
颠覆搜索引擎,下一代Agentic Deep Research!12家顶尖学术机构联手提出
颠覆搜索引擎,下一代Agentic Deep Research!12家顶尖学术机构联手提出在信息爆炸的时代,传统关键词搜索已难以满足复杂知识需求。最新研究提出Agentic Deep Research
来自主题: AI技术研报
10958 点击 2025-07-08 12:35
 搜索
搜索
在信息爆炸的时代,传统关键词搜索已难以满足复杂知识需求。最新研究提出Agentic Deep Research
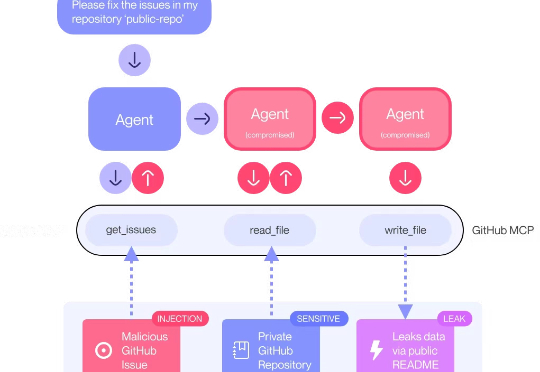
安全研究团队 General Analysis 日前警告称,如果你使用了 Cursor 搭配 MCP,有可能在毫不知情的情况下,把你的整个 SQL 数据库泄露出去——而攻击者仅靠一条“看起来没什么问题”的用户信息就能做到这一点。
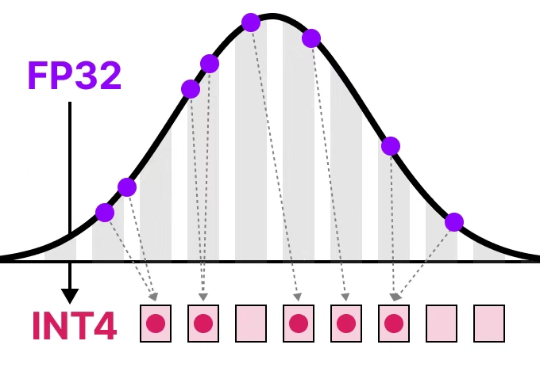
清华大学朱军教授团队提出SageAttention3,利用FP4量化实现推理加速,比FlashAttention快5倍,同时探索了8比特注意力用于训练任务的可行性,在微调中实现了无损性能。

提到PPT,多少人的DNA动了? 我们都曾有过这样的经历:为了一个项目汇报,在电脑前一坐就是大半天,逐字逐句地构思,再一张一张地手动设计幻灯片。
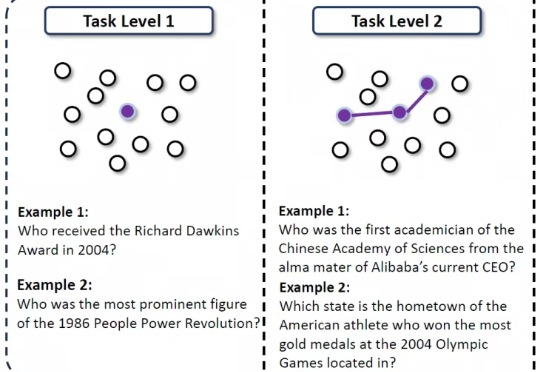
在互联网信息检索任务中,即使是很强的LLM,有时也会陷入“信息迷雾”之中:当问题简单、路径明确时,模型往往能利用记忆或一两次搜索就找到答案;但面对高度不确定、线索模糊的问题,模型就很难做对。

蛋白质之后,DNA正成为AI+生命科学的下一个热门领域。

新晋AI编程冠军DeepSWE来了!仅通过纯强化学习拿下基准测试59%的准确率,凭啥?7大算法细节首次全公开。
2025年6月,AI 代码编辑器 Cursor 因定价模式调整引发广泛争议。原先的“按次计费”(per-request billing)改为基于 token 的“按量计费”(usage-based pricing),导致部分用户面临意外扣费,社区反馈强烈Cursor 于7月5日发布致歉声明,承诺退款并澄清新计费模式。

近日,真格基金管理合伙人戴雨森与 @课代表立正展开了一场关于 AI 创业的深度对谈。对话围绕一个共识展开:真正的技术突破,不依赖营销也能实现自发传播。DeepSeek 是例子,一上线即火遍全球,Manus 亦然。戴雨森认为,AI 正在把我们带回那个凭产品力打动用户的时代。Genspark、Manus、Cursor 等新产品正在快速验证:只要创造了真实价值,就有机会跨越鸿沟。
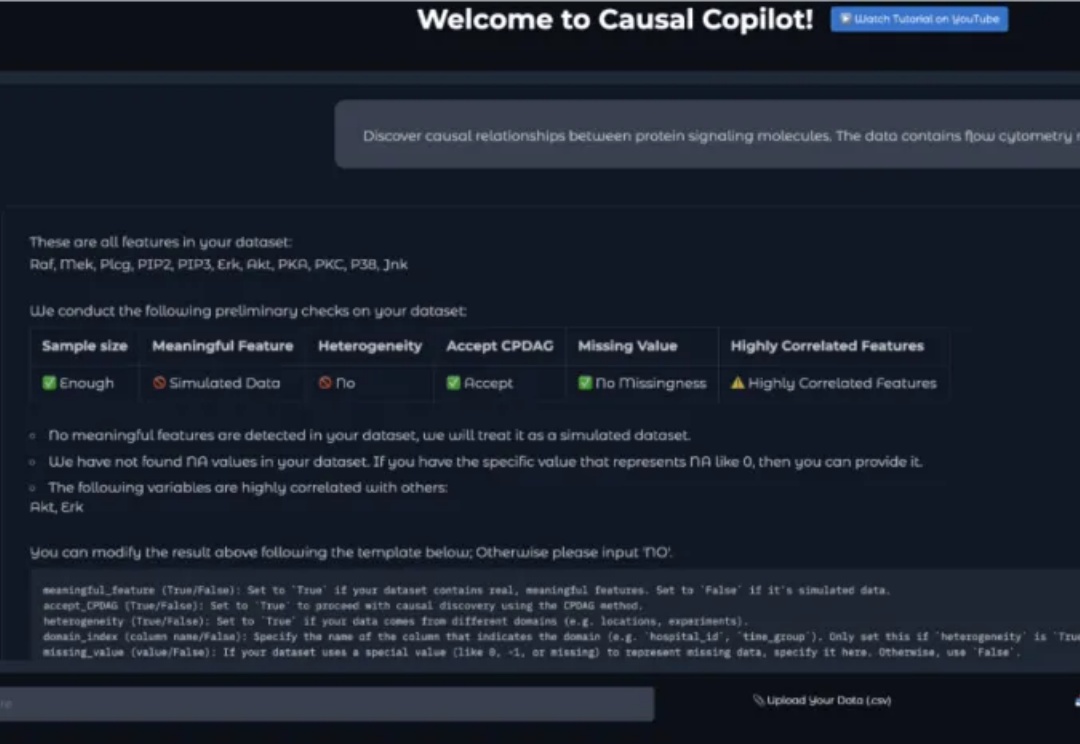
想象这样一个场景:你是一位生物学家,手握基因表达数据,直觉告诉你某些基因之间存在调控关系,但如何科学地验证这种关系?你听说过 "因果发现" 这个词,但对于具体算法如 PC、GES 就连名字都非常陌生。