Agent狂欢下的冷思考:为什么说Data&AI数据基础设施,才是AI时代Infra新范式
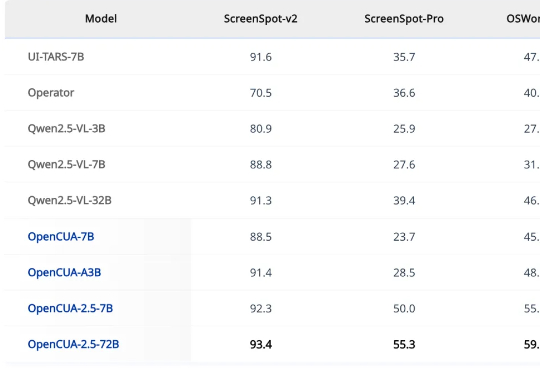
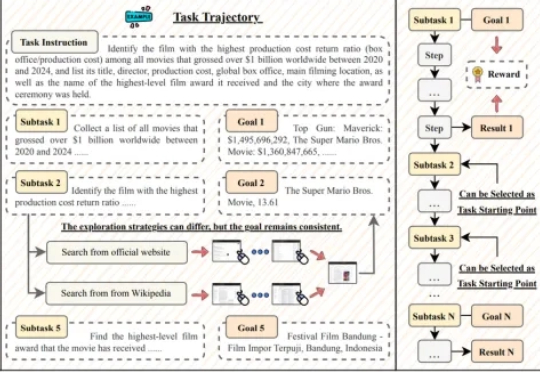
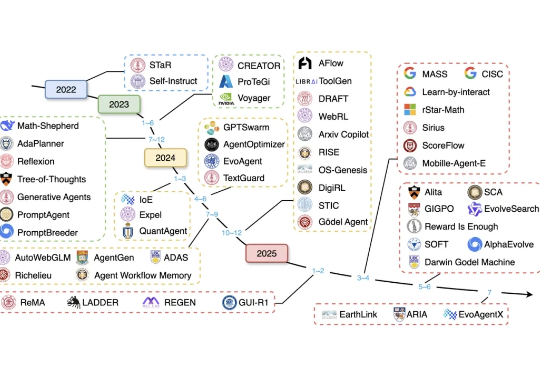
Agent狂欢下的冷思考:为什么说Data&AI数据基础设施,才是AI时代Infra新范式年初,DeepSeek 前脚带来模型在推理能力上的大幅提升,Manus 后脚就在全球范围内描绘了一幅通用 Agent 的蓝图。新的范本里,Agent 不再止步于答疑解惑的「镶边」角色,开始变得主动,拆解分析需求、调用工具、执行任务,最终解决问题……
来自主题: AI资讯
7966 点击 2025-08-14 09:40