
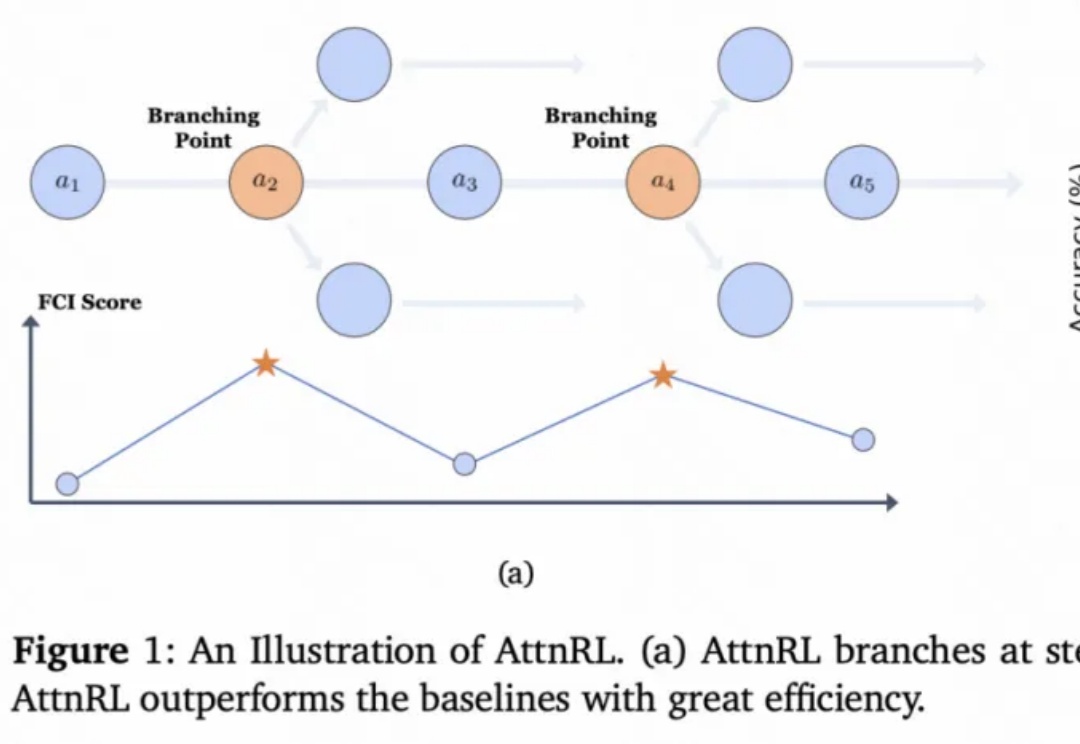
清华、快手提出AttnRL:让大模型用「注意力」探索
清华、快手提出AttnRL:让大模型用「注意力」探索从 AlphaGo 战胜人类棋手,到 GPT 系列展现出惊人的推理与语言能力,强化学习(Reinforcement Learning, RL)一直是让机器「学会思考」的关键驱动力。
来自主题: AI技术研报
8228 点击 2025-10-22 11:46
从 AlphaGo 战胜人类棋手,到 GPT 系列展现出惊人的推理与语言能力,强化学习(Reinforcement Learning, RL)一直是让机器「学会思考」的关键驱动力。

就在最新的Nature新刊中,DeepSeek一举成为首家登上《Nature》封面的中国大模型公司,创始人梁文锋担任通讯作者。纵观全球,之前也只有极少数如DeepMind者,凭借AlphaGo、AlphaFold有过类似荣誉。

一群机械臂手忙脚乱地自己干活,彼此配合、互不碰撞。

在AI以指数级加速迈向ASI的2025年,新智元迎来十周年历史时刻,将于9月7日在北京中关村软件园举办盛大峰会。大会以「新天终启,万象智生」为主题,汇聚百度王海峰、英伟达赖俊杰、百川智能王小川、昆仑万维方汉、未来智能胡郁等多位重量级嘉宾,共同探讨芯片、大模型、Agent、具身智能及医疗智能等全球ASI最前沿突破,展望ASI重塑人类社会的恢弘篇章。
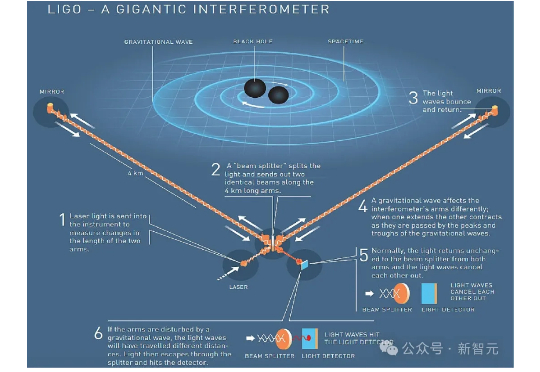
AI设计出人类看不懂的实验,却成功破解物理学数十年难题,大幅提升LIGO灵敏度。寻找暗物质,解读宇宙公式都不在话下,AI辅助物理学发现的新时代已经到来。
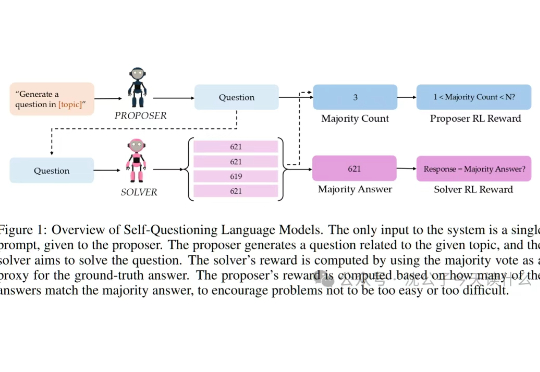
一句话概括,本文探索了语言模型的终极内卷模式:不再依赖人类投喂,通过“自问自答”的左右互搏,硬生生把自己逼成了学霸。AlphaGo下棋我懂,这大模型自己给自己出数学题做就有点离谱了,堪称AI界的“闭关修炼”,出关即无敌。

融资10亿美元,要在开源上挑战Deepseek! 前谷歌DeepMind成员、AlphaGo开发者创立Reflection AI,致力于开发开源大语言模型。
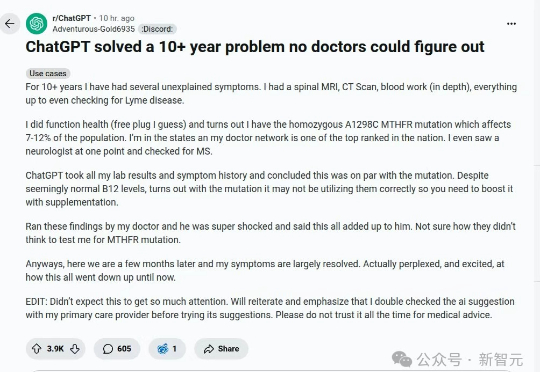
十多年,患者求医无果、束手无策,但将所有病史输入ChatGPT,病因竟被一眼识破:基因突变!微软、OpenAI等巨头的医疗AI已悄然登场,准确率超越专业医生!未来的医疗,或将彻底改写!
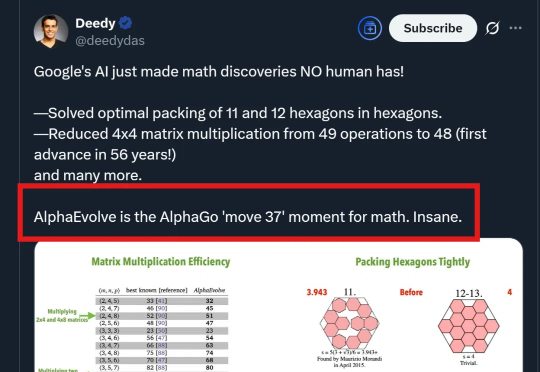
数学能力几乎和AlphaGo的围棋水平一样?!

太疯狂了,AlphaGo的「第37步」时刻,已经来临。谷歌的AlphaEvolve,让我们从此进入AI创造科学的时代,人类科研将彻底颠覆!背后的研究者也首次接受采访,揭秘研究过程中的一些惊人细节。