

DeepMind研究成本大起底,一篇ICML论文烧掉1290万美元
DeepMind研究成本大起底,一篇ICML论文烧掉1290万美元DeepMind最近被ICML 2024接收的一篇论文,完完全全暴露了他们背靠谷歌的「豪横」。一篇文章预估了这项研究所需的算力和成本,大概是Llama 3预训练的15%,耗费资金可达12.9M美元。
来自主题: AI技术研报
8082 点击 2024-08-03 15:03
DeepMind最近被ICML 2024接收的一篇论文,完完全全暴露了他们背靠谷歌的「豪横」。一篇文章预估了这项研究所需的算力和成本,大概是Llama 3预训练的15%,耗费资金可达12.9M美元。

谷歌DeepMind推出LLM自动评估模型FLAMe系列,FLAMe-RM-24B模型在RewardBench上表现卓越,以87.8%准确率领先GPT-4o。

谷歌DeepMind的小模型核弹来了,Gemma 2 2B直接击败了参数大几个数量级的GPT-3.5和Mixtral 8x7B!而同时发布的Gemma Scope,如显微镜一般打破LLM黑箱,让我们看清Gemma 2是如何决策的。

OpenAI员工离职创业,AI帝国估值达600亿美元。
刚刚,大模型再次攻下一城!
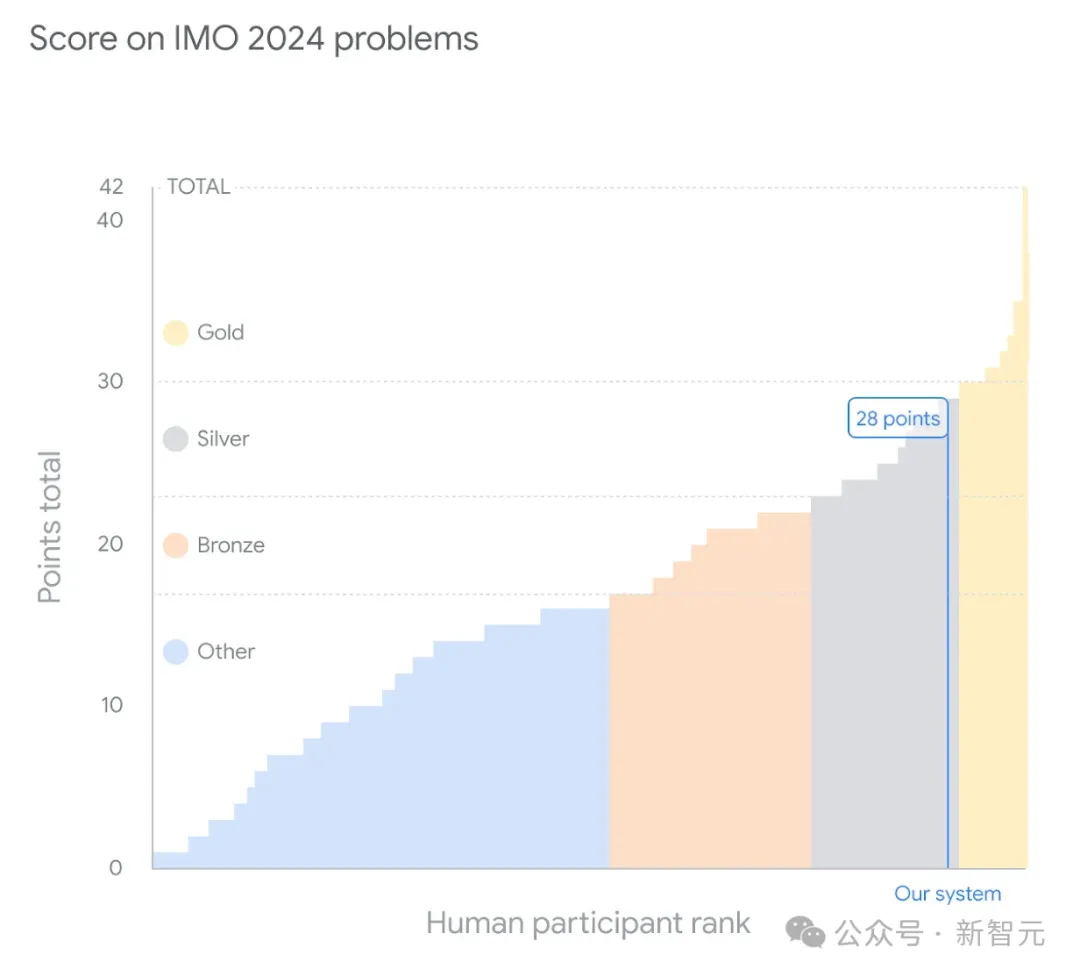
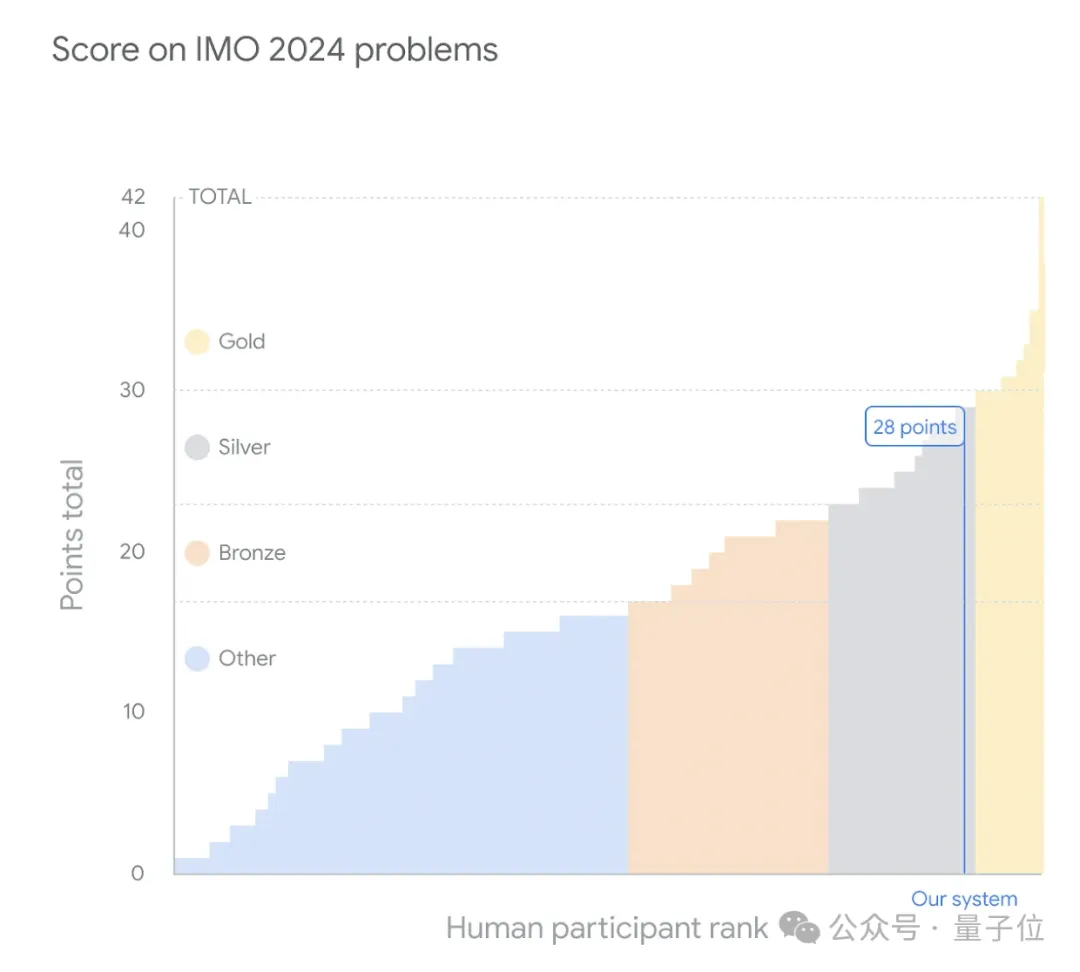
就在刚刚,谷歌DeepMind最新的数学模型捧得了IMO奥数银牌!它不仅以满分成绩做出了6道题中的4道,距离金牌只有1分之差,而且在第4题上只用了19秒,解题质量和速度惊呆了评分的人类评委。

继去年初的第一代VALL-E模型之后,微软最近又上新了VALL-E 2模型,标志着第一个在合成语音稳健性、相似度、自然程度等方面达到人类水平的文本到语音模型。

这可能是当今最全面、最新的深度学习概述之一。
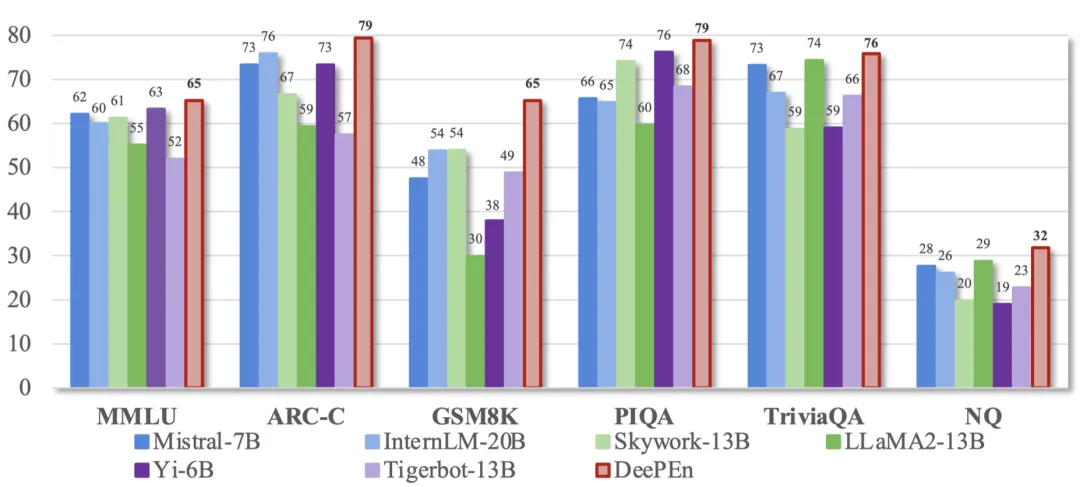
随着大语言模型展现出惊人的语言智能,各大 AI 公司纷纷推出自己的大模型。这些大模型通常在不同领域和任务上各有所长,如何将它们集成起来以挖掘其互补潜力,成为了 AI 研究的前沿课题。

MoE已然成为AI界的主流架构,不论是开源Grok,还是闭源GPT-4,皆是其拥趸。然而,这些模型的专家,最大数量仅有32个。最近,谷歌DeepMind提出了全新的策略PEER,可将MoE扩展到百万个专家,还不会增加计算成本。