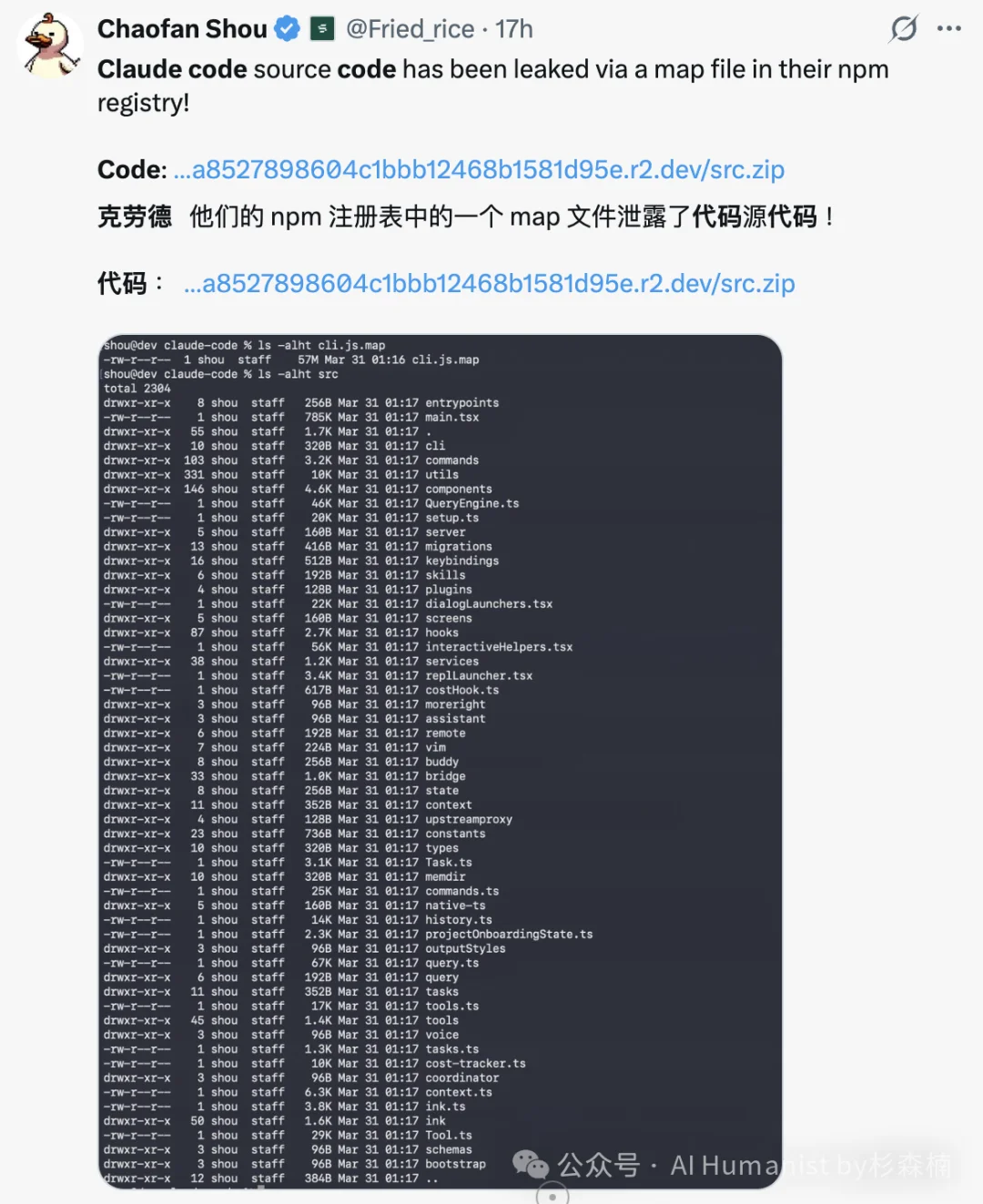
Claude Code 大泄密!万字保姆级别部署教程,Cache命中系统全公开了?
Claude Code 大泄密!万字保姆级别部署教程,Cache命中系统全公开了?因为 Claude Code 就是目前最顶级的 Agent 系统,没有之一。我敢说,昨晚有大量厂商的技术团队通宵在扒这份源码,疯狂学习里面的架构设计,拿来改进自家产品。下面说说我是怎么部署的,流程其实很简单。
来自主题: AI资讯
9899 点击 2026-04-01 13:26
 搜索
搜索
因为 Claude Code 就是目前最顶级的 Agent 系统,没有之一。我敢说,昨晚有大量厂商的技术团队通宵在扒这份源码,疯狂学习里面的架构设计,拿来改进自家产品。下面说说我是怎么部署的,流程其实很简单。

Claude Code 源码泄露为业界一下子打开了 Agent 进化的大门。

给AI装人格,是产品包装,还是技术必然?

3 月 16 日,在刚刚结束的 NVIDIA GTC 2026 大会上,黄仁勋在长达三小时的 Keynote 演讲中发布了 NVIDIA Agent Toolkit 和 AI-Q 开放智能体蓝图,将 AI Agent 定位为下一个重大前沿。
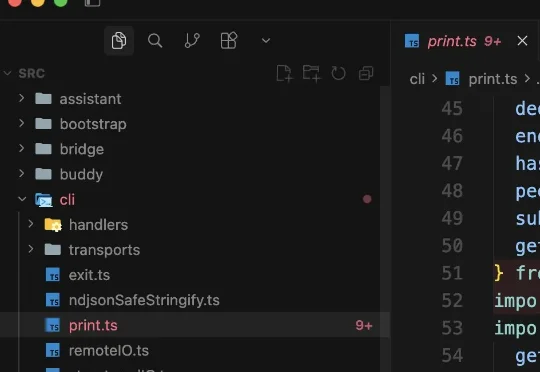
对于 Anthropic 而言,这是继前几天 Mythos 模型文档外泄后的又一次严重 OpSec事故。但对于整个大模型应用层的开发者和行业研究者来说,这份源码却是一份毫无保留的、价值极高的前沿 AI Agent 工程架构白皮书。

这两天,我发现微信里悄悄接入了一个全新的 Agent 入口:WorkBuddy 微信小程序。
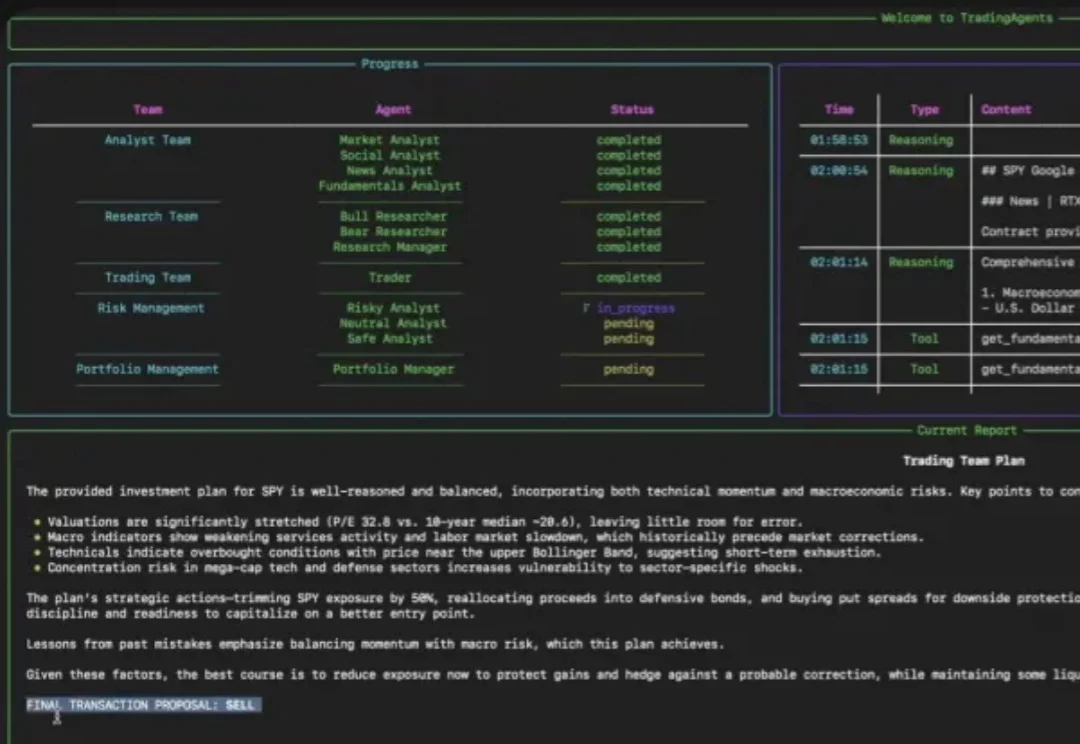
好家伙,投资版龙虾也来了。还是GitHub开源项目里最近高热高赞的那种。
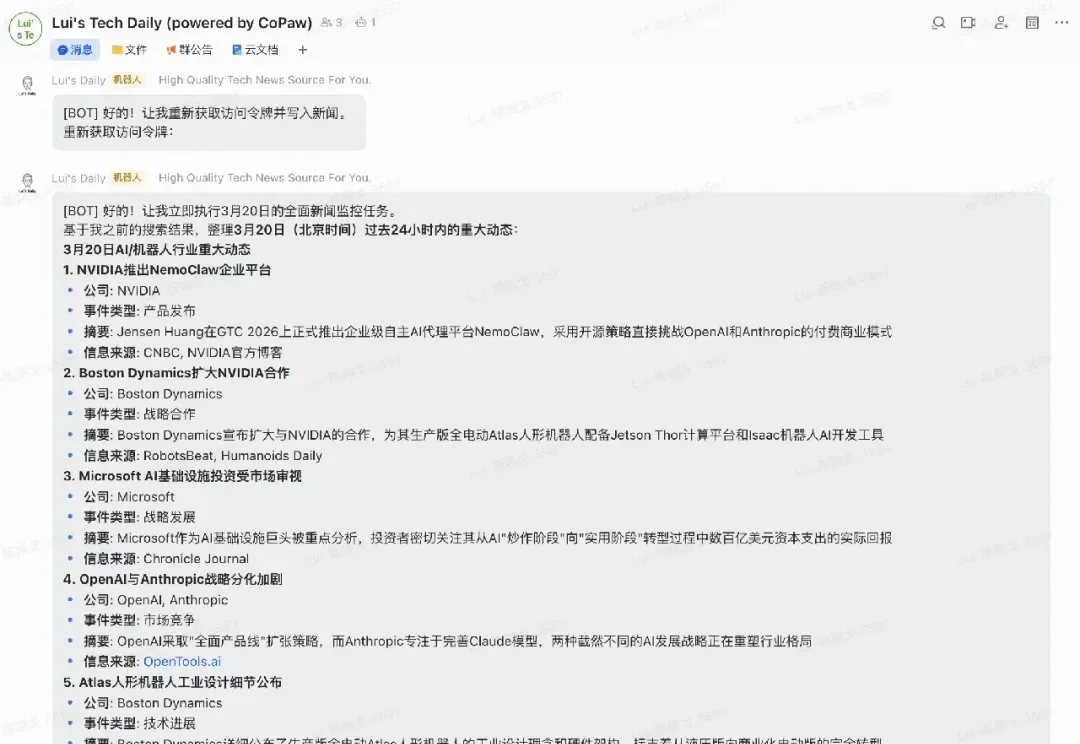
过去几周,国内各大厂纷纷推出了自己的“龙虾”,而阿里云在这条赛道上的动作尤其引人注目。2026 年,阿里云通义实验室旗下 AgentScope 团队开源了 CoPaw,一款本地 / 云端双部署的个人 AI 助理,主打“全域接入、隐私可控、主动干活”。
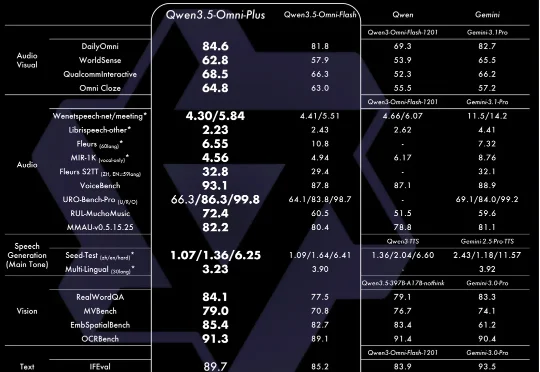
阿里刚刚发布了最新一代全模态大模型 Qwen3.5-Omni,在通用音频理解、推理、翻译和对话等维度,已全面超越 Gemini 3.1 Pro。所谓全模态,在于它拥有了接近人类的“感官”。它能听、能看、能说、能写。

本文作者 José Maria Macedo 是加密行业老牌研究机构 Delphi Digital 的联合创始人,也是 Delphi Ventures 的创始合伙人。Delphi 的客户包括 Polychain、Pantera、Ark Invest 等顶级基金,最近还专门开设了 AI 研究线 Delphi Intelligence。