硬核拆解大模型,从 DeepSeek-V3 到 Kimi K2 ,一文看懂 LLM 主流架构
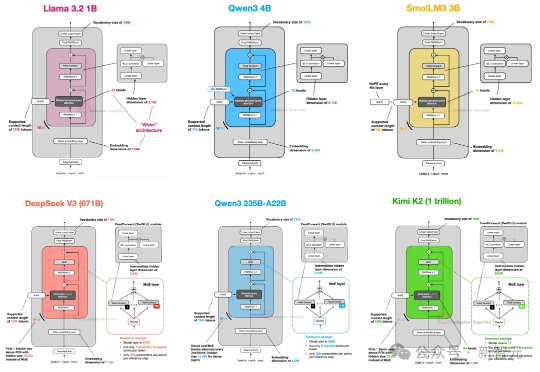
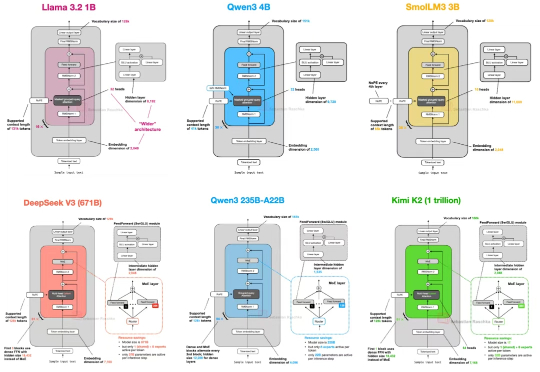
硬核拆解大模型,从 DeepSeek-V3 到 Kimi K2 ,一文看懂 LLM 主流架构自首次提出 GPT 架构以来,转眼已经过去了七年。 如果从 2019 年的 GPT-2 出发,回顾至 2024–2025 年的 DeepSeek-V3 和 LLaMA 4,不难发现一个有趣的现象:尽管模型能力不断提升,但其整体架构在这七年中保持了高度一致。
来自主题: AI技术研报
9257 点击 2025-08-08 11:52