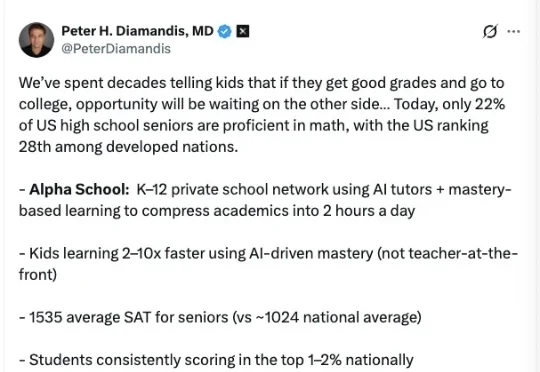
老师讲 12 小时,不如 AI 教 2 小时?这所高中直接干掉了所有老师,Claude、ChatGPT 也成学生日常
老师讲 12 小时,不如 AI 教 2 小时?这所高中直接干掉了所有老师,Claude、ChatGPT 也成学生日常在近日的一场播客中,曾做出 5 款产品的 AI 创业公司 Every 创始人兼 CEO Dan Shipper 采访了一位特别的年轻人 Alex Mathew。这个来自美国得克萨斯州奥斯汀 Alpha 高中的 17 岁高三学生,同时也是一名 AI 硬件创业者。
来自主题: AI资讯
9539 点击 2026-03-02 10:16