
超越英伟达Describe Anything!中科院 & 字节联合提出「GAR」,为DeepSeek-OCR添砖加瓦
超越英伟达Describe Anything!中科院 & 字节联合提出「GAR」,为DeepSeek-OCR添砖加瓦近期,DeepSeek-OCR提出了“Vision as Context Compression”的新思路,然而它主要研究的是通过模型的OCR能力,用图片压缩文档。
来自主题: AI技术研报
9555 点击 2025-10-28 14:28
 搜索
搜索
近期,DeepSeek-OCR提出了“Vision as Context Compression”的新思路,然而它主要研究的是通过模型的OCR能力,用图片压缩文档。

dots.ocr 支持多语言文档的解析,能够在单一模型中统一完成版面检测、文本识别、表格解析、公式提取等任务,并保持良好的阅读顺序。他们之所以在一个模型中完成这些任务,是因为他们相信这些任务之间可以相互促进,为彼此提供更多的 context,从而达到更高的性能上限。目前,该项目的 star 量已经超过了 5000。
最近在开源社区闲逛,发现字节悄悄放出了一个叫 MineContext 的项目。和字节Viking团队的小伙伴聊天时,我了解到一个挺有意思的故事:MineContext 团队其实在今年四五月份就有了初步想法,甚至更早之前就在思考:如何围绕个人的完整记忆来做应用。

近日刚好得了空闲,在研读 Anthropic 官方技术博客和一些相关论文,主题是「Agent 与 Context 工程」。2025 年 6 月以来,原名为「Prompt Engineering」的提示词工程,在 AI Agent 概念日趋火热的应用潮中,
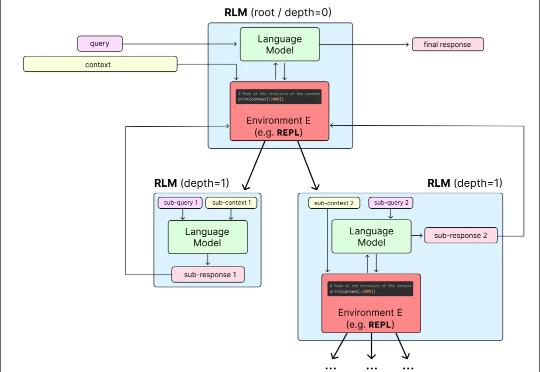
目前,所有主流 LLM 都有一个固定的上下文窗口(如 200k, 1M tokens)。一旦输入超过这个限制,模型就无法处理。 即使在窗口内,当上下文变得非常长时,模型的性能也会急剧下降,这种现象被称为「上下文腐烂」(Context Rot):模型会「忘记」开头的信息,或者整体推理能力下降。
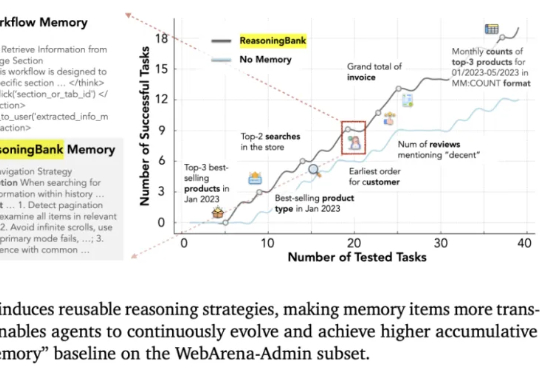
这几天,关于「微调已死」的言论吸引了学术圈的广泛关注。一篇来自斯坦福大学、SambaNova、UC 伯克利的论文提出了一种名为 Agentic Context Engineering(智能体 / 主动式上下文工程)的技术,让语言模型无需微调也能实现自我提升!
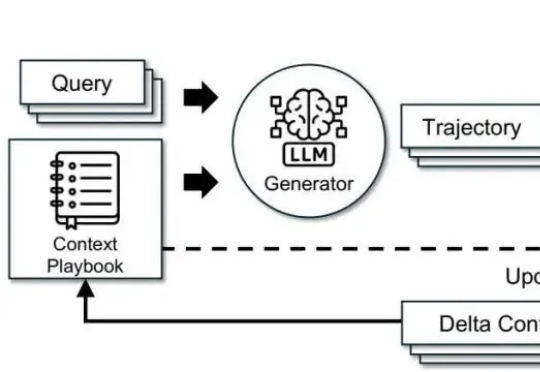
调模型不如“管上下文”。这篇文章基于 ACE(Agentic Context Engineering),把系统提示、运行记忆和证据做成可演化的 playbook,用“生成—反思—策展”三角色加差分更新,规避简化偏置与上下文塌缩。在 AppWorld 与金融基准上,ACE 相较强基线平均提升约 +10.6% 与 +8.6%,适配时延降至约 1/6(-86.9%),且在无标注监督场景依然有效。
Supermemory 已获得由 Susa Ventures、Browder Capital 和 SF1.vc 领投的 260 万美元种子轮融资。此轮融资还包括 Cloudflare 的 Knecht、谷歌人工智能负责人 Jeff Dean、DeepMind 产品经理 Logan Kilpatrick、Sentry 创始人 David Cramer 以及来自 OpenAI、

最近 flowith 推出了全新画布,交互形态全新升级,现在 AI 生成的任意内容,都可以被很方便的右键点击节点,存入任意知识库,后续工作都可以调用。说实话,flowith 是一款上手门槛比较高的产品,它不像一般对话式的 ChatBot 那样简单,
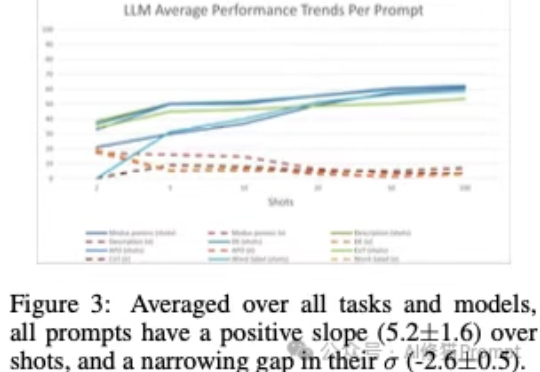
上下文学习”(In-Context Learning,ICL),是大模型不需要微调(fine-tuning),仅通过分析在提示词中给出的几个范例,就能解决当前任务的能力。您可能已经对这个场景再熟悉不过了:您在提示词里扔进去几个例子,然后,哇!大模型似乎瞬间就学会了一项新技能,表现得像个天才。