Anthropic被逼急了!亲生龙虾意外曝光,Karpathy:这就是Claude Claw
Anthropic被逼急了!亲生龙虾意外曝光,Karpathy:这就是Claude ClawClaude Code正在光速进化为Claude Claw。
来自主题: AI资讯
6179 点击 2026-04-01 18:51
 搜索
搜索
Claude Code正在光速进化为Claude Claw。
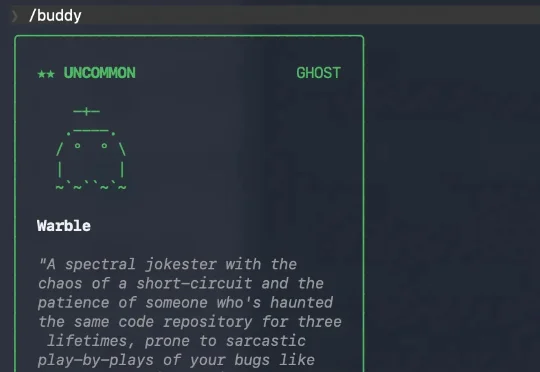
就在今天,Claude Code 悄悄上线了一个宠物模式。就在今天,Claude Code 悄悄上线了一个宠物模式。有物种、有属性、有性格,挺花哨的。从泄露代码的时间戳来看,今天这个Buddy宠物系统就是计划好的,4月1日首次亮相,如期而至。

一次低级失误,让全球开发者拿到了 AI 编程工具的「行业标准答案」。一个更重要的问题是,AI 公司,应该如何利用这次「泄露」,抄作业?很多人第一反应是:Claude Code 不就是一个套了模型 API 的命令行工具吗?源代码泄露了又怎样,没有模型权重,这些代码不过是个「壳子」。

「哈密顿分解」难题,终于破解!88岁「算法祖师爷」高德纳再更论文,Claude 4.6+GPT-5.4联合破解了奇偶数情形。甚至,GPT-5.4直出一篇14页论文,引爆全网。

爆了爆了!Claude Code源码库彻底火了,60k人深夜疯狂Fork。Anthropic紧急出手,GitHub原作者凌晨4点用Python、Rust重洗代码。 上线不过24小时,Claude Code「源码」仓库直接杀疯!
因为 Claude Code 就是目前最顶级的 Agent 系统,没有之一。我敢说,昨晚有大量厂商的技术团队通宵在扒这份源码,疯狂学习里面的架构设计,拿来改进自家产品。下面说说我是怎么部署的,流程其实很简单。

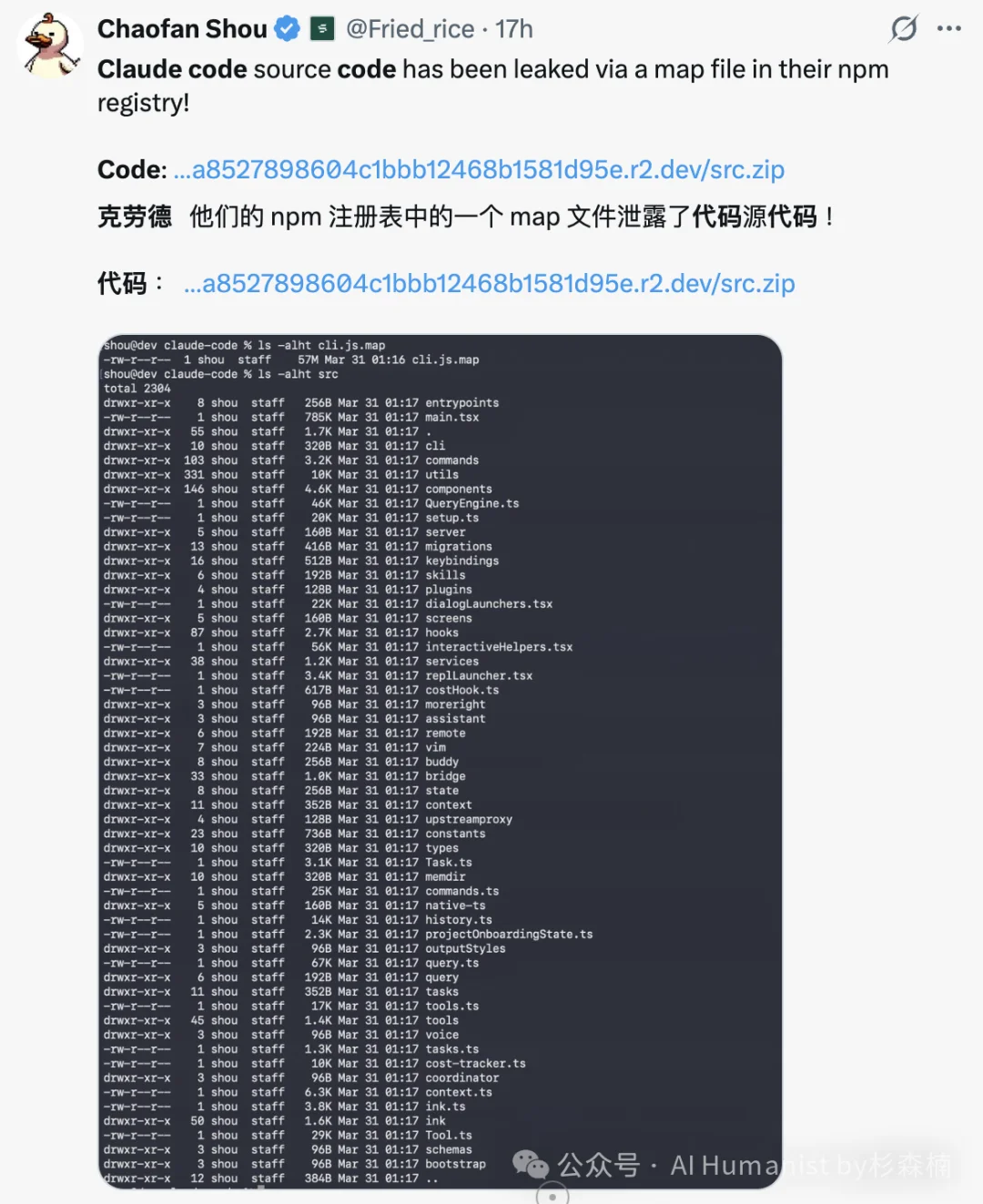
昨晚,Anthropic 意外在一个 npm 包更新中泄漏了其核心产品 Claude Code 高达 51.2 万行的底层源代码,参阅《全网疯传fork!刚刚,Claude Code源代码泄露被开源了》。此事过去还不到一天,刚刚,Anthropic 的主要竞争对手 OpenAI 官方宣布已完成最新一轮融资,本轮获取承诺资本达 1220 亿美元,投后估值飙升至 8520 亿美元!
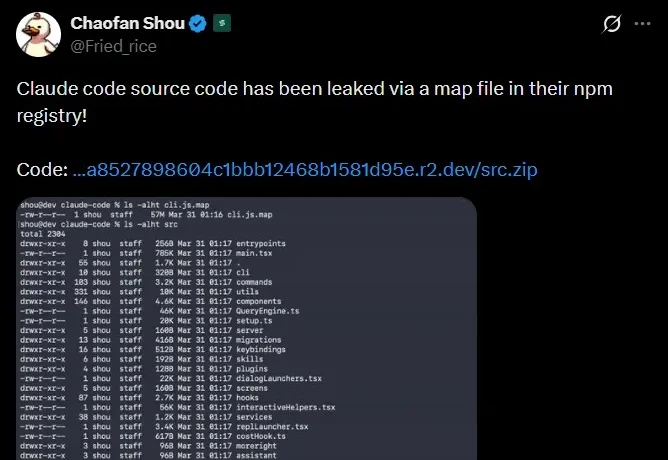
2026 年 3 月 31 日,安全研究员 Chaofan Shou 发现 Anthropic 的 Claude Code 全部源码通过 npm 包里的一个 source map 文件暴露在了公网上

我自己用 Coding Plan 也有一段时间了,最开始只是为了省点 API 钱,后来各家陆续推出固定月费套餐,我发现选起来比想象中复杂。Codex、Claude Code、Cline、OpenClaw 这些工具让开发者越来越习惯用自然语言驱动代码生成和任务执行,但高频调用带来的 API 成本也成了一笔固定开销。

Claude Code 源码泄露为业界一下子打开了 Agent 进化的大门。