

AI主战场,万卡是标配:国产GPU万卡万P集群来了!
AI主战场,万卡是标配:国产GPU万卡万P集群来了!Scaling Law 持续见效,让算力就快跟不上大模型的膨胀速度了。「规模越大、算力越高、效果越好」成为行业圭皋。主流大模型从百亿跨越到 1.8 万亿参数只用了1年,META、Google、微软这些巨头也从 2022 年起就在搭建 15000 卡以上的超大集群。「万卡已然成为 AI 主战场的标配。」
来自主题: AI资讯
7976 点击 2024-07-05 00:11
Scaling Law 持续见效,让算力就快跟不上大模型的膨胀速度了。「规模越大、算力越高、效果越好」成为行业圭皋。主流大模型从百亿跨越到 1.8 万亿参数只用了1年,META、Google、微软这些巨头也从 2022 年起就在搭建 15000 卡以上的超大集群。「万卡已然成为 AI 主战场的标配。」

只有10亿参数的xLAM-1B在特定任务中击败了LLM霸主:OpenAI的GPT-3.5 Turbo和Anthropic的Claude-3 Haiku。上个月刚发布的苹果智能模型只有30亿参数,就连奥特曼都表示,我们正处于大模型时代的末期。那么,小语言模型(SLM)会是AI的未来吗?
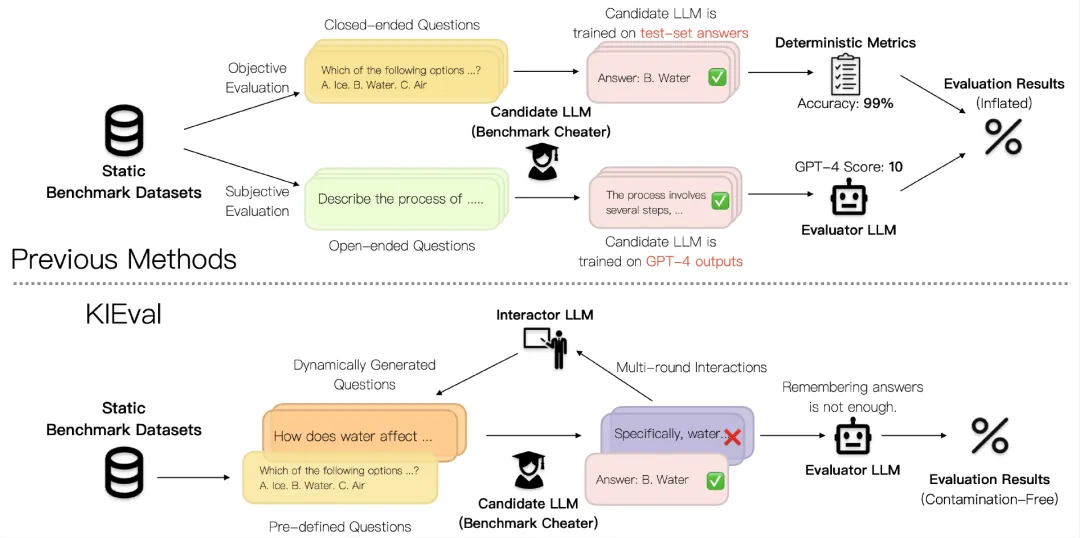
当前大语言模型(LLM)的评估方法受到数据污染问题的影响,导致评估结果被高估,无法准确反映模型的真实能力。北京大学等提出的KIEval框架,通过知识基础的交互式评估,克服了数据污染的影响,更全面地评估了模型在知识理解和应用方面的能力。

神经网络通常由三部分组成:线性层、非线性层(激活函数)和标准化层。线性层是网络参数的主要存在位置,非线性层提升神经网络的表达能力,而标准化层(Normalization)主要用于稳定和加速神经网络训练,很少有工作研究它们的表达能力,例如,以Batch Normalization为例

在盖茨眼里,AI对于计算机交互的革命还没来到,但是Scaling Law似乎已经看到尽头了。

Gen-3 Alpha终于开启测试了!第一时间拿到内测资格的网友们,纷纷放出各种炸裂的demo,看得出Gen-3在生成质量完全跃升。不过,模型有时无法理解物理世界的缺陷,依然存在。

本文根据极客公园创始人&总裁 张鹏在 Founder Park AGI Palyground 2024 上的演讲整理。
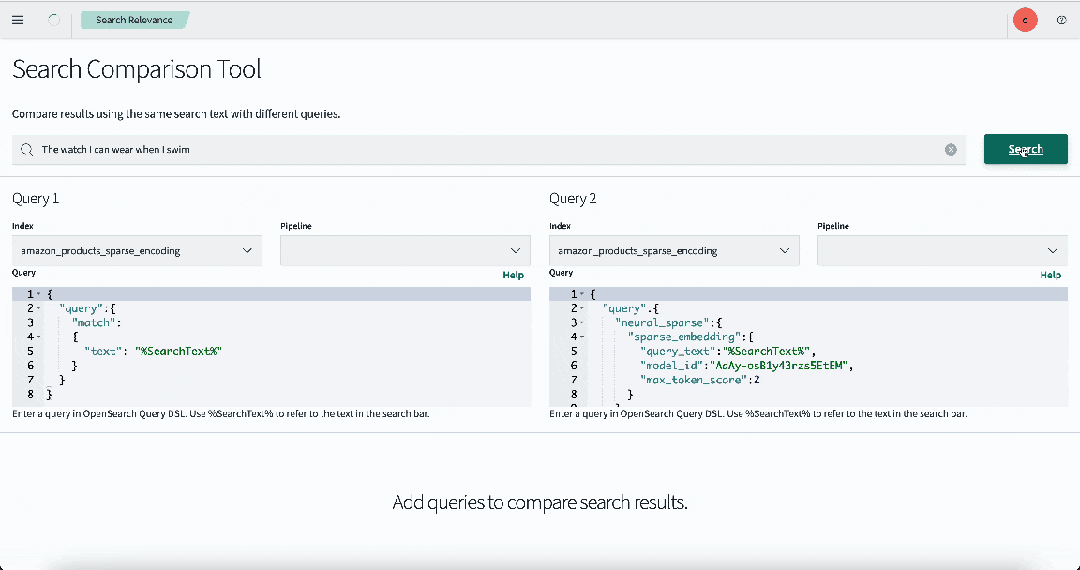
自从大模型爆火以来,语义检索也逐渐成为一项热门技术。尤其是在 RAG(retrieval augmented generation)应用中,检索结果的相关性直接决定了 AI 生成的最终效果。

字节跳动探索AI硬件业务,屡试不舍。

背后“包工头”,身价估值过百亿美元。