
一句话爆改三维场景!斯坦福吴佳俊团队新作:场景语言,智能补全文本到3D的场景理解
一句话爆改三维场景!斯坦福吴佳俊团队新作:场景语言,智能补全文本到3D的场景理解从文字生成三维世界的场景有多难?
来自主题: AI技术研报
9537 点击 2024-11-13 16:21
 搜索
搜索
从文字生成三维世界的场景有多难?
11月11日,谷歌推出了一款名为“Learn About” 的实验性的新 AI 工具,它不同于此前的聊天机器人,如 Gemini 和 ChatGPT。

本期AGI路线图中关键节点:Figure 02、Optimus Gen-2、宇树G1、傅利叶GR-2、众擎SE01、BVS、WonderWorld、ReKep、DrEureka、DeepMind足球机器人、腾讯「小五」、达芬奇AI机器人、Project GR00T、LeRobot。

这可能是最懂 AI 产品的两位 PM 之间的对谈。Kevin Weil,OpenAI CPO(首席产品官),之前曾是 Instagram、Twitter 的产品副总裁。Mike Kreiger,Anthropic CPO,曾担任 Instagram 的联合创始人、CTO。
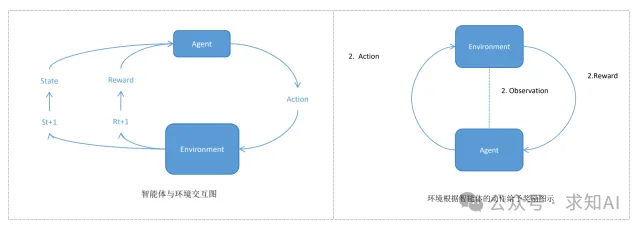
强化学习中的核心概念是智能体(Agent)和环境(Environment)之间的交互。智能体通过观察环境的状态,选择动作来改变环境,环境根据动作反馈出奖励和新的状态。

生成式人工智能GenAI是否存在泡沫?这个问题日益成为业界热议的焦点。目前,全球对AI基础设施的投资已到了癫狂的成千上万亿美元的规模,然而大模型如何实现盈利却始终没有一个明确的答案。

空间智能版ImageNet来了,来自斯坦福李飞飞吴佳俊团队!
11月8日,社交媒体上有博主爆料,谷歌正准备推出一款新型号:Gemini 2.0。
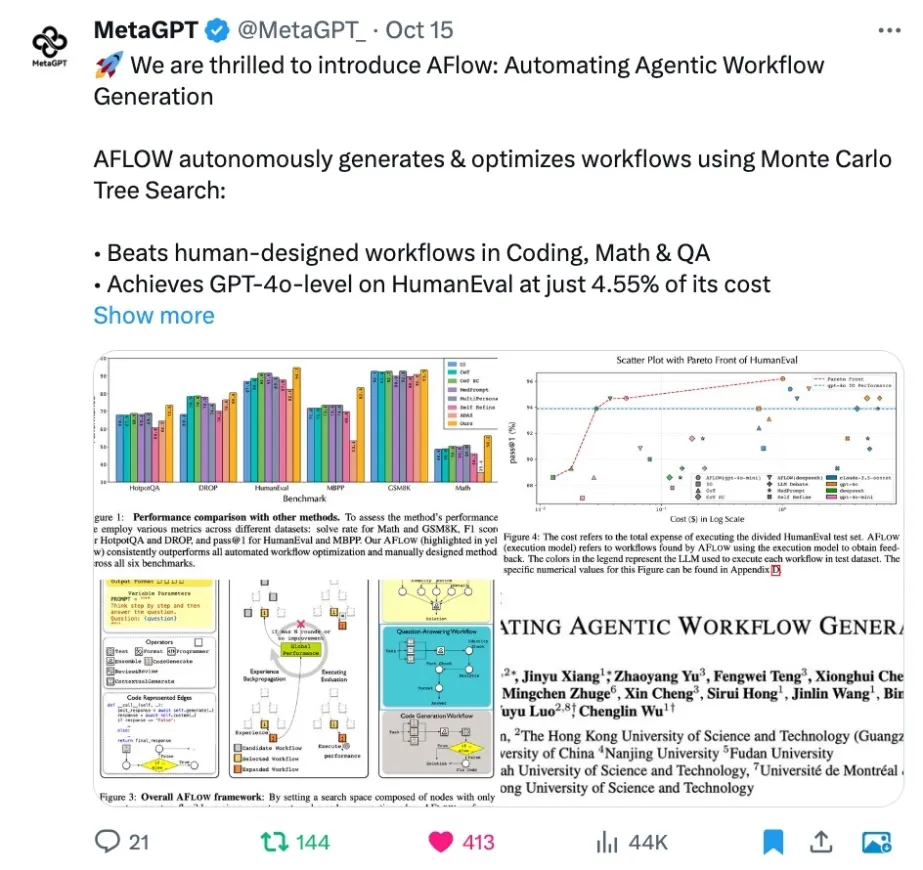
对于 LLM 从业者来说,让 LLM 落地应用并发挥作用需要手动构建并反复调试 Agentic Workflow,这无疑是个繁琐过程,一遍遍修改相似的代码,调试 prompt,手动执行测试并观察效果,并且换个 LLM 可能就会失效,有高昂的人力成本。许多公司甚至专职招聘 Prompt Engineer 来完成这一工作。
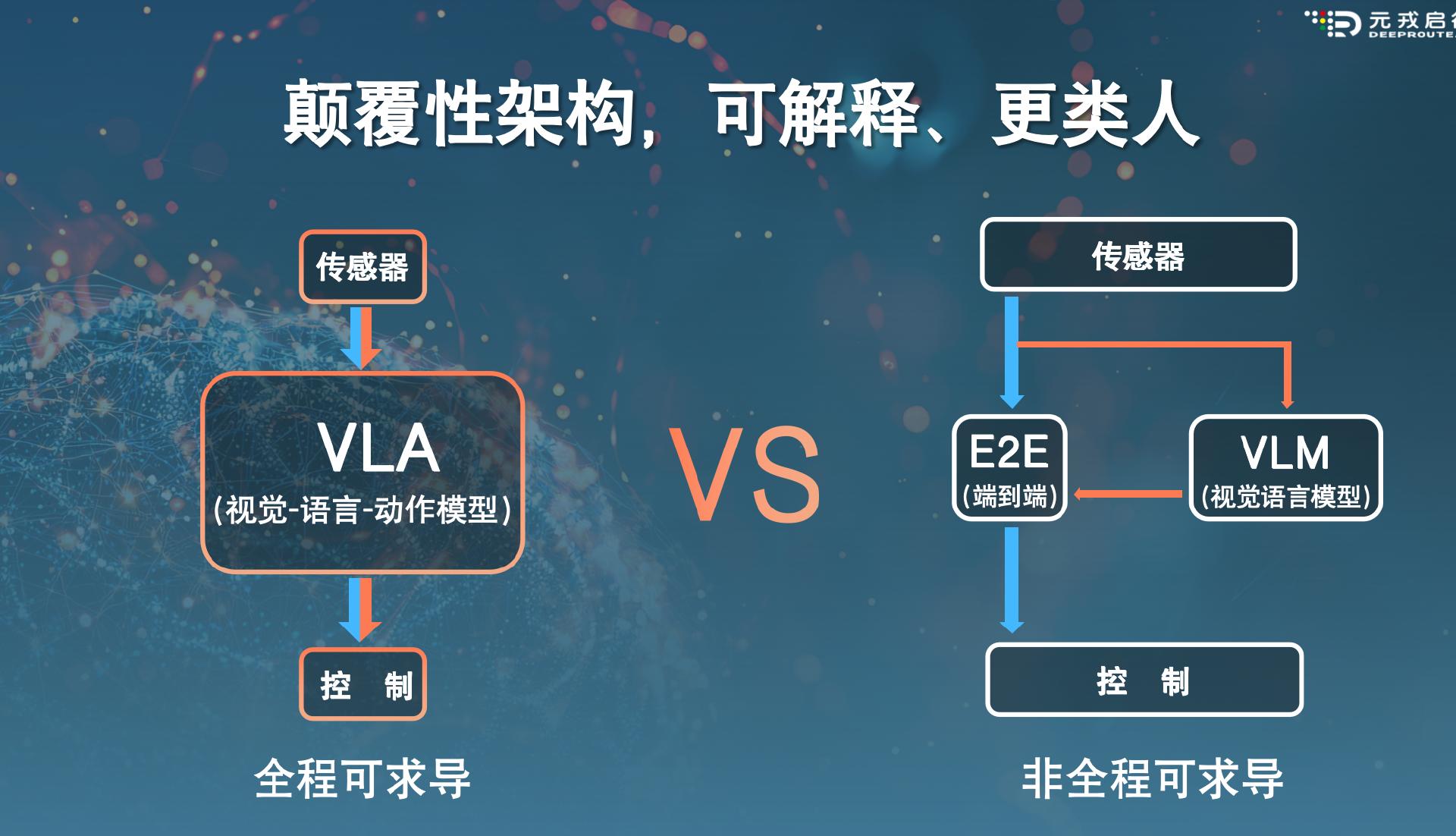
近期,智驾行业出现了一个融合了视觉、语言和动作的多模态大模型范式——VLA(Vision-Language-Action Model,即视觉-语言-动作模型),拥有更高的场景推理能力与泛化能力。不少智驾人士都将VLA视为当下“端到端”方案的2.0版本。