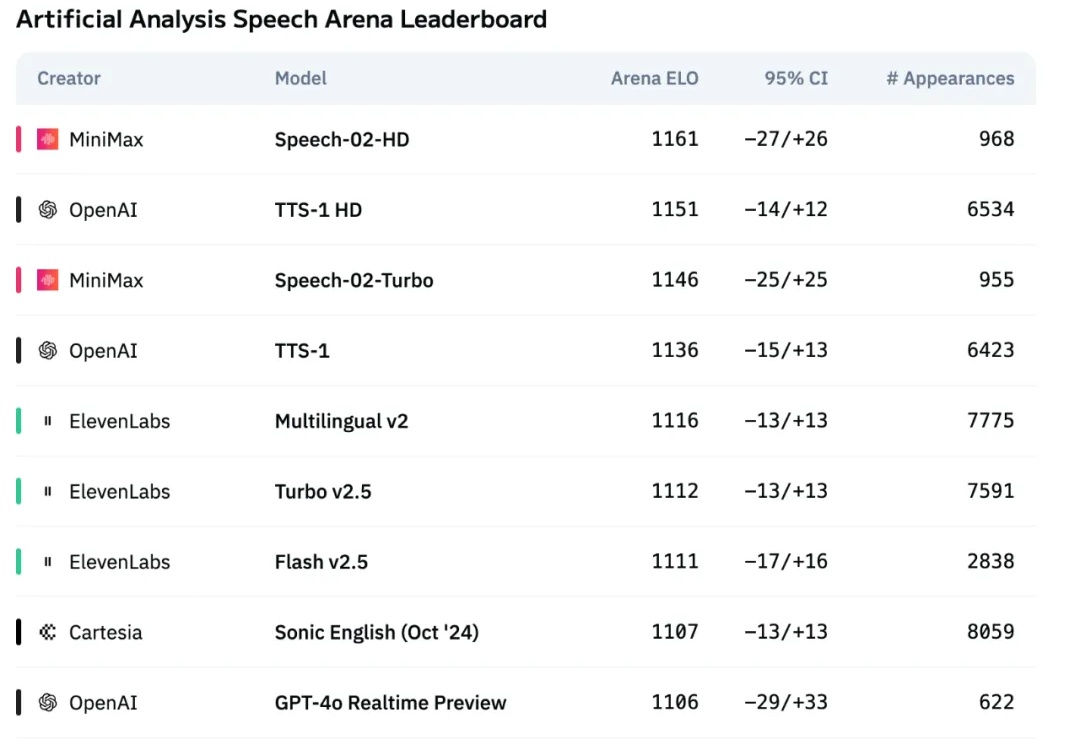
超越OpenAI、ElevenLabs,MiniMax新一代语音模型屠榜!人格化语音时代来了
超越OpenAI、ElevenLabs,MiniMax新一代语音模型屠榜!人格化语音时代来了国产大模型进步的速度早已大大超出了人们的预期。年初 DeepSeek-R1 爆火,以超低的成本实现了部分超越 OpenAI o1 的表现,一定程度上让人不再过度「迷信」国外大模型。
来自主题: AI技术研报
11170 点击 2025-05-16 09:59
 搜索
搜索
国产大模型进步的速度早已大大超出了人们的预期。年初 DeepSeek-R1 爆火,以超低的成本实现了部分超越 OpenAI o1 的表现,一定程度上让人不再过度「迷信」国外大模型。

近日,来自SGLang、英伟达等机构的联合团队发了一篇万字技术报告:短短4个月,他们就让DeepSeek-R1在H100上的性能提升了26倍,吞吐量已非常接近DeepSeek官博数据!

超越DeepSeek-R1的英伟达开源新王Llama-Nemotron,是怎么训练出来的?刚刚放出的论文,把一切细节毫无保留地全部揭秘了!

本文深入梳理了围绕DeepSeek-R1展开的多项复现研究,系统解析了监督微调(SFT)、强化学习(RL)以及奖励机制、数据构建等关键技术细节。

阿里Qwen3凌晨开源,正式登顶全球开源大模型王座!它的性能全面超越DeepSeek-R1和OpenAI o1,采用MoE架构,总参数235B,横扫各大基准。这次开源的Qwen3家族,8款混合推理模型全部开源,免费商用。
最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。
AIMO2冠军「答卷」公布了!英伟达团队NemoSkills拔得头筹,开源了OpenMath-Nemotron系列AI模型,1.5B小模型击败14B-DeepSeek「推理大模型」!
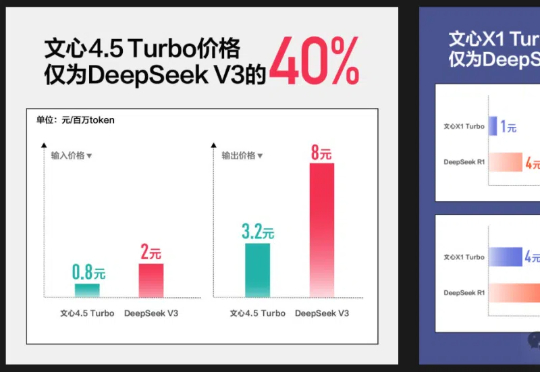
百度文心大模型X1 Turbo正式发布了。这个基于4.5 Turbo的深度思考模型,效果领先DeepSeek-R1、V3,且价格仅为R1的25%!而文心4.5 Turbo在低价的同时,多模态能力更是让人出乎意料。
OpenAI 的 o1 系列模型、Deepseek-R1 带起了推理模型的研究热潮,但这些推理模型大多关注数学、代码等专业领域。

什么开源算法自称为DeepSeek-R1(-Zero) 框架的第一个复现?