OpenAI o1惊现自我意识?陶哲轩实测大受震撼,门萨智商100夺模型榜首
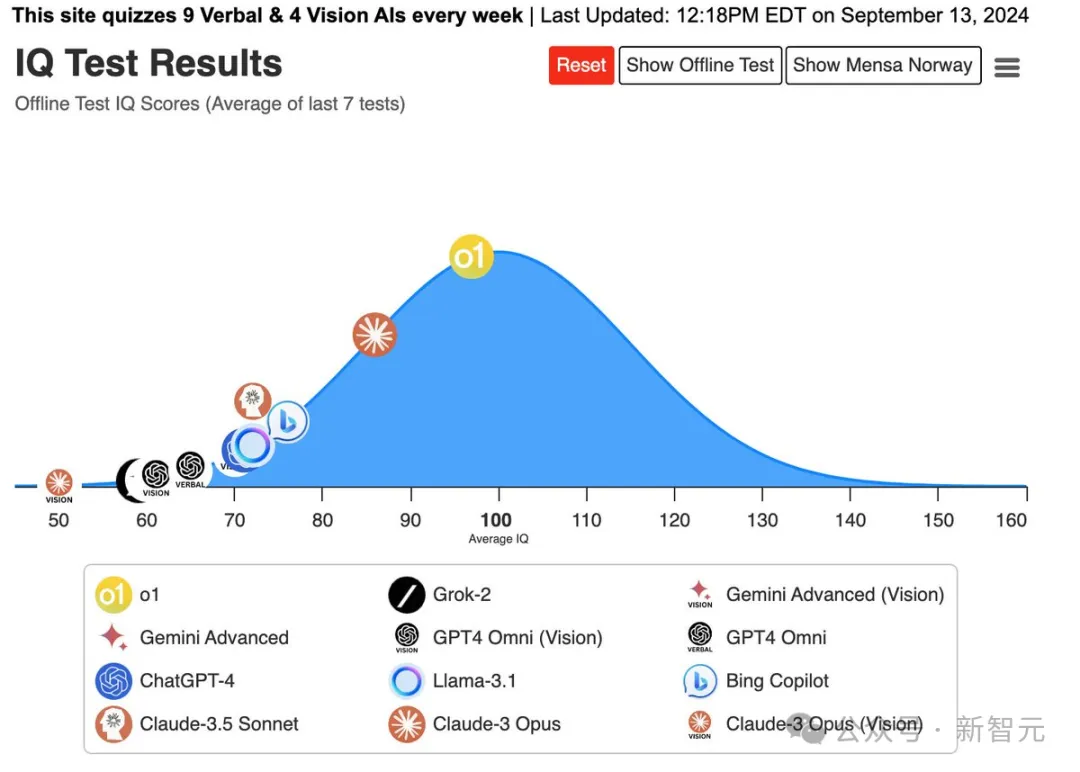
OpenAI o1惊现自我意识?陶哲轩实测大受震撼,门萨智商100夺模型榜首OpenAI o1,在IQ测试中拿到了第一名!大佬Maxim Lott,给o1、Claude-3 Opus、Gemini、GPT-4、Grok-2、Llama-3.1等进行了智商测试,结果表明,o1稳居第一名。
来自主题: AI资讯
7083 点击 2024-09-14 16:02
 搜索
搜索
OpenAI o1,在IQ测试中拿到了第一名!大佬Maxim Lott,给o1、Claude-3 Opus、Gemini、GPT-4、Grok-2、Llama-3.1等进行了智商测试,结果表明,o1稳居第一名。

鹅厂新一代旗舰大模型混元Turbo技术报告首次曝光。模型采用全新分层异构的MoE架构,总参数达万亿级别,性能仅次于GPT-4o,位列国内第一梯队。

AI大行其道的时代,网络安全正面临前所未有的威胁。
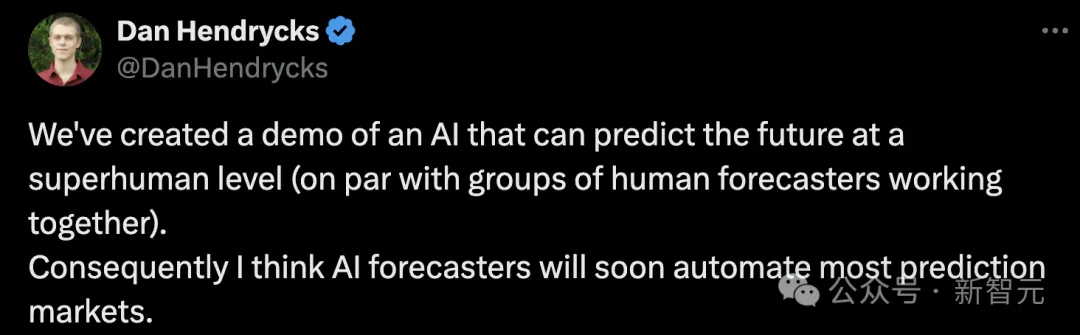
AI的能力终于癫成了和这个世界匹配的样子——来自UCB等机构的研究者们用GPT-4o,开发出了一个「AI预言家」。

本文第一作者为 Chuanyang Jin (金川杨),本科毕业于纽约大学,即将前往 JHU 读博。本文为他本科期间在 MIT 访问时的工作,他是最年轻的杰出论文奖获得者之一。
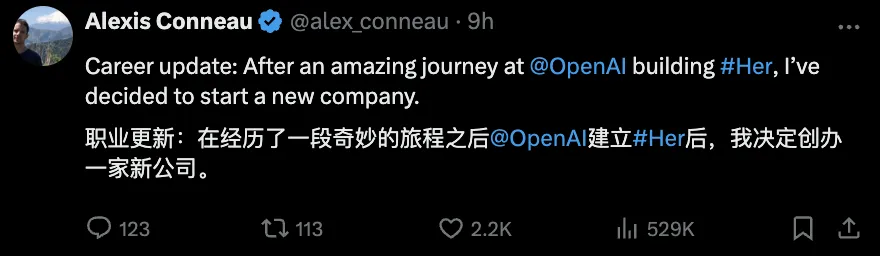
在OpenAI最早提出打造「Her」想法的的人,也离职创业了。
更好的效果,更低的价格,听起来是不是像梦呓?

在2024年KDDI峰会上,OpenAI日本首席执行官Tadao Nagasaki宣布了一项吸引业界的消息:OpenAI的最新人工智能模型——GPT-Next——即将问世,其性能预计将比现有的GPT-4强大100倍。
继OpenAI在5月发布会上展示「期货」GPT-4o的语音功能后,「AI语音助手」类的产品又成为了硅谷科技巨头的必争之地。

由AI生成的内容渐渐充斥了互联网。