降维打击Cursor!Augment正在抢走中级程序员的饭碗...
降维打击Cursor!Augment正在抢走中级程序员的饭碗...大家好,我是袋鼠帝 最近我发现好几个AI交流群炸锅了 起因是一款AI编程工具,大家聊得热火朝天。这款AI编程工具叫:Augment Code,它的slogen是更好的上下文、更好的Agent、更好的代码
来自主题: AI资讯
11514 点击 2025-06-23 12:02
 搜索
搜索
大家好,我是袋鼠帝 最近我发现好几个AI交流群炸锅了 起因是一款AI编程工具,大家聊得热火朝天。这款AI编程工具叫:Augment Code,它的slogen是更好的上下文、更好的Agent、更好的代码
让产品团队共享设计语言,以构建可用、智能和安全的Gen AI体验

马斯克最新YC创业学校演讲,AI将于今年或明年达到超级智能,人类正处于智能大爆炸的黎明。
AI也会“闹自杀”了?
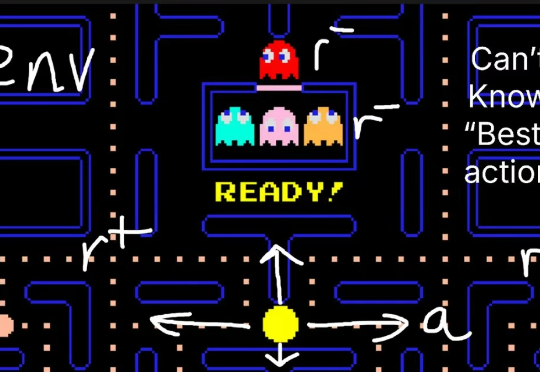
强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。
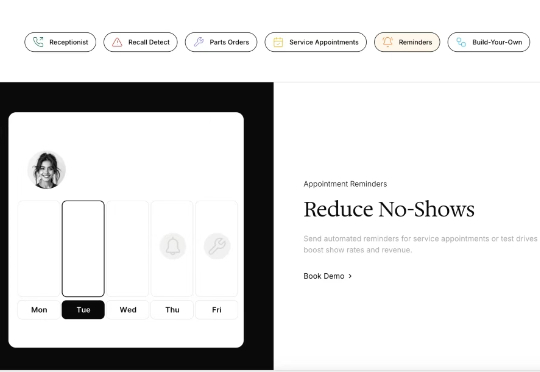
你能想象一个汽车经销商每天漏接45%电话的场景吗?这意味着几乎一半想要预约保养、询问配件或购车咨询的客户都被直接晾在了一边。
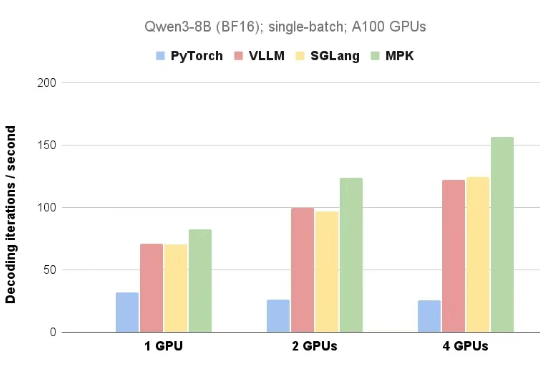
在 AI 领域,英伟达开发的 CUDA 是驱动大语言模型(LLM)训练和推理的核心计算引擎。

一个融合真实地理空间与AI生成技术的开放世界模拟平台,由Genesis物理引擎驱动,支持人类与机器人在社区中共同互动、成长与演化。
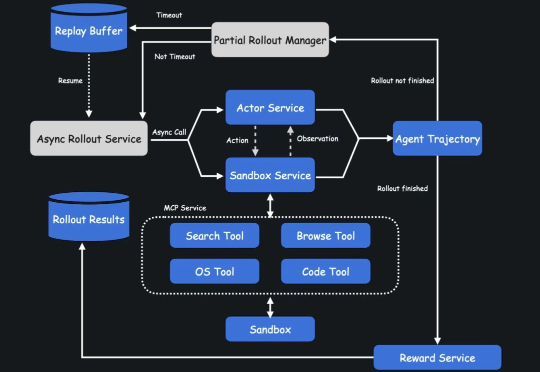
这款 Agent 擅长多轮搜索和推理,平均每项任务执行 23 个推理步骤,访问超过 200 个网址。它是基于 Kimi k 系列模型的内部版本构建,并完全通过端到端智能体强化学习进行训练,也是国内少有的基于自研模型打造的 Agent。
嘿,大家好!这里是一个专注于前沿AI和智能体的频道~