
告别错误累计与噪声干扰,EviNote-RAG 开启 RAG 新范式
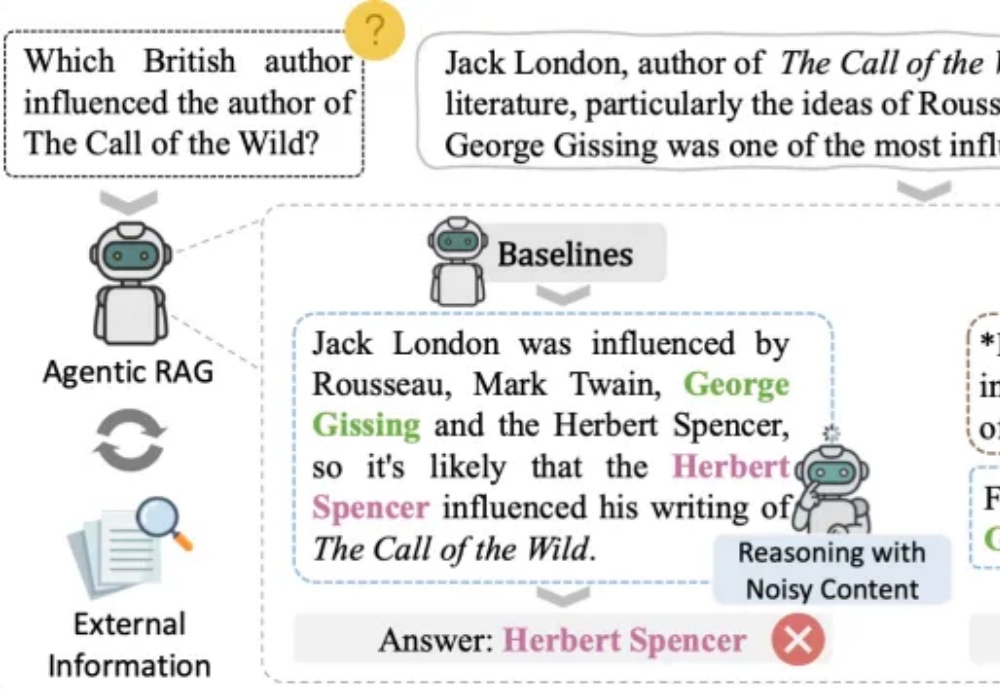
告别错误累计与噪声干扰,EviNote-RAG 开启 RAG 新范式在检索增强生成(RAG)飞速发展的当下,研究者们面临的最大困境并非「生成」,而是「稳定」。
来自主题: AI技术研报
8750 点击 2025-09-12 11:05
在检索增强生成(RAG)飞速发展的当下,研究者们面临的最大困境并非「生成」,而是「稳定」。
总参数达到1万亿,阿里迄今为止最大的模型来了! 没错,就是前几日大家期待已久的Qwen3-Max-Preview (Instruct)。
阿里迄今为止,参数最大的模型诞生了!昨夜,Qwen3-Max-Preview(Instruct)官宣上线,超1万亿参数性能爆表。在全球主流权威基准测试中,Qwen3-Max-Preview狂揽非推理模型「C」位,直接碾压Claude-Opus 4(Non-Thinking)、Kimi-K2、DeepSeek-V3.1。
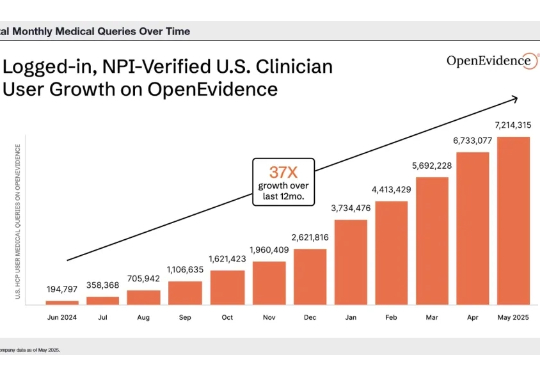
AI医疗领域,冲出一匹年度黑马! 据外媒报道,美国AI医疗初创公司OpenEvidence正在寻求新一轮融资,估值约60亿美元(约合人民币427亿元)。

OpenEvidence 运营的一款类似 ChatGPT 的产品,专为医生提供健康信息查询服务。据知情人士透露,这家成立仅三年的初创公司正在考虑多份投资要约,估值高达 60 亿美元,几乎是其一个月前私募融资估值的两倍。
微软紧跟OpenAI的节奏,在同一天也亲自下场发布了微软自研的两个大模型:语音模型MAI-Voice-1和通用模型MAI-1-preview。对于这位老大哥,亲自下场做的第一个AI大模型,效果究竟怎么样?

Nano Banana我之前预告过说要写,今天终于写完了。Nano Banana就是现在谷歌的gemini-2.5-flash-image-preview(看你这么厉害,后续就晋升缩写为NB吧),确实是很不错,我尝试了多种玩法,现在分享给大家,今天废话少说,但是案例管饱,来来一起往下看!

昨晚,神秘且强大的图像生成与编辑模型 nano banana 终于正式显露真身。没有意外,它果然来自谷歌,并且也获得了一个正式但无趣的名字:gemini-2.5-flash-image-preview。

一个月前在德国被50多家投资人拒绝的AI创业公司,搬到硅谷后却能在一周内完成470万美元的融资,而且投资人几乎全部说"yes"。这不是什么励志鸡汤故事,而是Leaping AI创始人Kevin Wu的真实经历。
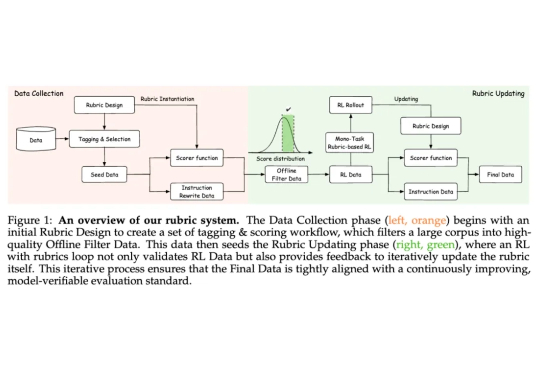
蚂蚁技术研究院联合浙江大学开源全新强化学习范式 Rubicon,通过构建业界最大规模的 10,000+ 条「评分标尺」,成功将强化学习的应用范围拓展至更广阔的主观任务领域。用 5000 样本即超越 671B 模型,让 AI 告别「机械味」。