
爆火论文颠覆RL认知!「错误奖励」让LLM推理暴涨24.6%,学界惊了
爆火论文颠覆RL认知!「错误奖励」让LLM推理暴涨24.6%,学界惊了来自华盛顿大学、AI2、UC伯克利研究团队证实,「伪奖励」(Spurious Rewards)也能带来LLM推理能力提升的惊喜。
来自主题: AI技术研报
8641 点击 2025-05-29 10:18
 搜索
搜索
来自华盛顿大学、AI2、UC伯克利研究团队证实,「伪奖励」(Spurious Rewards)也能带来LLM推理能力提升的惊喜。

Google I/O 2025 结束后,Google CEO Sundar Pichai 接受了《The Verge》主编专访,这也是双方连续第三年于 I/O 后展开对谈,而今年的背景更为特殊:Gemini 模型全面更新、多模态生成工具 Veo3 登场、AI 功能深度融入 Android 与 XR 平台,Google 展现出前所未有的产品化信心。
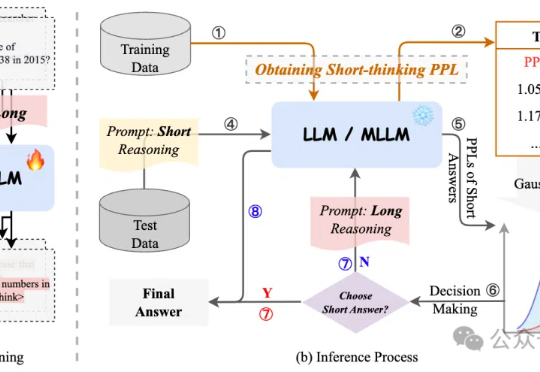
过度依赖CoT思维链推理会降低模型性能,有新解了! 来自字节、复旦大学的研究人员提出自适应推理框架CAR,能根据模型困惑度动态选择短回答或详细的长文本推理,最终实现了准确性与效率的最佳平衡。
2025 年快要过半,今年上半年 AI 搜索、AI 深度研究类产品可谓是欣欣向荣。
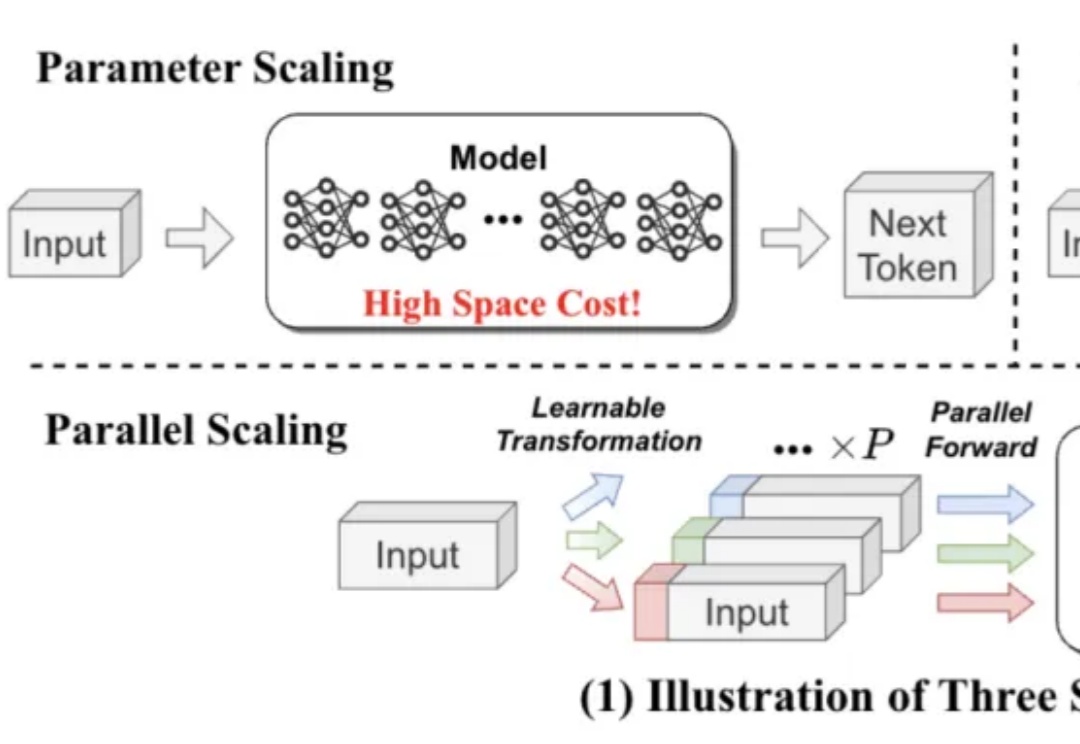
既能提升模型能力,又不显著增加内存和时间成本,LLM第三种Scaling Law被提出了。

2025年上半年,Agent成为大模型领域讨论最多的主题之一。
在产品不断被「AI 化」的浪潮中,连浏览器也无法幸免。

“月之暗面给了我AGI信仰,但Kimi不是唯一的路。”

在大型推理模型(例如 OpenAI-o3)中,一个关键的发展趋势是让模型具备原生的智能体能力。具体来说,就是让模型能够调用外部工具(如网页浏览器)进行搜索,或编写/执行代码以操控图像,从而实现「图像中的思考」。
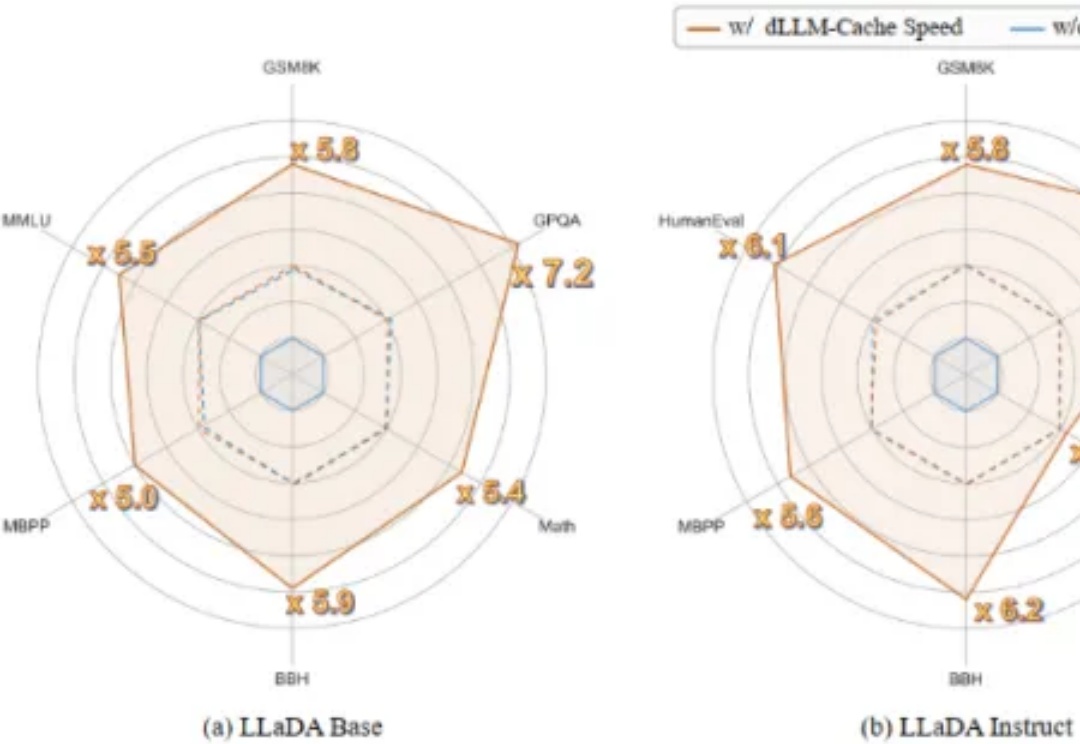
首个用于加速扩散式大语言模型(diffusion-based Large Language Models, 简称 dLLMs)推理过程的免训练方法。