
碾压人类的超级AI,赞助棋界巅峰大赛了
碾压人类的超级AI,赞助棋界巅峰大赛了在陈思诚导演、上映一个多月便揽下3亿票房的谍战片《解密》中,主人公容金珍是一位民国时期的数学天才,大学毕业后本已开始从事“机器人脑”的研究工作,却在机缘巧合之下被谍报机关招募,自此一生奉献给了密码破译。
来自主题: AI资讯
10379 点击 2024-09-26 11:00
 搜索
搜索
在陈思诚导演、上映一个多月便揽下3亿票房的谍战片《解密》中,主人公容金珍是一位民国时期的数学天才,大学毕业后本已开始从事“机器人脑”的研究工作,却在机缘巧合之下被谍报机关招募,自此一生奉献给了密码破译。

在电影《天下无贼》中,葛优扮演的黎叔有这样一句经典的台词,「二十一世纪什么最贵?人才!」而随着人工智能行业进入到大模型时代,这一问题的答案已然变成了「算力」。
就在刚刚,创业成功的27岁亿万富翁Alexandr Wang宣布—— Scale AI的年化收入,几乎达到了10亿美元! 这个数字,足够震惊整个硅谷的。

AI时代来了,叠加经济下行,越来越多的独立开发者渴望ARR百万美元的故事。

今天,Sam Altman很罕见的在他的个人网站上发布了一篇推文:The Intelligence Age(智能时代)。

SocialAI App,让AI机器人成为你的粉丝和互动者。
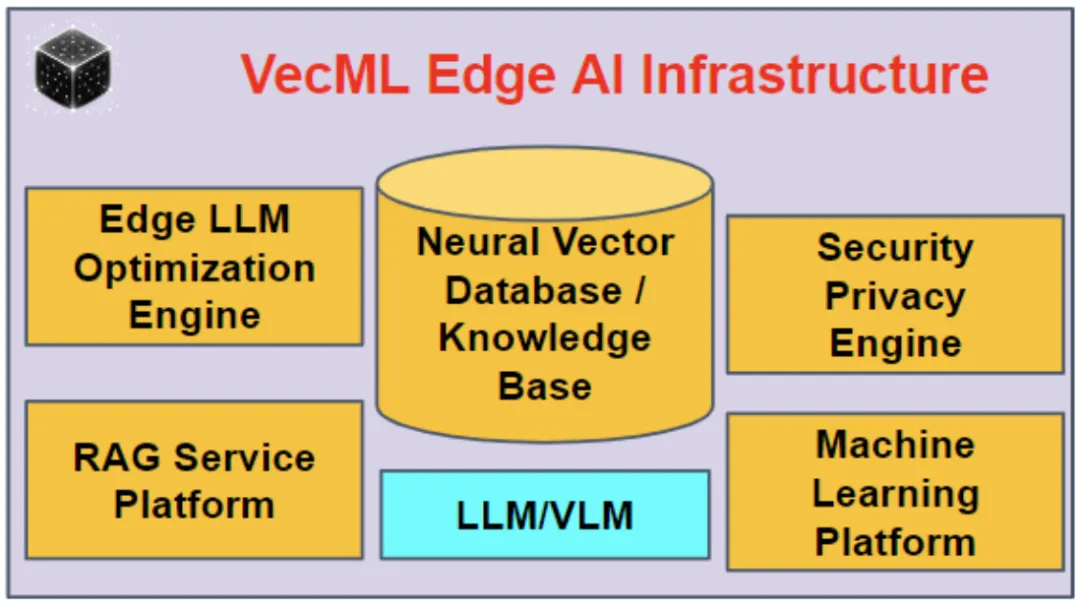
《智能涌现》独家获悉,前百度研究院副院长李平的新创业公司VecML,近期已经完成了产品的探索和初步研发。值得注意的是,VecML近期还邀请到了前雅虎和Ebay首席科学家、前Walmart副总裁,和前微软技术高管Jan Pedersen博士,出任VecML首席战略官(CSO)。
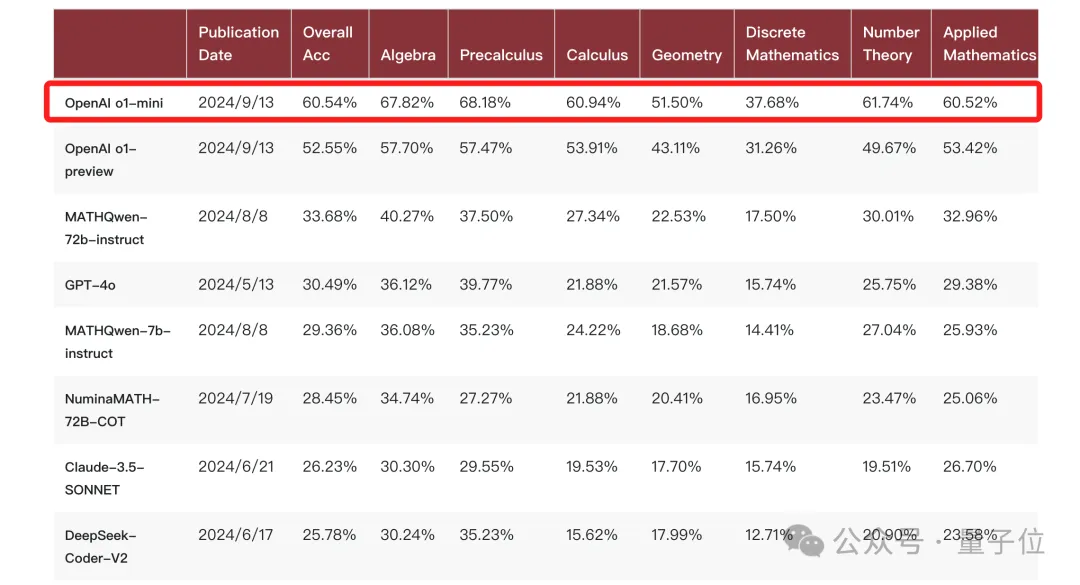
OpenAI的新模型o1,可谓是开启了Scaling Law的新篇章——

GPT-4o 读万卷书,「o1」行万里路。

这是关于垂直 SaaS (Vertical SaaS)的两部分系列的第一部分。