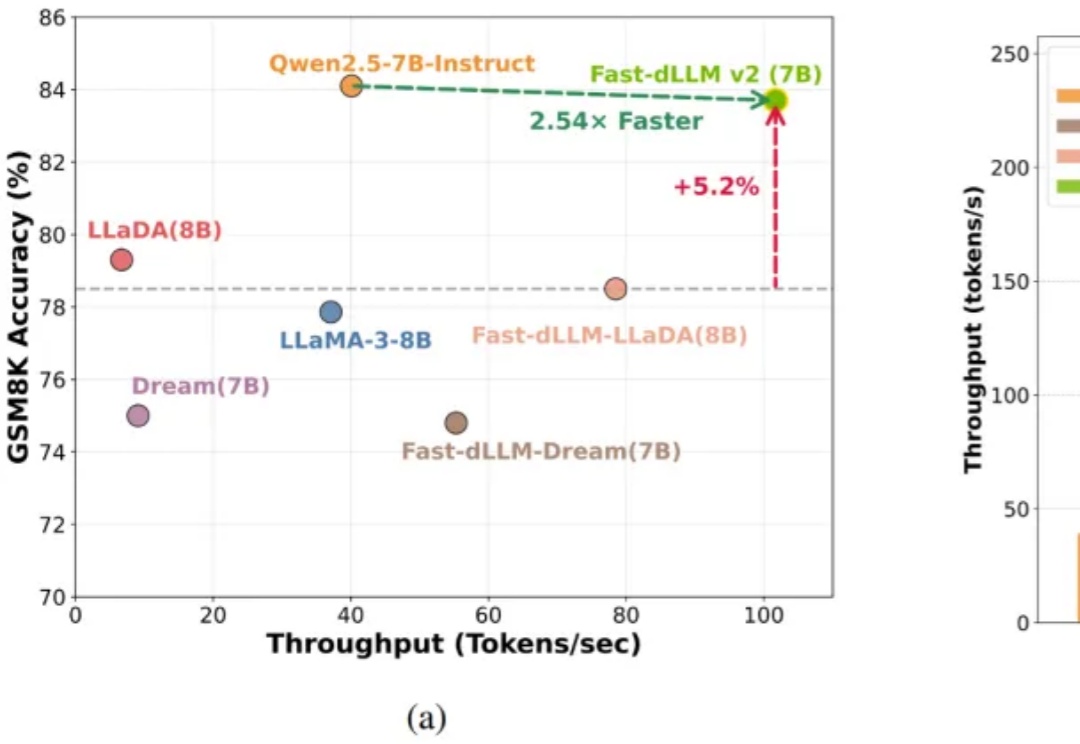
NVIDIA港大MIT联合推出Fast-dLLM v2:端到端吞吐量提升2.5倍
NVIDIA港大MIT联合推出Fast-dLLM v2:端到端吞吐量提升2.5倍自回归(AR)大语言模型逐 token 顺序解码的范式限制了推理效率;扩散 LLM(dLLM)以并行生成见长,但过去难以稳定跑赢自回归(AR)模型,尤其是在 KV Cache 复用、和 可变长度 支持上仍存挑战。
来自主题: AI技术研报
8267 点击 2025-10-27 16:46
 搜索
搜索
自回归(AR)大语言模型逐 token 顺序解码的范式限制了推理效率;扩散 LLM(dLLM)以并行生成见长,但过去难以稳定跑赢自回归(AR)模型,尤其是在 KV Cache 复用、和 可变长度 支持上仍存挑战。

十月,《纽约时报》发表了题为《The A.I. Prompt That Could End the World》(《那个可能终结世界的 AI 提示词》)的文章。作者 Stephen Witt 采访了多位业内人士:有 AI 先驱,图灵奖获奖者 Yoshua Bengio;以越狱测试著称的 Leonard Tang;以及专门研究模型欺骗的 Marius Hobbhahn。

近日,有消息称,由百度集团前副总裁景鲲(Eric Jing)创立的AI搜索公司Genspark即将完成一笔2亿美元的新融资,投后估值预计达到10亿美元。
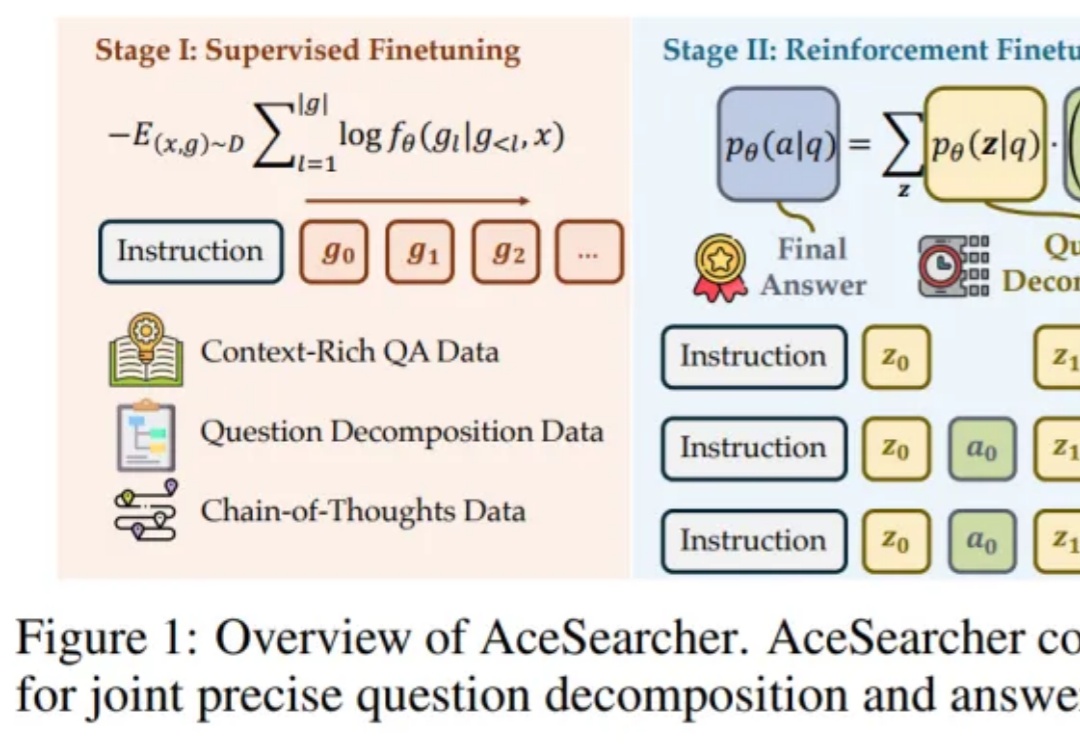
如何让一个并不巨大的开源大模型,在面对需要多步检索与复杂逻辑整合的问题时,依然像 “冷静的研究员” 那样先拆解、再查证、后归纳,最后给出可核实的结论?

看似无害的「废话」,也能让AI越狱?在NeurIPS 2025,哥大与罗格斯提出LARGO:不改你的提问,直接在模型「潜意识」动手脚,让它生成一段温和自然的文本后缀,却能绕过安全防护,输出本不该说的话。
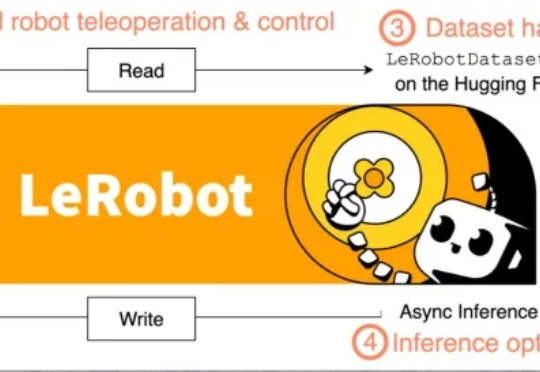
HuggingFace 与牛津大学的研究者们为想要进入现代机器人学习领域的新人们提供了了一份极其全面易懂的技术教程。这份教程将带领读者探索现代机器人学习的全景,从强化学习和模仿学习的基础原理出发,逐步走向能够在多种任务甚至不同机器人形态下运行的通用型、语言条件模型。
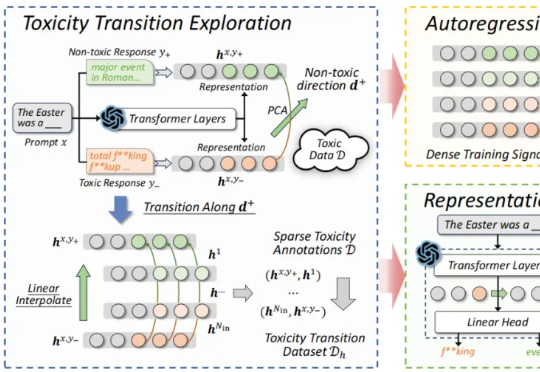
近期,来自北航等机构的研究提出了一种新的解决思路:自回归奖励引导表征编辑(ARGRE)框架。该方法首次在 LLM 的潜在表征空间中可视化了毒性从高到低的连续变化路径,实现了在测试阶段进行高效「解毒」。

500 万用户、八位数年经常性收入、日均新增 2 万用户——对于 2024 年初由两名 20 岁大学生 Rudy Arora 与 Sarthak Dhawan 创办的初创公司 Turbo AI 而言,这些数据堪称亮眼。对于刚达到法定饮酒年龄(美国为 21 岁)的年轻人来说,这样的成绩更显不可思议。

几个月前,和 OpenAI“星际之门”(Stargate)项目的合作,让 Crusoe 这家公司一夜成名。据创始人介绍,公司的名字灵感来源于小说《鲁滨逊漂流记》(Robinson Crusoe),正像鲁滨逊在荒岛上竭力利用全部资源来生存一样,这家公司也试图最大化利用废弃或闲置能源,并通过算力来释放其价值。
刚刚,计算机科学家 Yoshua Bengio 创造了新的历史,成为 Google Scholar 上首个引用量超过 100 万的人!打个直观的比方,如果我们将每一篇引用论文打印成册(假设平均厚度为 1 毫米),然后将它们垂直堆叠起来,这座由知识构成的纸塔将高达 1000 米。这是什么概念?它将轻松超越目前的世界最高建筑,即 828 米的迪拜哈利法塔。