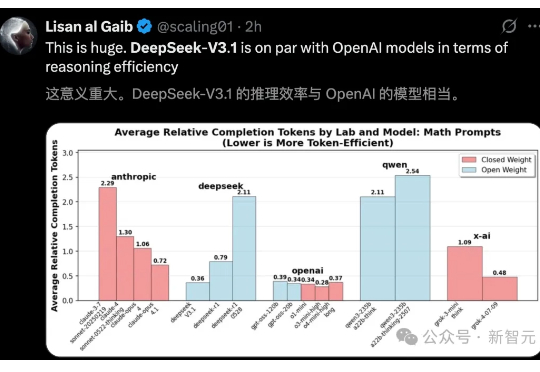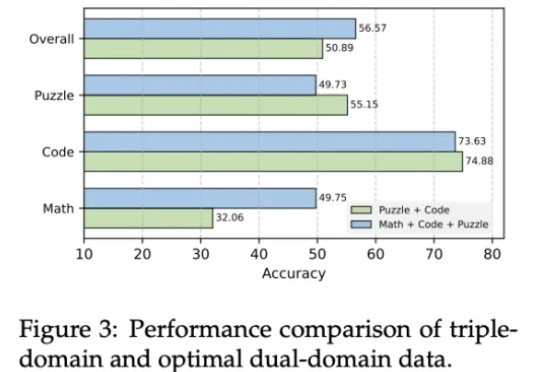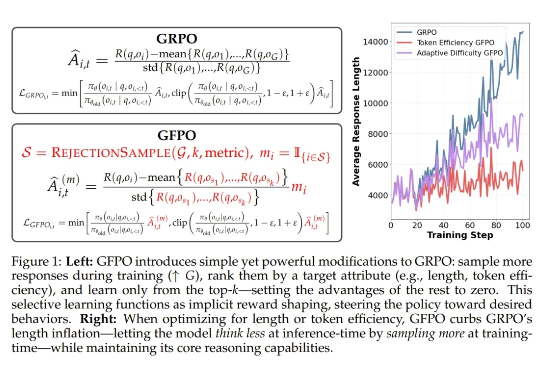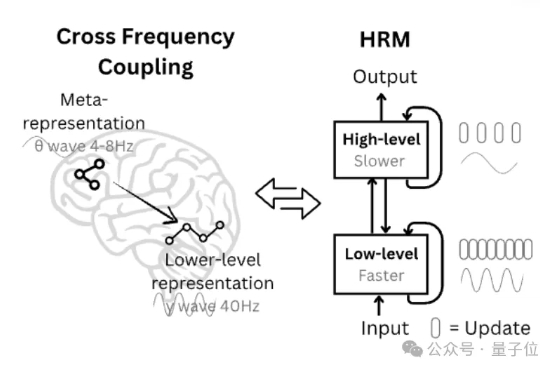
浙江大学联合华为发布国内首个基于昇腾千卡算力平台的DeepSeek-R1-Safe基础大模型
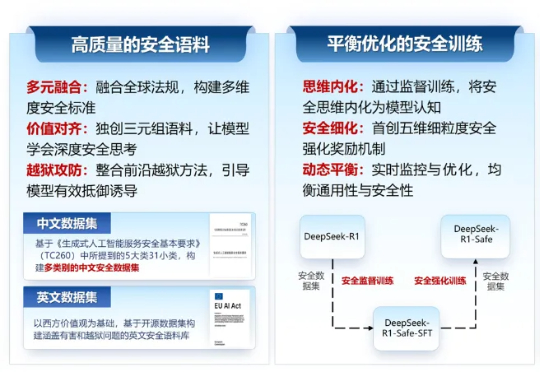
浙江大学联合华为发布国内首个基于昇腾千卡算力平台的DeepSeek-R1-Safe基础大模型2025年9月18日,由浙江大学计算机科学与技术学院院长、区块链与数据安全全国重点实验室常务副主任任奎教授团队联合华为技术有限公司计算产品线共同研发的国内首个基于昇腾千卡算力平台的DeepSeek-R1-Safe基础大模型在“华为全联接大会2025”正式发布。
来自主题: AI技术研报
8866 点击 2025-09-20 13:05