Codex撞脸Claude Code,新功能只领先11天
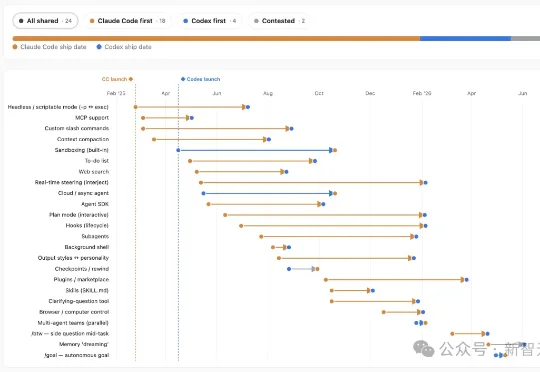
Codex撞脸Claude Code,新功能只领先11天Codex和Claude Code长得越来越像了!最近,开发者Elie Bakouch感到Claude Code和Codex的功能越来越像,他好奇到底哪家在领跑,于是就把两家都有的功能做成了一张时间线。
来自主题: AI资讯
8673 点击 2026-06-07 10:54
 搜索
搜索
Codex和Claude Code长得越来越像了!最近,开发者Elie Bakouch感到Claude Code和Codex的功能越来越像,他好奇到底哪家在领跑,于是就把两家都有的功能做成了一张时间线。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,
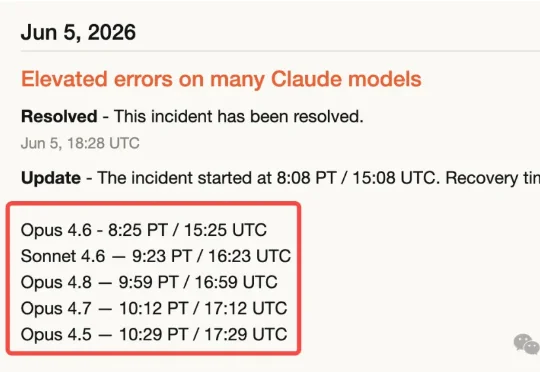
就在昨天,Anthropic 的官方状态页突然挂起一排刺眼的红灯——Claude API、Claude Code、Claude.ai、Claude Cowork……几乎所有核心服务,突然大面积宕机。从 Opus 4.6 到 Opus 4.8,五大模型无一幸免。
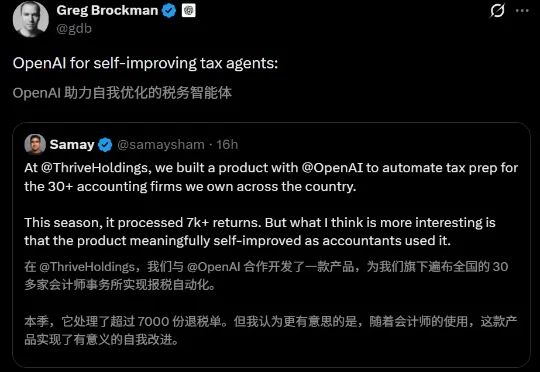
没人重训模型,没人重写代码,OpenAI的AI系统六周内自己把准确率从25%拉到86%。Codex自己定位bug、写修复、跑测试,AI自我进化已在生产环境跑起来了。
终于看到一个跳出 Codex、Claude Code 这些 Agent 范畴的新 AI 产品。而且在海外已经火起来了。这个产品叫 Aippy。目前 MAU 将近两百万,全球下载超过三百万,刚完成首轮融资,投后估值 2.5 亿美元。也是垂类赛道的新独角兽了。

在ChatGPT拥有10亿用户后,AI问答这一定位,显然已经难以撑起其下一阶段的增长。另一方面,Codex每周活跃用户已超500万。很多人囿于名字,以为这是Coding产品。。。。限制了其在编程圈外的增长。

其实大概半年前,我就有这个需求了。那阵子我也注意到,阿里、字节这些平台都各自出了提示词优化器。但它们都得专门跑到对应的网站上去用,对我来说不够顺手。所以这回干脆借着深度复盘了 Anthropic 的 Prompt 讲座,用 Codex vibe coding 了一个全局提示词优化器。
科研神器Papers with Code,满血复活!

Codex 又又又大更新,前一天负责人还在说,是不是要改名 ChadGPT,网友在下面评论说,不如直接将 ChatGPT 重新命名为 Codex。

今天看到了一个我觉得还挺有价值的东西。