
刚刚!ASP-DAC 2025最佳论文出炉,无问芯穹上交大论文获奖
刚刚!ASP-DAC 2025最佳论文出炉,无问芯穹上交大论文获奖由无问芯穹与上海交通大学联合研究团队提出的视频生成软硬一体加速器,首次实现通过差分近似和自适应数据流解决 VDiT 生成速度缓慢瓶颈,推理速度相比 A100 提升高达 16.44 倍。
来自主题: AI资讯
10698 点击 2025-01-24 13:44
 搜索
搜索
由无问芯穹与上海交通大学联合研究团队提出的视频生成软硬一体加速器,首次实现通过差分近似和自适应数据流解决 VDiT 生成速度缓慢瓶颈,推理速度相比 A100 提升高达 16.44 倍。

AI训练即将进入语料比拼阶段 Reddit 在过去的 2024 年算得上是容光焕发。这家创立了近 20 年的社交平台,去年 3 月在纽交所完成上市,并在上市后的第三季度实现首次盈利,到目前股票已涨到上市首日开盘价的 350% 左右。
Reddit 作为一个充满活力的全球社区平台,里面有非常丰富的兴趣小组和只有想不到没有找不到的话题,类似国内的百度贴吧、豆瓣,我们不仅可以从中发现灵感、验证想法,还可以找到对应的客户,非常适合验证创业想法。
近些年来,以 Stable Diffusion 为代表的扩散模型为文生图(T2I)任务树立了新的标准,PixArt,LUMINA,Hunyuan-DiT 以及 Sana 等工作进一步提高了图像生成的质量和效率。然而,目前的这些文生图(T2I)扩散模型受限于模型尺寸和运行时间,仍然很难直接部署到移动设备上。
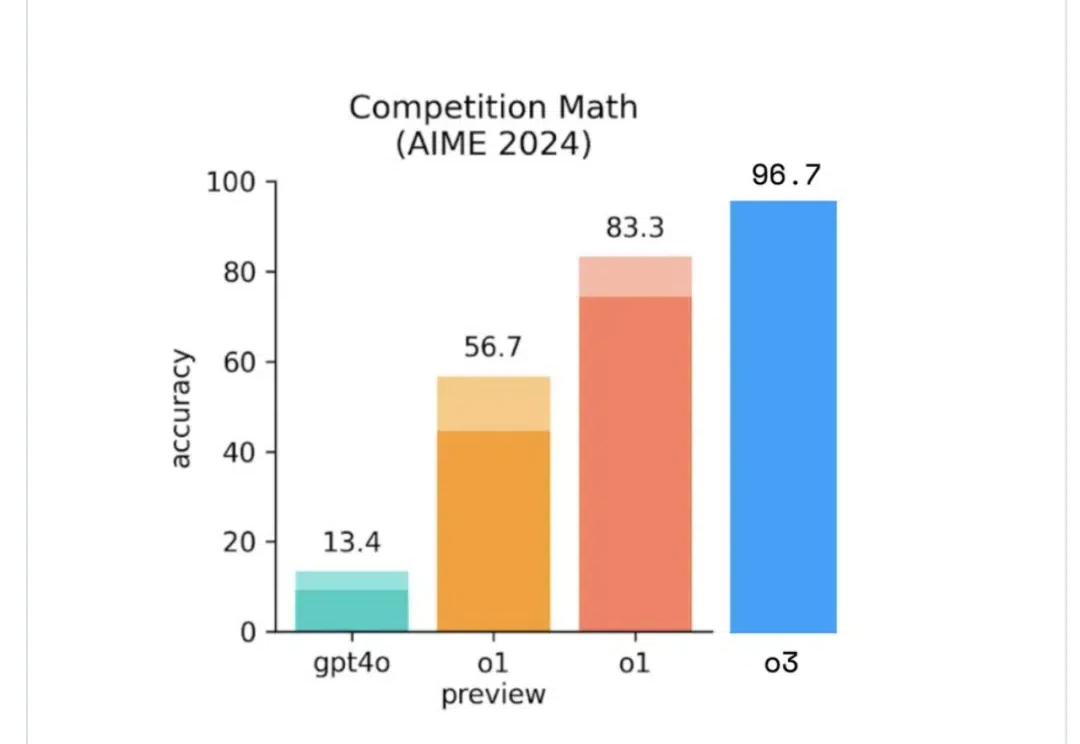
从韦氏智商测试来看,如果 o3 的 IQ 真这么高,则称得上非常优秀。 OpenAI o3 的智商(IQ)竟然已经这么高了吗 今天,Reddit 上一则热帖宣称「OpenAI o3 的 IQ 估计为 157」,并放出了一张数据图。
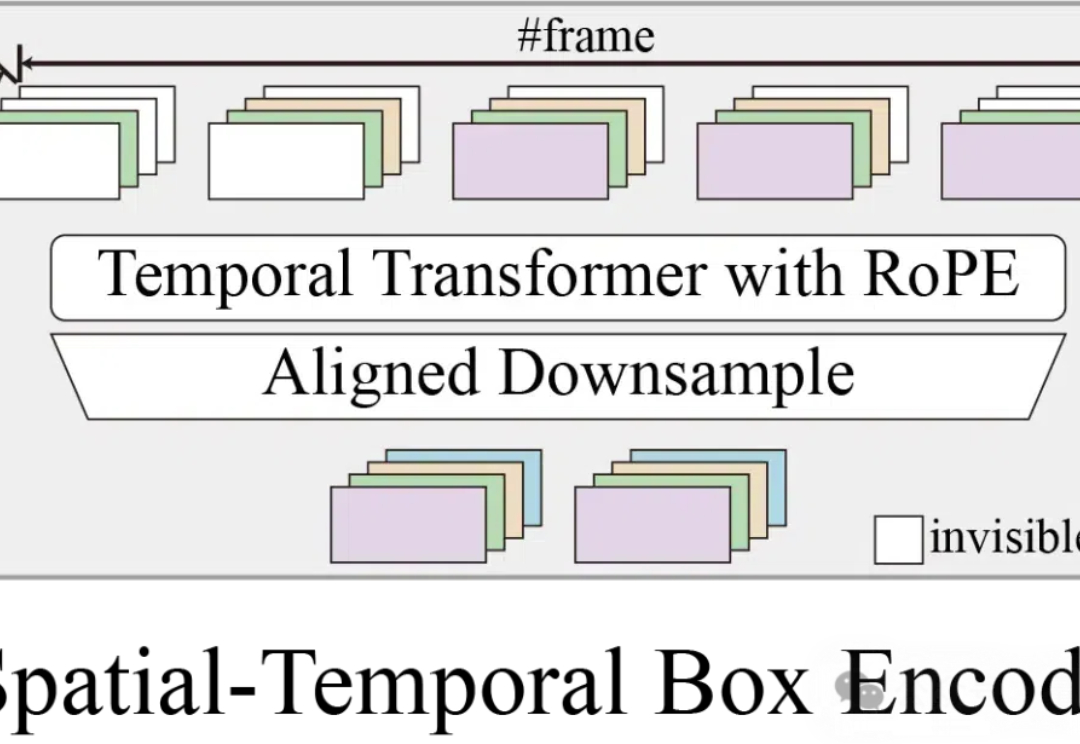
可控视频生成,对于自动驾驶技术而言,同样非常重要。

昨日(12 月 9 日),知名社区 Reddit 发布公告,正式推出 AI 驱动的搜索工具 Reddit Answers,Reddit希望通过该功能优化平台的信息检索功能,为用户提供更高效便捷的信息获取途径。(手动狗头:作为一个内容站,没有AI搜索怎么能行呢。
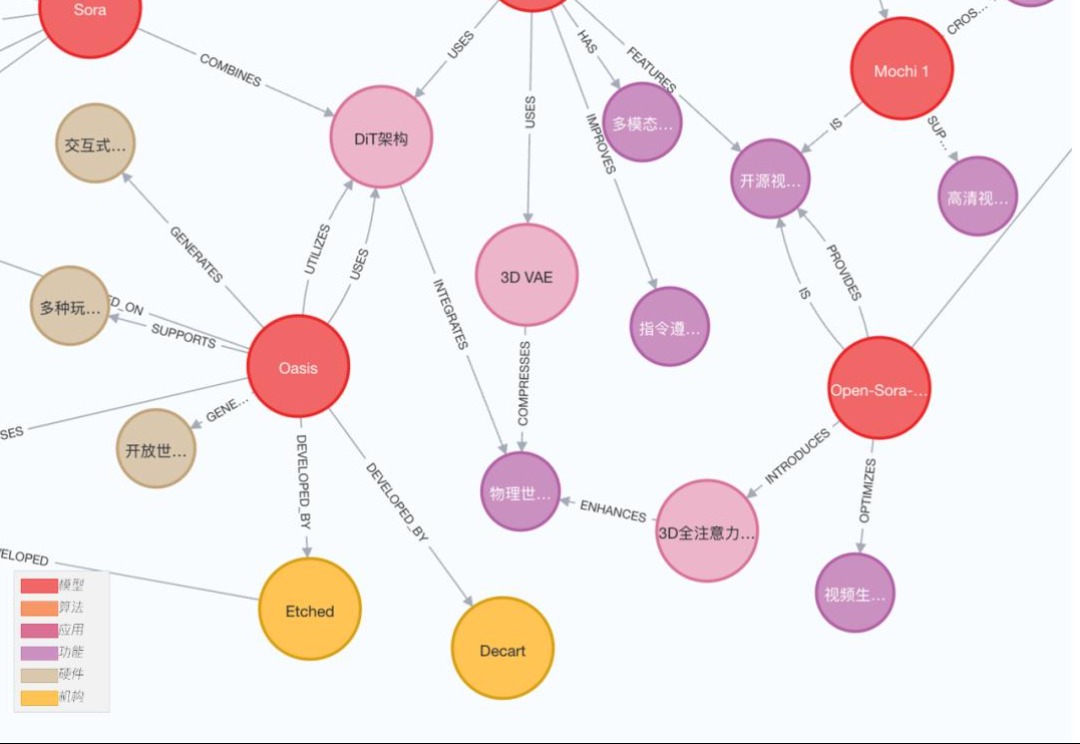
本期 AGI 路线图中关键节点:Sora、DiT、Runway Gen-3、可灵 AI、Oasis、世界模拟器
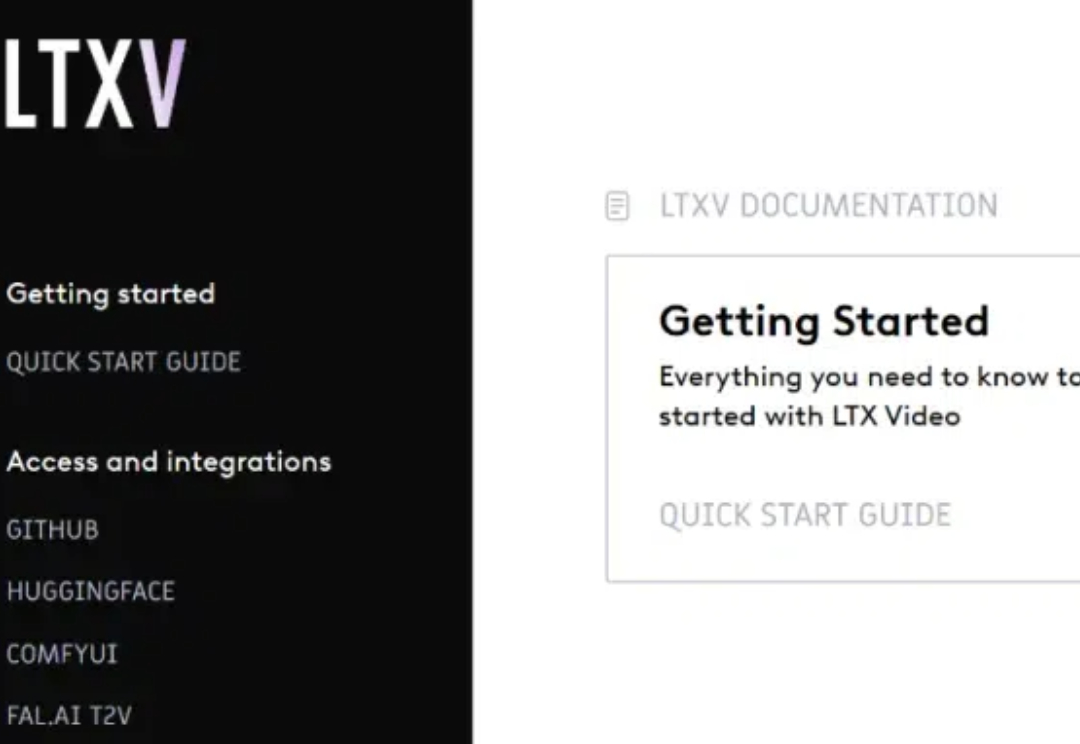
这个周末,押注开源人工智能视频的初创公司 Lightricks,有了重大动作。 该公司推出了最快的视频生成模型 LTX-Video,它是首个可以实时生成高质量视频的 DiT 视频生成模型。
JENOVA:AI Reddit Search & AI Youtube Search 功能上线,以及为啥这个需求爆了