

深夜突袭,DeepSeek-Prover-V2加冕数学王者!671B数学推理逆天狂飙
深夜突袭,DeepSeek-Prover-V2加冕数学王者!671B数学推理逆天狂飙就在刚刚,DeepSeek-Prover-V2技术报告也来了!34页论文揭秘了模型的训练核心——递归+强化学习,让数学推理大提升。有人盛赞:DeepSeek已找到通往AGI的正确路径!
来自主题: AI资讯
9198 点击 2025-05-01 10:49
就在刚刚,DeepSeek-Prover-V2技术报告也来了!34页论文揭秘了模型的训练核心——递归+强化学习,让数学推理大提升。有人盛赞:DeepSeek已找到通往AGI的正确路径!

Meta首届LlamaCon开发者大会开幕,扎克伯格在期间接受采访,回应大模型相关的一切。包括Llama4在大模型竞技场表现不佳的问题:

就在刚刚,DeepSeek 在全球最大 AI 开源社区 Hugging Face 发布了一个名为 DeepSeek-Prover-V2-671B 的新模型。

春节以来,DeepSeek 的爆火点燃了 AI 产业化的加速引擎,但 AI 的真正落地远不止于技术突破,更是对基础设施和生态系统的巨大考验。

自从DeepSeek带火了蒸馏模型以后,更多人开始关注AI大模型在边缘端的部署。而在过去,TinyML一直也在MCU领域很火热。现在,边缘AI走得更快了,市场也正在走向爆发。

满血DeepSeek一体机,价格竟然被打到10万元级别了!
春天,1000 个通用 Agent 正在爆发。 所有的 Chatbot,都在改造成 Agent。技术在迁移,新的技术栈催生了新的产品形态——通用 Agent、Manus、Deep Research,一如过去两年大家的信仰,应用一定是中国开发者的机会。

“2月16日那一周,感觉全中国的政府企业都在上Deepseek,甚至很多单位原来一张卡都没有,突然就有了DeepSeek满血版。”金山办公Office产研事业部副总经理刘丹说道,“那段时间我认识的大部分领导也都在问,‘你们到底什么时候接,怎么样的节奏’,整个行业都特别火热。”
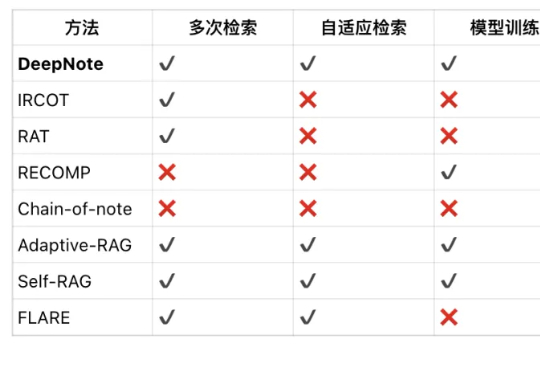
在当前大语言模型(LLMs)广泛应用于问答、对话等任务的背景下,如何更有效地结合外部知识、提升模型对复杂问题的理解与解答能力,成为 RAG(Retrieval-Augmented Generation)方向的核心挑战。

阿里Qwen3凌晨开源,正式登顶全球开源大模型王座!它的性能全面超越DeepSeek-R1和OpenAI o1,采用MoE架构,总参数235B,横扫各大基准。这次开源的Qwen3家族,8款混合推理模型全部开源,免费商用。