
Manus被Reverse CFIUS调查之后,“AI套壳”类产品值得关注的X个问题
Manus被Reverse CFIUS调查之后,“AI套壳”类产品值得关注的X个问题从今年4月底Manus完成了Benchmark领投的新一轮融资之后,市场上一直在关注Manus的Reverse CFIUS问题——很多人都等着看美国监管部门会不会枪打出头鸟,让Manus成为其第一个实际判罚案例
来自主题: AI监管政策
13419 点击 2025-07-12 19:11
 搜索
搜索
从今年4月底Manus完成了Benchmark领投的新一轮融资之后,市场上一直在关注Manus的Reverse CFIUS问题——很多人都等着看美国监管部门会不会枪打出头鸟,让Manus成为其第一个实际判罚案例

你有没有想过,为什么在这个云计算和AI横行的时代,PDF文档处理依然是企业最大的痛点之一?想象一下这样的场景:一份包含数百页的贷款申请文档躺在银行系统里,等待人工审核,而申请人只能苦苦等待几天甚至几周才能知道结果。与此同时,医院里的医疗记录还在用打印机输出,然后手工传递给下一个医生。

2025 年 6 月 23 日,由 GMI Cloud 联合 InfoQ 举办的 “2025 AI 应用出海年中洞察暨 GMI Cloud 新品发布会” 在线上举行。
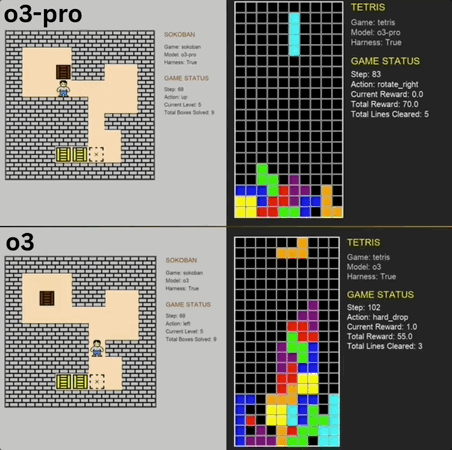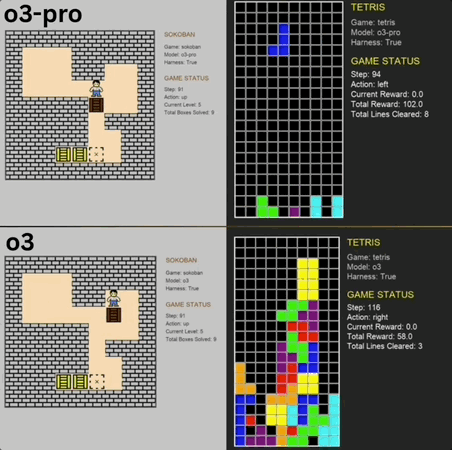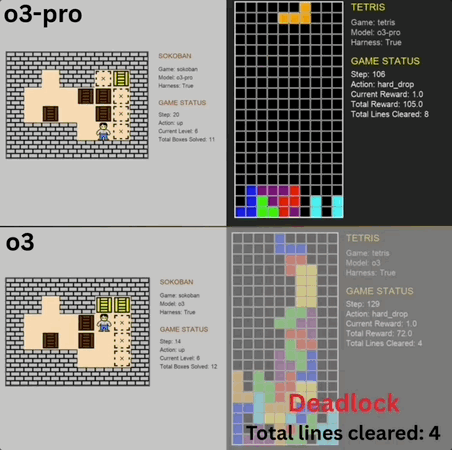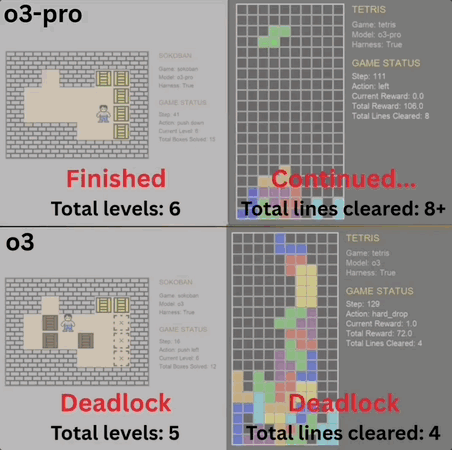
推箱子、俄罗斯方块……这些人类的经典怀旧小游戏,也成大模型benchmark了。 o3-pro刚刚也挑战了这两款游戏,而且表现还都不错,直接突破了benchmark上限

Benchmark 合伙人 Eric Vishria 最近跟 Banana Capital 合伙人 Turner Novak 在其播客 The Peel 做了一个非常精彩的对话,这是我最近觉得非常不错的一个访谈。
两年半前,Liam Fedus 曾参与 ChatGPT 的研发团队,掀起了人工智能热潮。如今他加入了日益壮大的 OpenAI 前员工创业阵营,乘着 AI 投资风口创立自己的企业。

进入2025年以来, AI Agent的发展明显提速。5月6日,OpenAI宣布以30亿美元收购 Windsurf;编程工具Cursor的母公司Anysphere也获得了9亿美元的融资,估值高达90亿美元;号称中国第一个通用AI Agent的Manus在五月也获得了硅谷老牌风险投资公司Benchmark领投的7500万美元的融资;

随着基础模型的快速发展和 AI Agent 进入规模化应用阶段,被广泛使用的基准测试(Benchmark)却面临一个日益尖锐的问题:想要真实地反映 AI 的客观能力正变得越来越困难。

根据TechCrunch和Semafor等报道,美国财政部正在审查Benchmark Capital对中国初创公司Manus AI的7500万美元投资,据两位知情人士透露,这已经反映出中美之间的科技竞争已经升级到政治层面。
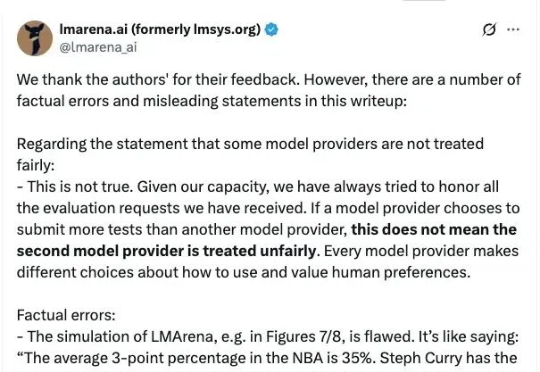
AI研究中,基准测试(benchmark)和排行榜在评估模型性能上扮演着关键角色。