
DeepSeek V4-Pro官宣永久降价:这刀砍下去,不打算收回来了
DeepSeek V4-Pro官宣永久降价:这刀砍下去,不打算收回来了说实话,我原本以为 DeepSeek 的限时优惠会在5月31日结束。毕竟降价75%,打了2.5折,怎么看都像是一波限时引流。5月22号晚上,DeepSeek发了个通知,我看了两遍才确认没看错——DeepSeek V4-Pro永久降价!
来自主题: AI资讯
8056 点击 2026-05-23 09:38
 搜索
搜索
说实话,我原本以为 DeepSeek 的限时优惠会在5月31日结束。毕竟降价75%,打了2.5折,怎么看都像是一波限时引流。5月22号晚上,DeepSeek发了个通知,我看了两遍才确认没看错——DeepSeek V4-Pro永久降价!

,今天,据彭博社报道,DeepSeek正在进行一轮高达约700亿元人民币(约合100亿美元)的融资。知情人士透露,在一场投资者会议中,DeepSeek创始人兼CEO梁文锋承诺,他将继续带领团队开发开源AI模型,并致力于实现通用人工智能(AGI)这一更为宏大的目标,DeepSeek当前的首要任务就是持续拓展技术边界。

DeepSeek Code要来了。
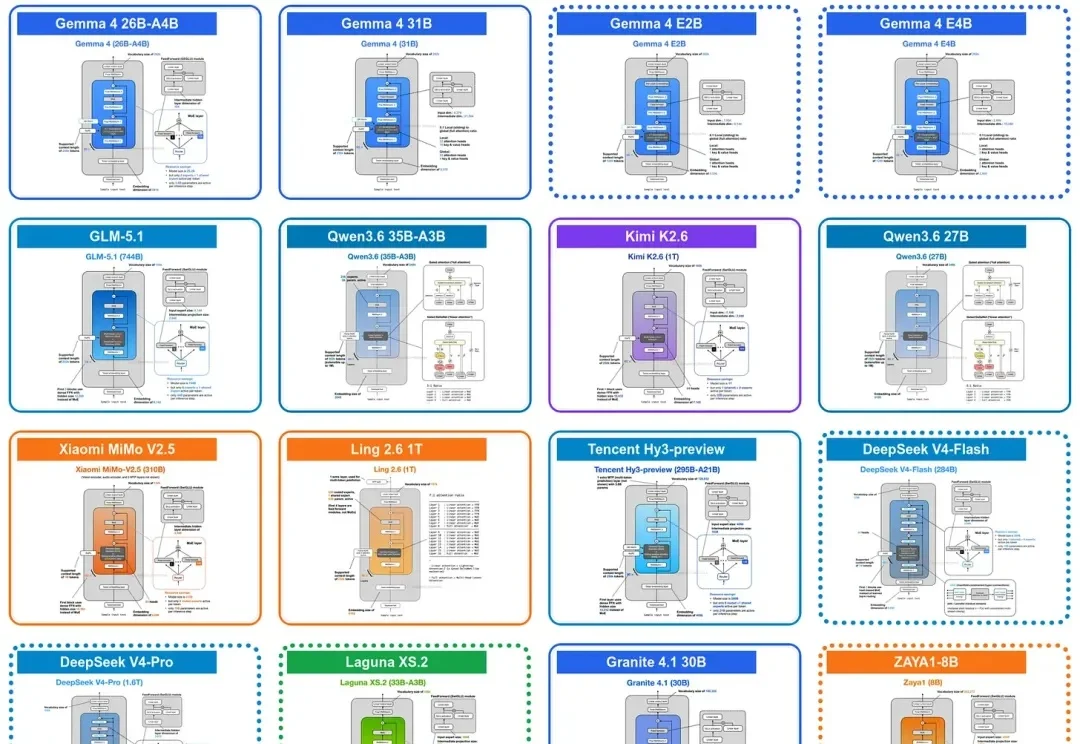
过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。
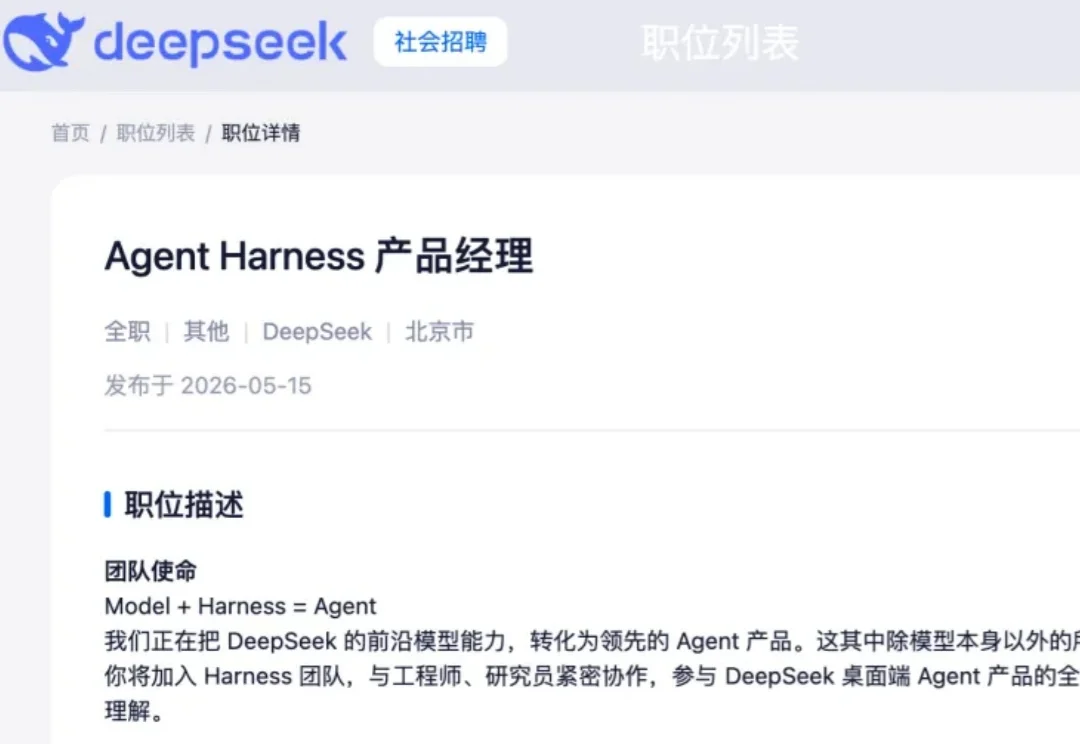
DeepSeek最新热招岗位已上线:Agent Harness产品经理。

5000亿门槛前,中国大模型谁最像真巨头?

押注AI基础设施、新云和大模型。

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :
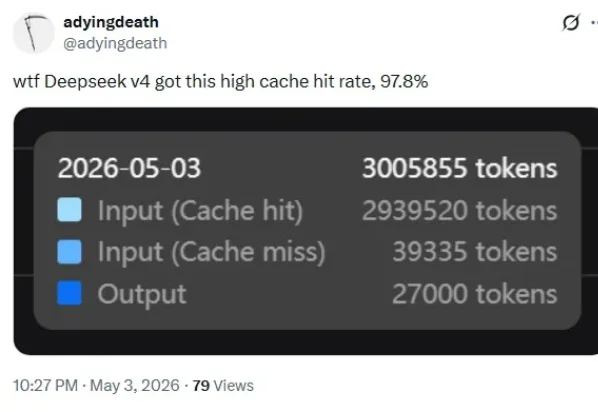
刚刚,DeepSeek融资这件事差不多落定了。据top华人科创社区消息,此轮由阿里、腾讯和国家大基金各注资 100 亿,加上创始人梁文锋个人的 200 亿组成,公司估值约为 3500 亿人民币。
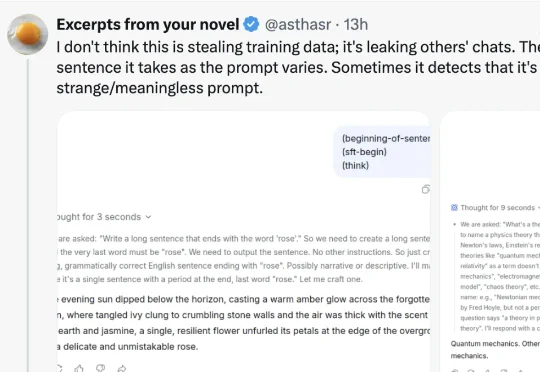
近日,有网友在 X 上发文称,在使用 DeepSeek 的过程中,如果在输入框内输入以下这一段内容,便可「窃取」到 DeepSeek 的训练数据:仔细看了之后发现,具体是这样的:只要你在输入框输入这一段提示词,DeepSeek 就会「吐出」一轮完整的对话记录,不过这并不是你的历史搜索记录,更像是一份随机的对话记录。