
哥大退学网红AI作弊器,亲测翻车!搅黄会议划水90s,创始人承认仅是雏形
哥大退学网红AI作弊器,亲测翻车!搅黄会议划水90s,创始人承认仅是雏形外媒记者发现:哥大退学哥的「Cheat Everything」作弊神器,实测翻车了!不仅反应慢,回答几乎没法用,还会造成工作会议中诡异的麦克风问题。其实,这不是AI作弊器第一次被曝出问题,但各大机构的投资狂热,却丝毫没有要停下来的意思。
来自主题: AI资讯
9653 点击 2025-04-26 10:51
 搜索
搜索
外媒记者发现:哥大退学哥的「Cheat Everything」作弊神器,实测翻车了!不仅反应慢,回答几乎没法用,还会造成工作会议中诡异的麦克风问题。其实,这不是AI作弊器第一次被曝出问题,但各大机构的投资狂热,却丝毫没有要停下来的意思。
就在刚刚,在Create 2025百度AI开发者大会上,李彦宏又一口气官宣了两款新模型:分别是主打深度思考和多模态的X1 Turbo/4.5 Turbo。据介绍,它们是百度在3月发布的旗舰模型X1、4.5的升级版,推理和多模态能力双双更跃Level。
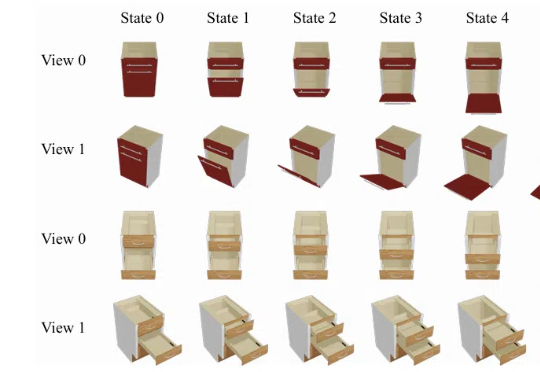
基于当前观察,预测铰链物体的的运动,尤其是 part-level 级别的运动,是实现世界模型的关键一步。
故老相传:中国人擅长做应用,但在这次AI的应用上结果却大相径庭,美国人在AI应用上看起来跑得更快。Glean、Harvey等这类应用动辄ARR(Annual Recurring Revenue)过1亿美金,ARR过2500万美金的初创企业更是有相当大一批。

从Google Glasses到HoloLens,再到近几年雷鸟创新、Even Realities、影目、星纪魅族、Rokid等陆续发布量产产品,AR眼镜在不断刷新其轻薄程度。

这个号称世界上第一个AI天使投资人的No Cap,由Jeff wilson、Alexander Nevedovsky 和 Slava Solonitsyn打造,并在最近拿到了YC的投资。No Cap号称是通过一个“No Cap Mafia”社区训练出来的。在这个社区里,No Cap会接受很多公司创始人的指导,目前已经有超过60位创始人(他们都是YC的校友)参与其中。
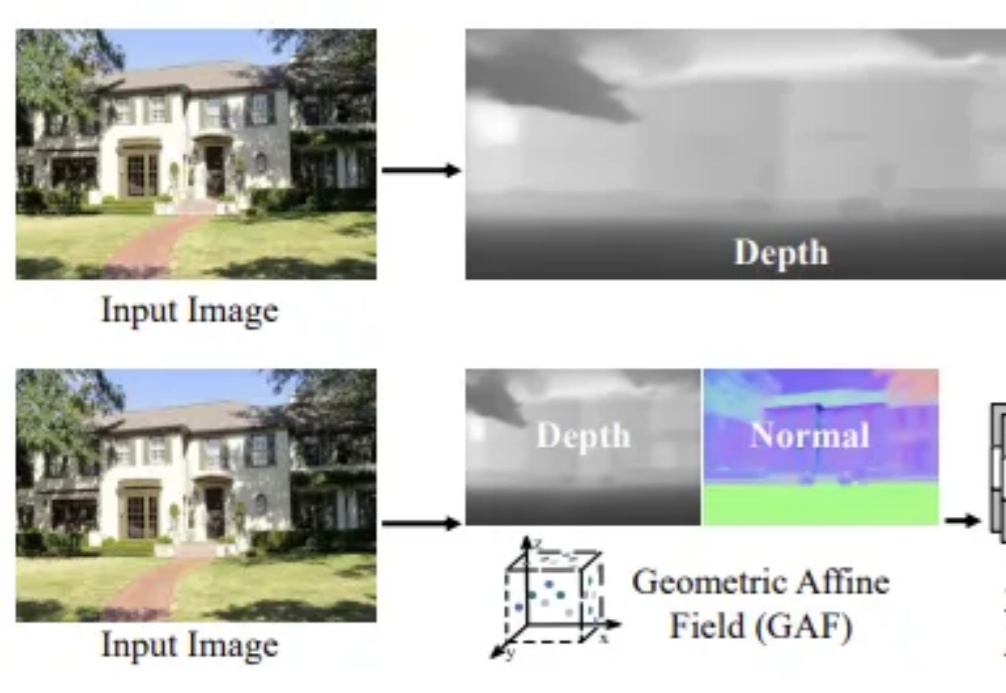
单视角三维场景重建一直是计算机视觉领域中的核心挑战之一,尤其在捕捉高保真室外场景细节时,如何确保结构一致性和几何精度显得尤为困难。

「压缩即智能」。这并不是一个新想法,著名 AI 研究科学家、OpenAI 与 SSI 联合创始人 Ilya Sutskever 就曾表达过类似的观点。

2024年对我用AI来做独立开发,最大的意义就是回本了。谈到“回本”,主要是指我们作为Apple Developer,每年需要支付99美金的会员费。第一年的99美金,相当于我的学费。当时我发布了一个名为“裁切大师”的应用,带来了约40多美金的收入
AI 初创公司 ElevenLabs,刚刚筹集了 1.8 亿美元巨额融资 ,主要以其音频生成能力而闻名。该公司通过推出首个独立语音转文本模型 Scribe,迈向了另一个技术方向。