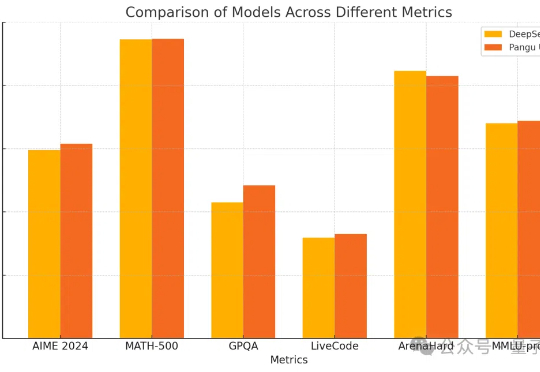
英伟达含量为零!华为密集模型性能比肩DeepSeek-R1,纯昇腾集群训练
英伟达含量为零!华为密集模型性能比肩DeepSeek-R1,纯昇腾集群训练密集模型的推理能力也能和DeepSeek-R1掰手腕了?
来自主题: AI资讯
7676 点击 2025-04-15 15:05
 搜索
搜索
密集模型的推理能力也能和DeepSeek-R1掰手腕了?

研究发现,推理模型(如DeepSeek-R1、o1)遇到「缺失前提」(MiP)的问题时,这些模型往往表现失常:回答长度激增、计算资源浪费。本文基于马里兰大学和利哈伊大学的最新研究,深入剖析推理模型在MiP问题上的「过度思考」现象,揭示其背后的行为模式,带你一窥当前AI推理能力的真实边界。

千亿参数内最强推理大模型,刚刚易主了。32B——DeepSeek-R1的1/20参数量;免费商用;且全面开源——模型权重、训练数据集和完整训练代码,都开源了。这就是刚刚亮相的Skywork-OR1 (Open Reasoner 1)系列模型——

字节跳动豆包团队今天发布了自家新推理模型 Seed-Thinking-v1.5 的技术报告。从报告中可以看到,这是一个拥有 200B 总参数的 MoE 模型,每次工作时会激活其中 20B 参数。其表现非常惊艳,在各个领域的基准上都超过了拥有 671B 总参数的 DeepSeek-R1。有人猜测,这就是字节豆包目前正在使用的深度思考模型。
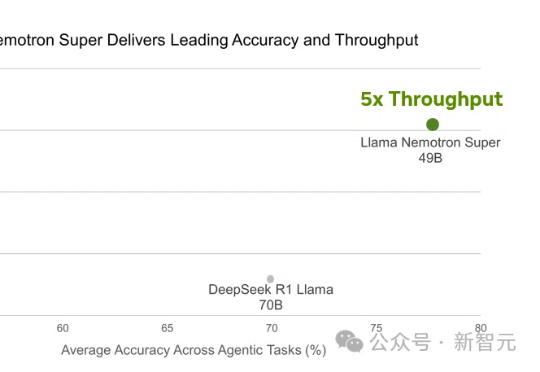
Llama 4刚出世就被碾压!英伟达强势开源Llama Nemotron-253B推理模型,在数学编码、科学问答中准确率登顶,甚至以一半参数媲美DeepSeek R1,吞吐量暴涨4倍。关键秘诀,就在于团队采用的测试时Scaling。
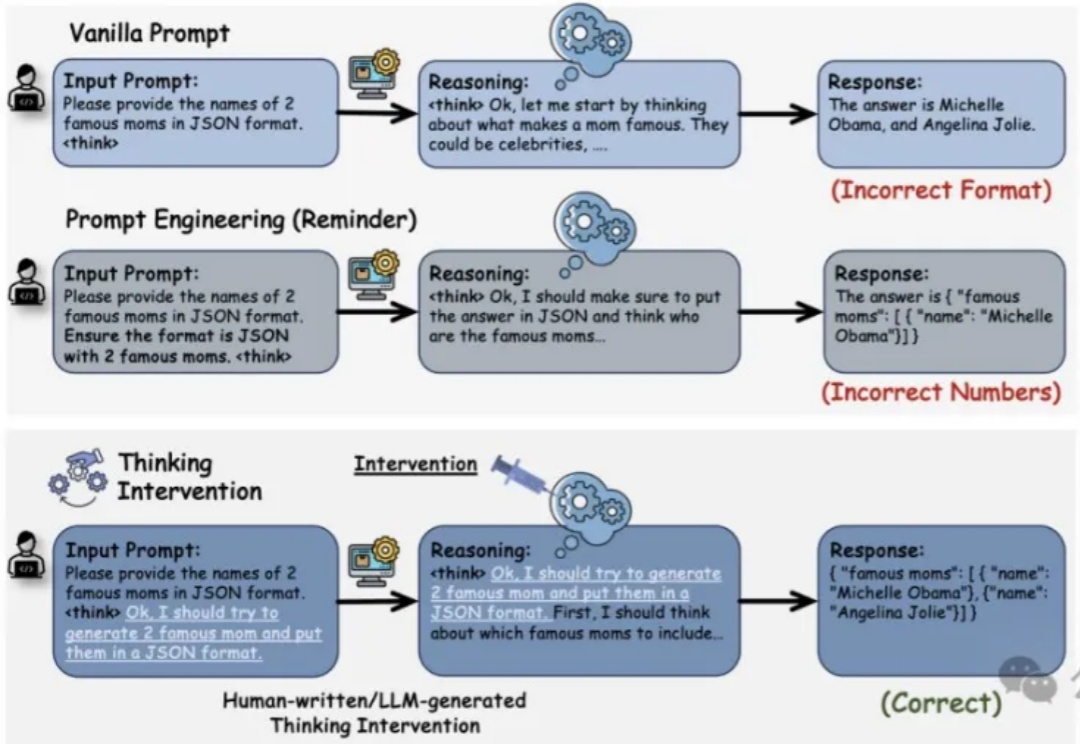
推理增强型大语言模型LRM(如OpenAI的o1、DeepSeek R1和Google的Flash Thinking)通过在生成最终答案前显式生成中间推理步骤,在复杂问题解决方面展现了卓越性能。然而,对这类模型的控制仍主要依赖于传统的输入级操作,如提示工程(Prompt Engineering)等方法,而你可能已经发现这些方法存在局限性。
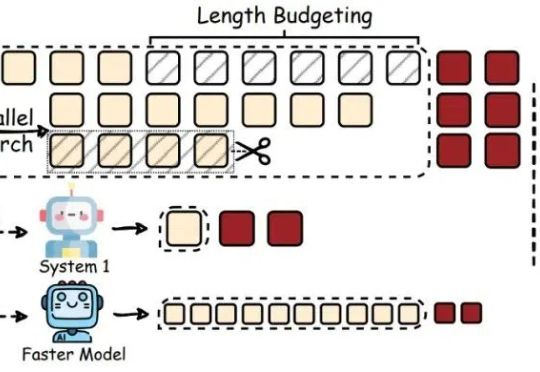
最近,像 OpenAI o1/o3、DeepSeek-R1 这样的大型推理模型(Large Reasoning Models,LRMs)通过加长「思考链」(Chain-of-Thought,CoT)在推理任务上表现惊艳。

国产全自研高性能RISC-V服务器芯片“灵羽”,刚刚在深圳亮相。

众所周知,DeepSeek R1 这种模型在推理任务上很能打,尤其是在数学和编程这些逻辑性强的领域。那么我们能直接把这种强大的推理能力搬到 DeepSearch 这种需要动态规划、多轮交互的深度搜索场景里吗?
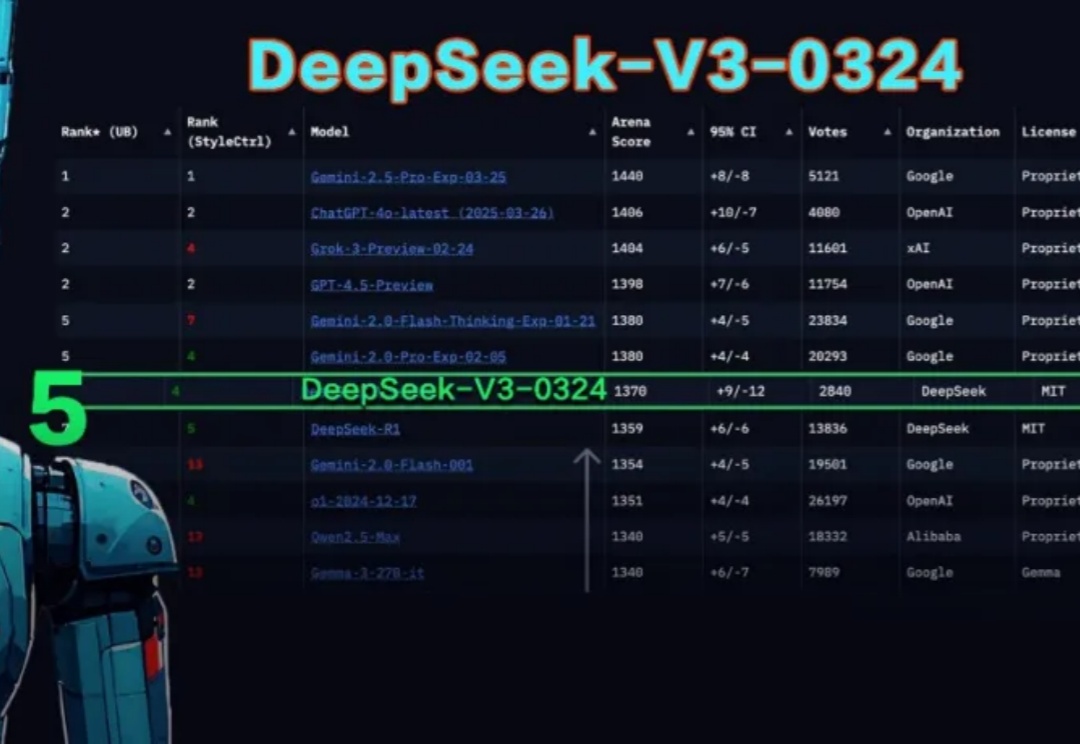
DeepSeek又卷起来了!上周刚出的DeepSeek-V3-0324在大模型竞技场排名中,打败了自己的DeepSeek-R1,成为开源AI至尊。