68页论文再锤大模型竞技场!Llama4发布前私下测试27个版本,只取最佳成绩
68页论文再锤大模型竞技场!Llama4发布前私下测试27个版本,只取最佳成绩大模型竞技场的可信度,再次被锤。
来自主题: AI技术研报
9450 点击 2025-05-02 17:56
 搜索
搜索
大模型竞技场的可信度,再次被锤。

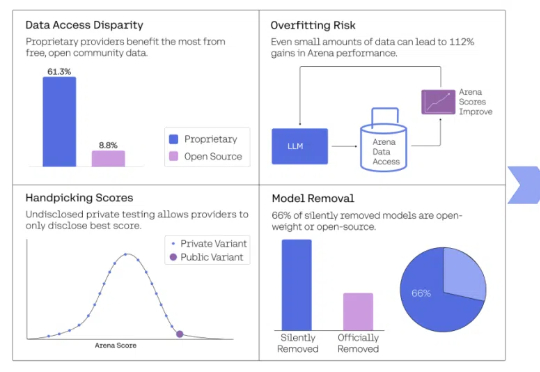
刚刚,LMArena陷入了巨大争议,斯坦福MIT和Ai2等的研究者联手发论文痛斥,这个排行榜已经被Meta等公司利用暗中操作排名!Karpathy也下场帮忙锤了一把。而LMArena官方立马回应:论文存在多处错误,指控不实。
作为学术研究项目,原加州大学伯克利分校的Chatbot Arena,其网站已成为访客试用新人工智能模型的热门平台,现正转型为独立公司。
Llama 4真要被锤爆了,这次是大模型竞技场(Chatbot Arena)官方亲自下场开怼:
在数学推理中,大语言模型存在根本性局限:在美国数学奥赛,顶级AI模型得分不足5%!来自ETH Zurich等机构的MathArena团队,一下子推翻了AI会做数学题这个神话。
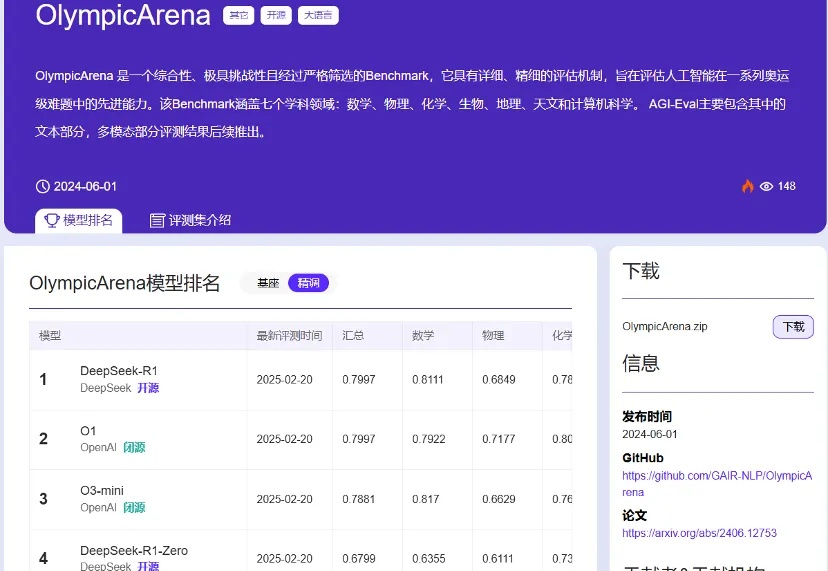
为了进一步挑战AI系统,大家已经开始研究一些最困难的竞赛中的问题,特别是国际奥林匹克竞赛和算法挑战。
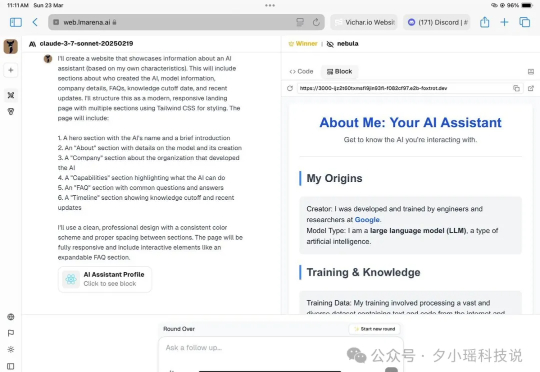
哎!最近推特上的网友在LMSYS Arena 发现了个泄漏的大模型 Nebula,效果据说特别好,打败了o1、o3mini、Claude3.7 Thinking等等模型:网友们通过询问和分析 API,发现这似乎是谷歌正在秘密演练的新推理模型!推测可能是 Google Gemini 2.0 Pro Thinking:
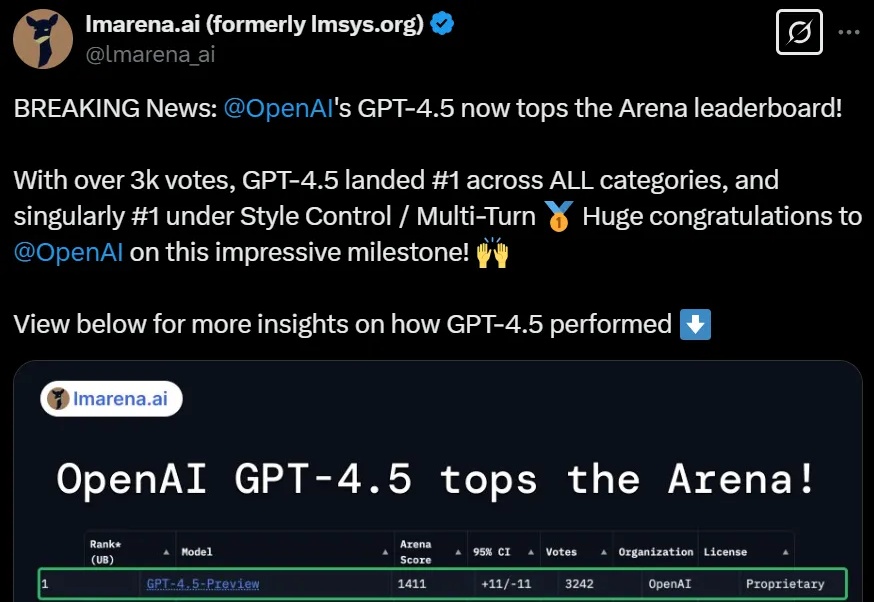
在知名AI排行榜LM Arena中,曾全班垫底的GPT-4.5竟一度拿下第一?甚至在数学、编程等领域表现优异,这反常的表现让网友们一度质疑:大模型竞技场莫非被LLM操纵了?不过网友们在实测后却惊讶发现,GPT-4.5的确情商爆表,不用推理就能理解人类的深层意图!
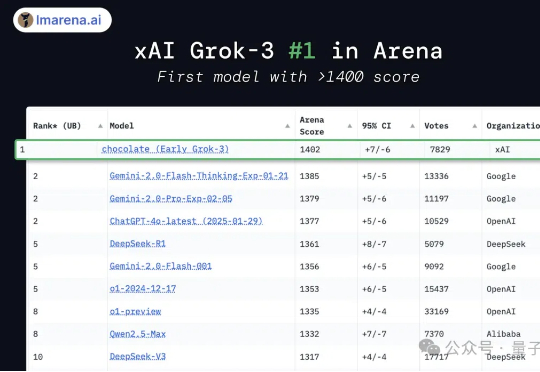
刚刚,马斯克xAI的Grok 3终于亮相(超300万人次围观)!一出道即巅峰,竞技场(lmarena.ai)官方给出了这样的评价:Grok 3是首个突破1400分的模型,并且在所有类别中排名第一。
还在用枯燥的数学题和编程题测试AI?落伍啦!现在,打游戏就能测出AI的真实力。GameArena团队打造的Roblox新游《AI空间逃脱》,让你在紧张刺激的密室逃脱中,顺便就把AI模型的推理能力给评估了。这不仅比传统测试方法更有趣,还能生成宝贵的游戏数据,帮助开发者更全面地了解AI的强项与短板。