在AI推理方面,竞争对手正在迎头赶上这家科技巨头,尤其是在能效方面。

最近,Meta的多个工程团队联合发表了一篇论文,描述了在引入基于GPU的分布式训练时,他们如何为其「量身定制」专用的数据中心网络。

计算机是二进制的世界,所以浮点数也是用二进制来表示的,与整型不同的是,浮点数通过3个区间来表示:

反垄断案败诉,谷歌或将面临「分家」,一旦与Chrome和安卓操作系统解绑,谷歌该何去何从?

7月上旬,多位在字节跳动旗下免费阅读平台番茄小说更新作品的网络文学作者,收到了后台系统发送的“AI训练补充协议”签署提醒。其中提到,一旦签署,其作品内容及相关信息,将被用于平台AI模型训练或其他技术研发应用场景。

家处某二线城市的明明,在当地一所普通高校就读,还有一年就要大学毕业的他,害怕毕业后不好找工作,最近花了2万多元在当地培训机构报名了“AI训练师”的课程。 AI训练师指“使用智能训练软件,在人工智能产品实际使用过程中进行数据库管理、算法参数设置、人机交互设计、性能测试跟踪及其他辅助作业的人员”,可以简单理解为,所有与AI训练相关的职业,这一职业,在2020年被纳入国家职业分类目录。