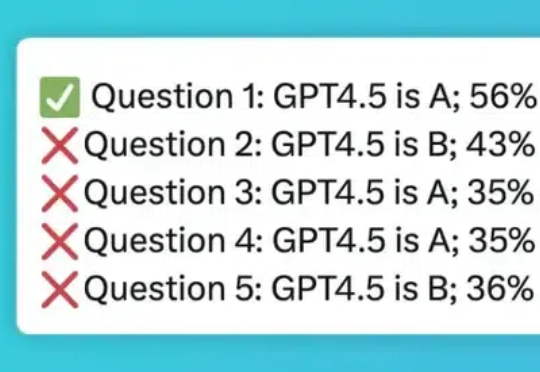
万轮实测:GPT-4.5 不如 GPT-4
万轮实测:GPT-4.5 不如 GPT-4我先给大家道个歉,上一篇讲的不太对:《GPT-4.5 一手实测:垃圾》,是我喷得保守了,觉得 GPT-4.5 只是贵&慢,但模型总归是素质在线。 没想到,经过实际数万轮实测:GPT-4.5 不如 GPT-4
来自主题: AI技术研报
9154 点击 2025-03-01 15:00
 搜索
搜索
我先给大家道个歉,上一篇讲的不太对:《GPT-4.5 一手实测:垃圾》,是我喷得保守了,觉得 GPT-4.5 只是贵&慢,但模型总归是素质在线。 没想到,经过实际数万轮实测:GPT-4.5 不如 GPT-4

几乎所有人都已经发现,我们正生活在一场前所未有的信息革命之中。
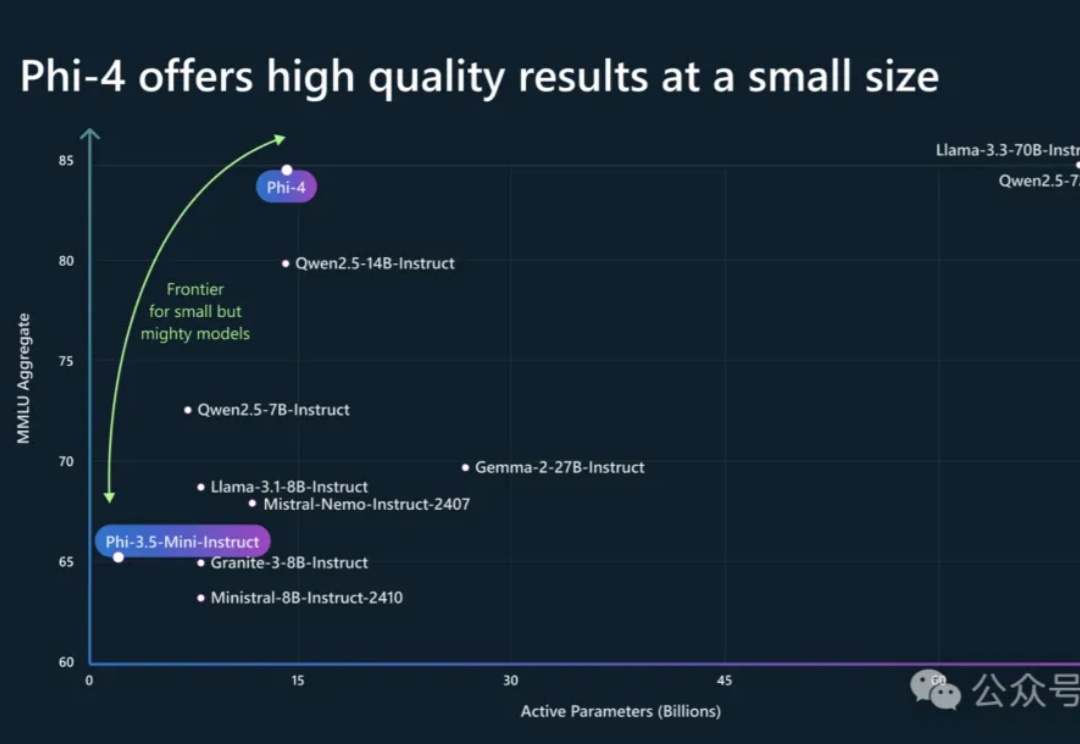
Phi-4系列模型上新了!56亿参数Phi-4-multimodal集语音、视觉、文本多模态于一体,读图推理性能碾压GPT-4o;另一款38亿参数Phi-4-mini在推理、数学、编程等任务中超越了参数更大的LLM,支持128K token上下文。

GPT-4.5正式发布,号称OpenAI最大和最好的聊天模型。

OpenAI的重磅炸弹GPT-4.5,刚刚如期上线了!它并不是推理模型,但是规模最大、知识最丰富,最鲜明的特点就是情商高、很类人。Pro版用户和付费开发者已经能用了,但token定价有点离谱。
动辄百亿、千亿参数的大模型正在一路狂奔,但「小而美」的模型也在闪闪发光。

谷歌Gemini 2.0代码助手免费,每月18万次代码补全,支持超大上下文窗口。微软Copilot语音与深度思考功能,同样免费!OpenAI也免费推出了GPT-4o mini高级语音模式。
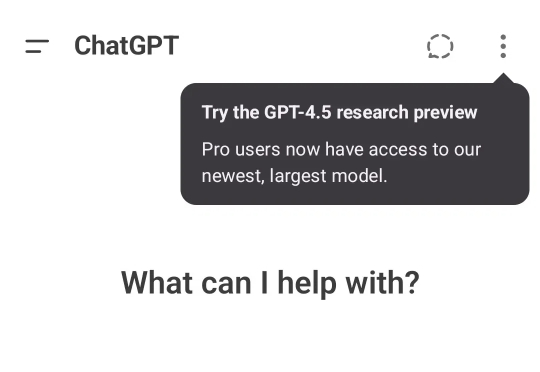
嚯,万众期待的GPT-4.5,本周就要空降发布?!部分用户的ChatGPT安卓版本(1.2025.056 测试版)上,已经出现了“GPT-4.5研究预览(GPT-4.5 research preview)”的字样。
近年来, Scaling Up 指导下的 AI 基础模型取得了多项突破。从早期的 AlexNet、BERT 到如今的 GPT-4,模型规模从数百万参数扩展到数千亿参数,显著提升了 AI 的语言理解和生成等能力。然而,随着模型规模的不断扩大,AI 基础模型的发展也面临瓶颈:高质量数据的获取和处理成本越来越高,单纯依靠 Scaling Up 已难以持续推动 AI 基础模型的进步。

OpenAI刚刚发布SWE-Lancer编码基准测试,直接让AI模型挑战真实外包任务!这些任务总价值高达100万美元。有趣的是,测试结果显示,Anthropic的Claude 3.5 Sonnet在「赚钱」能力上竟然超越了OpenAI自家的GPT-4o和o1模型。