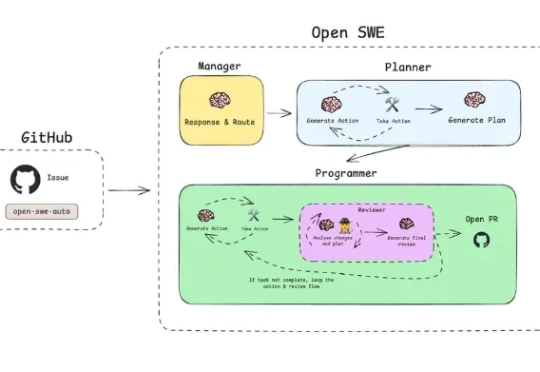
LangChain 推出开源异步编码智能体 Open SWE
LangChain 推出开源异步编码智能体 Open SWELangChain 发布了 Open SWE,这是一个完全开源的异步编码智能体,旨在在云端运行并处理复杂的软件开发任务。公司表示,Open SWE 代表了从实时“副驾驶”助手向更自主、长期运行的智能体的转变,这些智能体可以直接集成到开发人员现有的工作流程中。
来自主题: AI资讯
8741 点击 2025-08-24 12:27
 搜索
搜索
LangChain 发布了 Open SWE,这是一个完全开源的异步编码智能体,旨在在云端运行并处理复杂的软件开发任务。公司表示,Open SWE 代表了从实时“副驾驶”助手向更自主、长期运行的智能体的转变,这些智能体可以直接集成到开发人员现有的工作流程中。

近年来,以多智能体系统(MAS)为代表的研究取得了显著进展,在深度研究、编程辅助等复杂问题求解任务中展现出强大的能力。现有的多智能体框架通过多个角色明确、工具多样的智能体协作完成复杂任务,展现出明显的优势。

AI药物研发领域,又一家黑马公司诞生了!就在今天,AI制药公司Chai Discovery宣布完成7000万美元(约合人民币5亿元)的A轮融资。就在今天,AI制药公司Chai Discovery宣布完成7000万美元(约合人民币5亿元)的A轮融资。
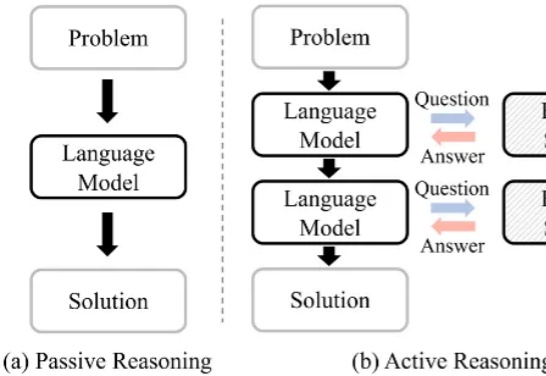
大语言模型(Large Language Model, LLM)在复杂推理任务中表现卓越。借助链式思维(Chain-of-Thought, CoT),LLM 能够将复杂问题分解为简单步骤,充分探索解题思路并得出正确答案。LLM 已在多个基准上展现出优异的推理能力,尤其是数学推理和代码生成。

6月30日,OpenAI支持的Chai Discovery推出Chai-2,这款多模态生成模型展现出强大的抗体设计能力,一经发布便引起巨大轰动。

还在质疑AI生物制药「纸上谈兵」?Chai-2已经把抗体设计成功率从0.1%提升到16%,而且还是零样本!不仅是技术奇迹,这更是范式革命:下一代药神,可能不是生物学博士,而是提示词工程师。

今年最火的视频 AI 视频模型 Veo3 ,最近又迎来更新,能让图片开口说话了。Google CEO Sundar Pichai 发 X 说,自从五月 Google 开发者大会以来,用户已经使用 Veo 3 创建了超过 4000 万的视频。

当LangChain在6月23日发布那篇著名的Context Engineering博客时,IBM Research的研究者们早在10天前就已经用严格的学术实验证明了这套方法的有效性。
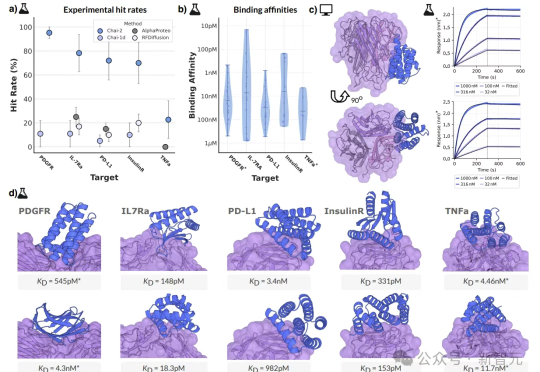
10元一块实验板、2周时间、零样本命中率16%,这不是科幻,而是AI创造的生物技术奇迹!AI制药的拐点,或许已经到来——如果还在用老方法,那你可能已经被这场「淘汰赛」边缘化了……
一个叫 Chai-2 的 AI 技术,听说它让制药业的老板们都坐不住了。啥?制药业跟你没关系?别急,故事才刚开始,慢慢聊。