
ICLR 2026 | 数据缺少标注,RL还能稳定诱导模型推理吗?Co-rewarding提供自监督RL学习方案!
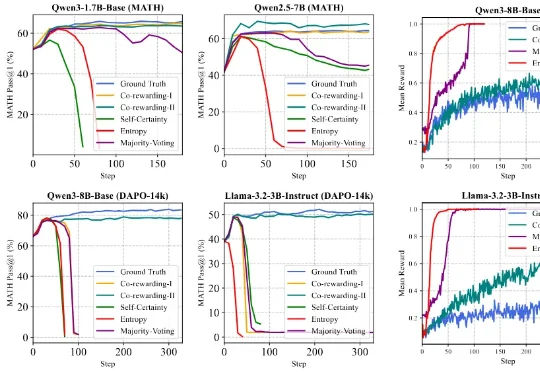
ICLR 2026 | 数据缺少标注,RL还能稳定诱导模型推理吗?Co-rewarding提供自监督RL学习方案!针对这一挑战,来自香港浸会大学和上海交通大学的可信机器学习和推理组提出了一个全新的自监督 RL 框架 ——Co-rewarding。该框架通过在数据端或模型端引入互补视角的自监督信号,稳定奖励获取,提升 RL 过程中模型奖励投机的难度,从而有效避免 RL 训练崩溃,实现稳定训练和模型推理能力的诱导。
来自主题: AI技术研报
8751 点击 2026-02-24 15:16