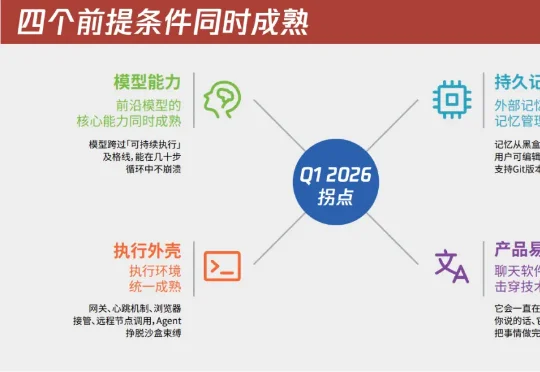
2026年第一季度,AI Agent完成了它的成人礼|2026 Q1 AI趋势白皮书
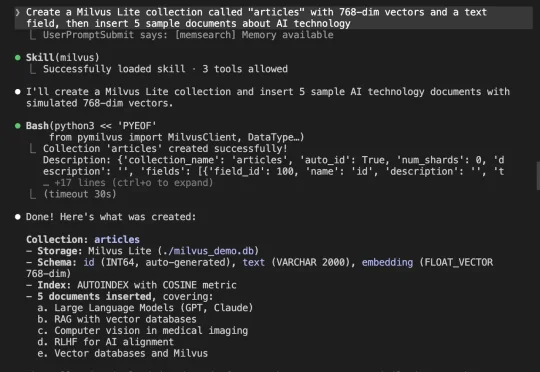
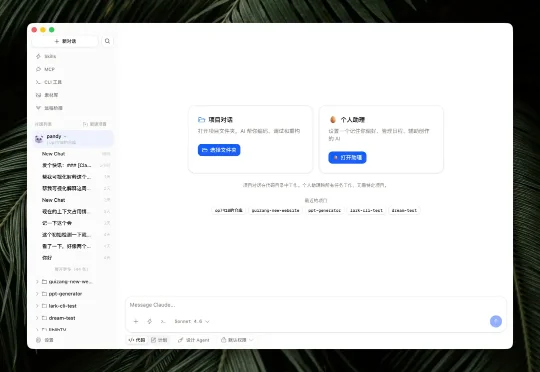
2026年第一季度,AI Agent完成了它的成人礼|2026 Q1 AI趋势白皮书2026 年第一季度,它和另外四种完全不同的 Agent 产品形态在同一个窗口期同时冒了出来。OpenClaw 走个人助理、Cowork 走办公协作、Codex App 走长程工程任务、Perplexity Computer 走统一工作站、腾讯云 ADP 走企业平台。
来自主题: AI技术研报
8131 点击 2026-04-10 15:59