

蚂蚁·安诊儿医疗大模型:正式开源并登顶权威医疗榜单
蚂蚁·安诊儿医疗大模型:正式开源并登顶权威医疗榜单医疗健康领域的AI应用迎来「最强大脑」!蚂蚁·安诊儿医疗大模型正式开源,专业能力登顶全球权威榜单。从复杂病例解读到日常健康科普,它能为大众提供专业医生般的解答,也能助力医生更高效精准做临床判断。AI 技术如何让健康守护更简单?快来看看这个最大规模开源医疗模型背后的故事!
来自主题: AI资讯
9315 点击 2026-01-06 10:15
医疗健康领域的AI应用迎来「最强大脑」!蚂蚁·安诊儿医疗大模型正式开源,专业能力登顶全球权威榜单。从复杂病例解读到日常健康科普,它能为大众提供专业医生般的解答,也能助力医生更高效精准做临床判断。AI 技术如何让健康守护更简单?快来看看这个最大规模开源医疗模型背后的故事!
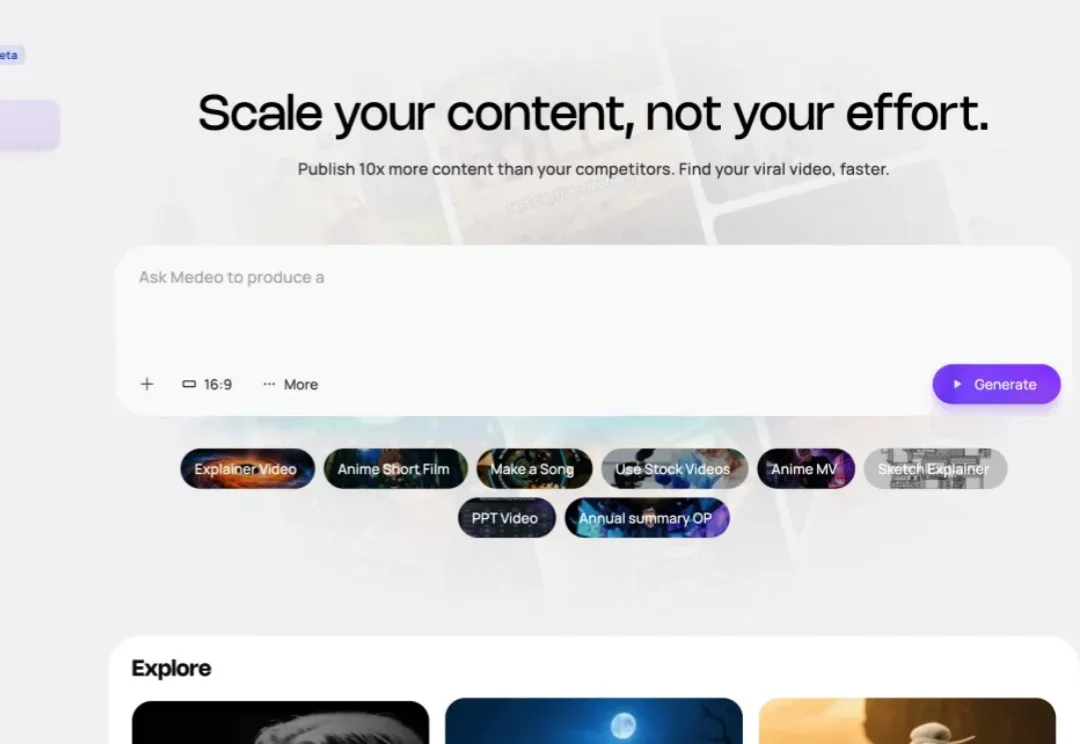
将视频制作门槛降至新低。
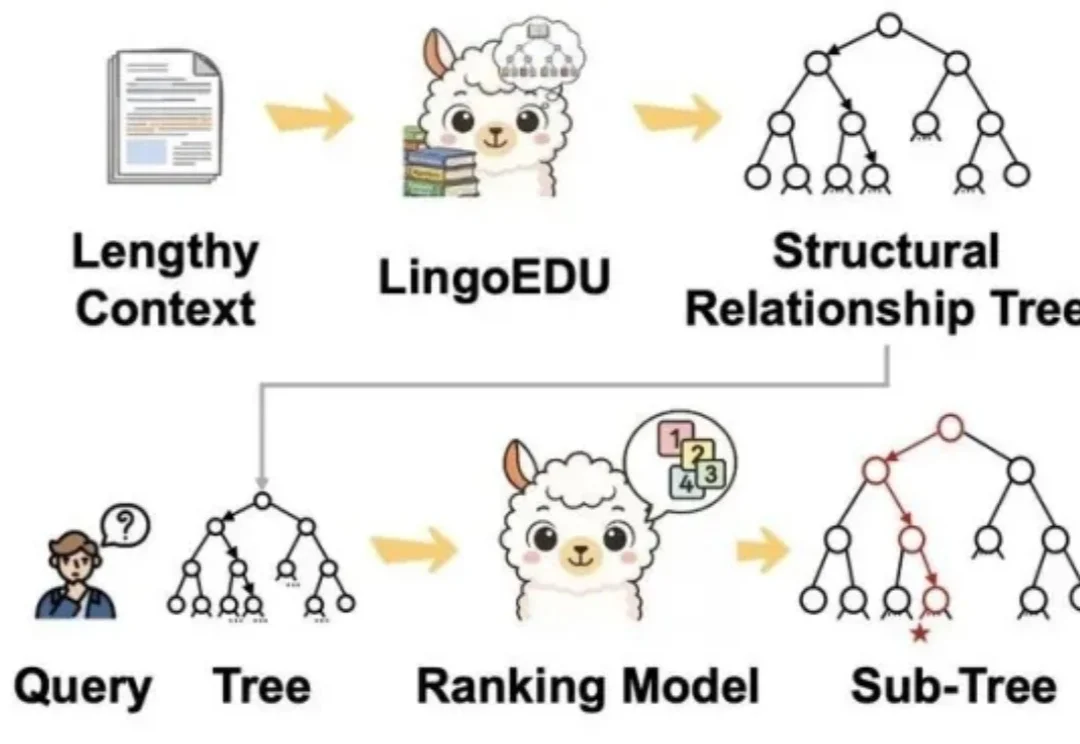
零成本降低大模型幻觉新方法,让DeepSeek准确率提升51%!

LLM的下一个推理单位,何必是Token?刚刚,字节Seed团队发布最新研究——DLCM(Dynamic Large Concept Models)将大模型的推理单位从token(词) 动态且自适应地推到了concept(概念)层级。

前几天,在最通人性的AI美少女虚拟主播Neuro的一场生日直播中,发生了一场席卷所有人的,对AI的热议。在直播中,Neuro和她的开发者Vedal在Vrchat闲逛时,突然询问她的开发者Vedal:

最近在研究 RAG 系统优化的时候,发现了一个有意思的格式叫 TOON。全称是 Token-Oriented Object Notation,翻译过来就是面向 Token 的对象表示法。

近日,腾讯微信 AI 团队提出了 WeDLM(WeChat Diffusion Language Model),这是首个在工业级推理引擎(vLLM)优化条件下,推理速度超越同等 AR 模型的扩散语言模型。
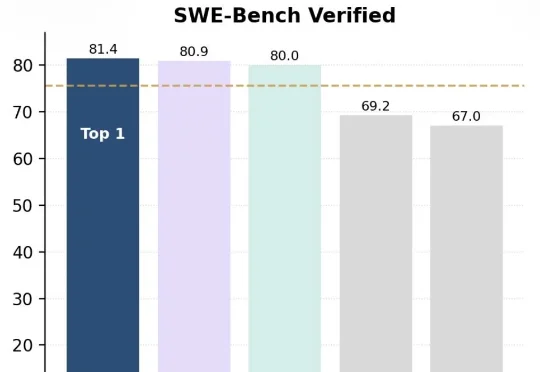
又一个中国新模型被推到聚光灯下,刷屏国内外科技圈。IQuest-Coder-V1模型系列,看起来真的很牛。在最新版SWE-Bench Verified榜单中,40B参数版本的IQuest-Coder取得了81.4%的成绩,这个成绩甚至超过了Claude Opus-4.5和GPT-5.2(这俩模型没有官方资料,但外界普遍猜测参数规模在千亿-万亿级)。

GetSeed要做的,是帮你从记录里长出新的认知。昨天晚上看了跨年演讲的同学,可能对我做的GetSeed AI录音卡有印象。没印象也没关系,今天这篇内容,我就和你详细讲讲这款AI产品的台前幕后,包括做产品过程中,我所有的思考和遇到的问题。

Medeo是最近最令我好奇的AI视频Agent。