
【从0到1】独立游戏开发者AI指南
【从0到1】独立游戏开发者AI指南我们正身处独立游戏的黄金时代。
来自主题: AI资讯
11767 点击 2026-01-13 12:02
我们正身处独立游戏的黄金时代。

据外媒报道,即将在2026年第一季度批准进口H200显卡。

当代花钱上班的形式有很多:买咖啡提神、怕迟到打专车、下午来两杯奶茶、还有买各种会员和订阅服务。
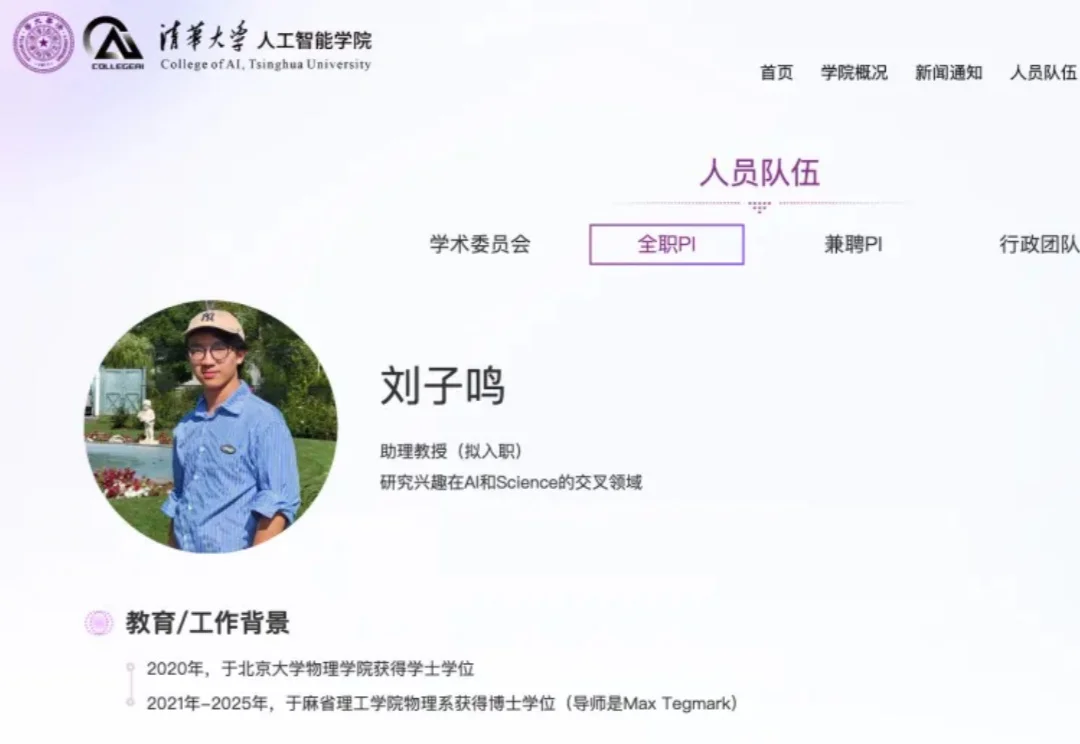
爆火神经网络架构KAN一作,毕业新去向已获清华官网认证: 刘子鸣,拟于今年9月加入清华大学人工智能学院,任助理教授。
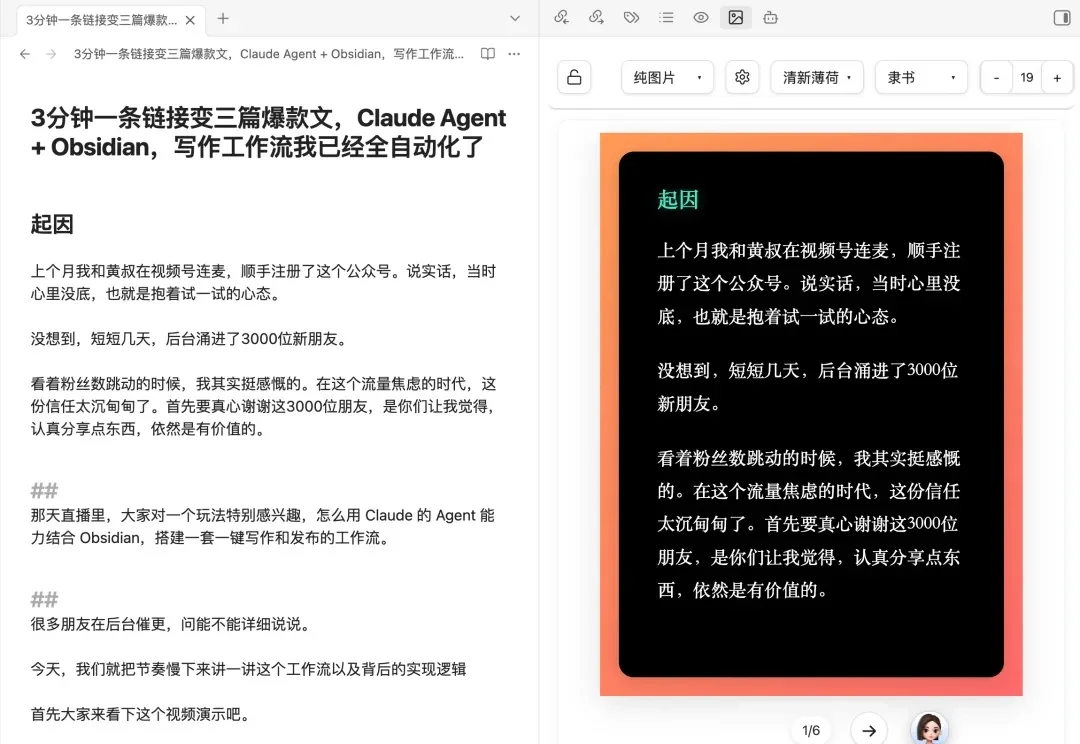
上个月我和黄叔在视频号连麦,顺手注册了这个公众号。说实话,当时心里没底,也就是抱着试一试的心态。

机器人终于迎来自己的「iOS时刻」,全球首个具身Agentic OS来了:不是装个更聪明的大模型,而是给机器人配上一套真正的「操作系统」。

清晨的城市边缘,一辆理想L9的后备箱缓缓打开。一只被家人叫做“大头BoBo”的Vbot超能机器狗轻盈跃下,开始了一天的郊游。它无需任何遥控指令,自主识别出主人一家,流畅地调整步伐跟在身侧。

2025年是字节App工厂迎来收获的一年:豆包以过亿日活领跑AI应用赛道,红果短剧月活迈过2亿门槛,汽水音乐月活数据开始逼近网易云音乐,曾经的“弃子”多闪重回社交榜榜首……
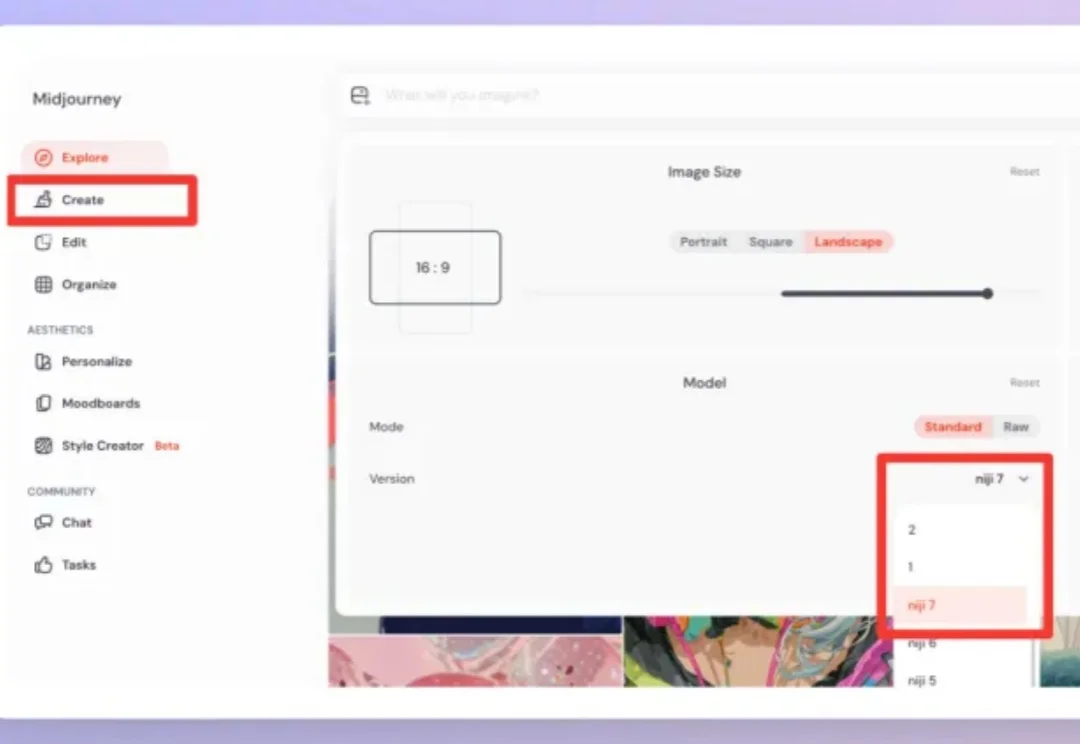
嗨大家好!我是阿真! 前顶流Midjourney终于姗姗来迟,在1月9日推出了Niji V7 。

未来不远(Futuring Robot)正式宣布完成 2 亿元的天使轮融资,目前已经完成家庭通用机器人领域端到端模型落地,真实家庭实测,C 端商业化等重大阶段。